
Want to learn about #MongoDB data modeling, and some pitfalls to avoid? Live stream coming up in about 30 mins!
https://twitter.com/Lauren_Schaefer/status/1441054967335378945
LOL! A dramatic re-enactment of what happened. ;) @Lauren_Schaefer's boss was compiling YouTube stats manually into a spreadsheet, and was getting grumpy about it, making this face: 
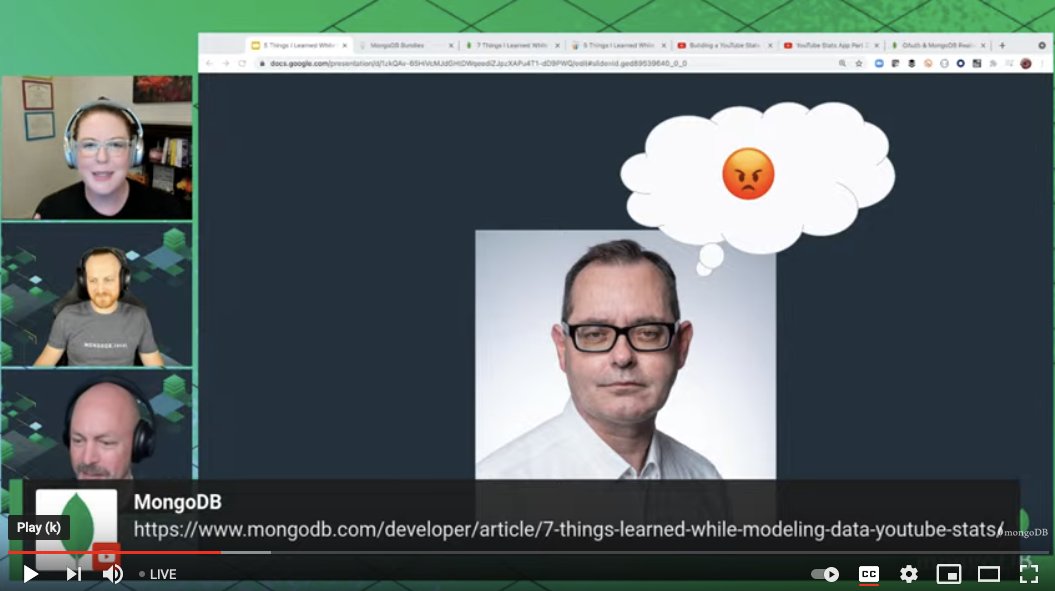
Solution: What if we build an app that uses the YouTube API to automate pulling feed data into #MongoDB? That'd make @jdrumgoole happy! 🤩

The basic architecture: ingest from the YouTube API => store data in a #MongoDB Atlas database => display results in #MongoDB Charts.
* mongodb.com/cloud/atlas
* mongodb.com/products/charts
* mongodb.com/cloud/atlas
* mongodb.com/products/charts
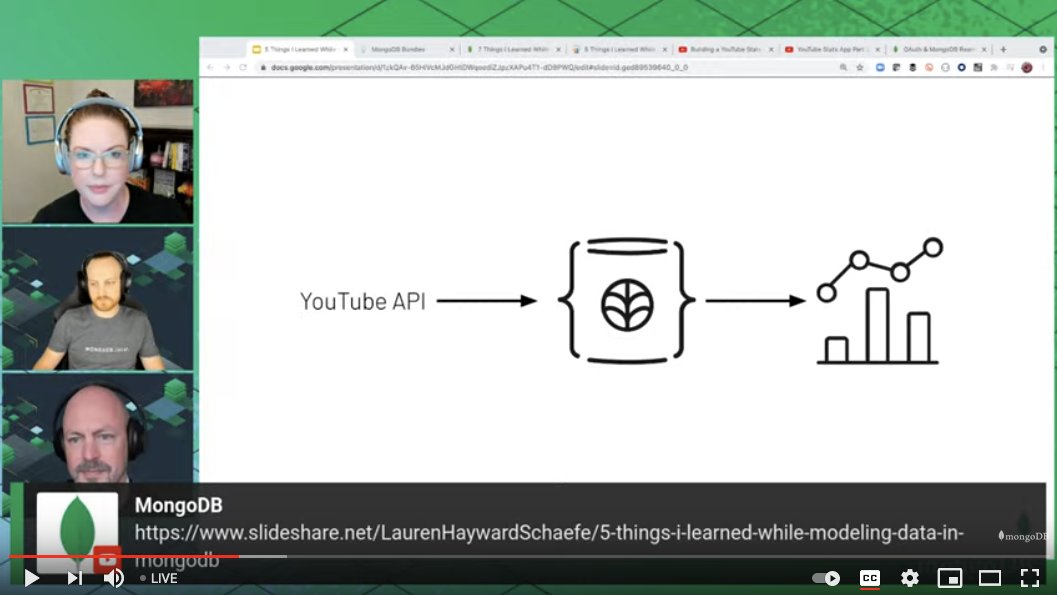
Here's the app. It's a dashboard containing info like total number of videos published, number of views/likes/dislikes, etc. tracked over time. Data can be grouped by quarter, and be filtered by department, so we can see how many videos DevRel vs. Marketing has done, for example.



Now there's a brief diversion from the presentation to answer an audience question about when 1:1 vs. 1:Many vs. Many:Many relationships are appropriate in #MongoDB.
1:1 doesn't really exist in #MongoDB. As a general rule, all related data should be stored together in a single document.
Exception is if one attribute is MASSIVE (e.g. the entire contents of a book) it might make sense to store that in a separate document for performance.
Exception is if one attribute is MASSIVE (e.g. the entire contents of a book) it might make sense to store that in a separate document for performance.
1:Many, there's some nuance. The general rule is "data that gets accessed together, stays together."
For example, a blog post might be stored with its comments as sub-documents, because they are frequently presented together.
For example, a blog post might be stored with its comments as sub-documents, because they are frequently presented together.
OTOH, if you're like YouTube, for example, and the comments on a particular video might number into the *thousands*, and you can eventually max out #MongoDB's document size (16MB: docs.mongodb.com/manual/core/do…). In this case, it's better to make Comments its own separate collection.
One other consideration: should the IDs that form parent:child relationships be stored on the "parent" side, the "child" side, or both? (Again, seems to depend on how you are planning to query it.)
Some other great #MongoDB resources on this general topic:
* Schema Design Best Practices: mongodb.com/developer/arti…
* Schema Patterns: mongodb.com/blog/post/buil…
* Schema Anti-Patterns: mongodb.com/developer/arti…
* Schema Design Best Practices: mongodb.com/developer/arti…
* Schema Patterns: mongodb.com/blog/post/buil…
* Schema Anti-Patterns: mongodb.com/developer/arti…
Ok, back to the topic at hand! Here are three key terms all #MongoDB practitioners should know.

First up: Documents. Documents store data in key/value pairs, which start and end with curly braces. Roughly comparable to a "row" in a "table," in relational database speak.

Next: Collections. A group of related documents, essentially the same as a "table."

Finally, Database. This contains a group of collections (a collection of collections? ;)), which maps well to the concept same concept in relational-speak.

So, how was the data modeled?
(Bear in mind, team had only 2 weeks to get to MVP, so they chose to start with a basic data model—vs. spending time devising the ultimate, pristine one—and refactor as needed. This malleable modeling capability is a core strength of #MongoDB.)
(Bear in mind, team had only 2 weeks to get to MVP, so they chose to start with a basic data model—vs. spending time devising the ultimate, pristine one—and refactor as needed. This malleable modeling capability is a core strength of #MongoDB.)

The team ended up with two collections:
- youtube_videos: stores metadata about each video on the #MongoDB YouTube channel
- youtube_stats: stores the daily views, likes, etc. of each video
- youtube_videos: stores metadata about each video on the #MongoDB YouTube channel
- youtube_stats: stores the daily views, likes, etc. of each video

A sample youtube_videos document looks like this.
- _id: YouTube's unique ID (stored in #MongoDB's _id field for parity)
- isDA: Custom field for whether video was done by someone on our team. (manually populated)
- snippet: Sub-document for data coming back from YouTube's API
- _id: YouTube's unique ID (stored in #MongoDB's _id field for parity)
- isDA: Custom field for whether video was done by someone on our team. (manually populated)
- snippet: Sub-document for data coming back from YouTube's API

How is the collection populated?
Each day, a scheduled trigger runs, calls a @realm serverless function, which calls the YouTube Playlist Items API. API returns data about all videos on the #MongoDB YouTube channel, the function stores that data in the youtube_videos collection.
Each day, a scheduled trigger runs, calls a @realm serverless function, which calls the YouTube Playlist Items API. API returns data about all videos on the #MongoDB YouTube channel, the function stores that data in the youtube_videos collection.

How about youtube_stats? Used the "bucket" pattern here (mongodb.com/blog/post/buil…) to group data by month.
- _id: A composite key of YouTube Video ID+Year+Month.
- stats: An array; each item contains stats for a 24 hour period (Dec 1, Dec 2...)
- _id: A composite key of YouTube Video ID+Year+Month.
- stats: An array; each item contains stats for a 24 hour period (Dec 1, Dec 2...)

youtube_stats is populated in a similar manner: scheduled trigger => function call => retrieve YouTube video IDs from youtube_videos collection => call YouTube Reports API to get detailed stats on each video => store result to youtube_stats collection.

One great new feature of #MongoDB 5.0: Time Series Collections (docs.mongodb.com/manual/core/ti…)
Had this feature existed at the time the team built this project, they could've used it vs. bucketing data on their own, and had a much simpler data model!
Had this feature existed at the time the team built this project, they could've used it vs. bucketing data on their own, and had a much simpler data model!
So, what were the lessons learned from taking this approach?

#1: Duplicating data is scary—even for those of us who have been coaching others to do so.
Despite @Lauren_Schaefer's signature catchphrase of "Data that is accessed together should be stored together," she still opted for two collections, not one.
Despite @Lauren_Schaefer's signature catchphrase of "Data that is accessed together should be stored together," she still opted for two collections, not one.

Why?
1. App required two API calls: one for videos, one for stats. Seemed natural as two collections.
2. Prototype. Didn't yet know how data would be presented; didn't know yet what data would be accessed together.
3. Duplicated data needs to be kept in sync; cut out complexity.
1. App required two API calls: one for videos, one for stats. Seemed natural as two collections.
2. Prototype. Didn't yet know how data would be presented; didn't know yet what data would be accessed together.
3. Duplicated data needs to be kept in sync; cut out complexity.

(Ok it is now Date Night™️ … I shall pick this up again tomorrow. :))
The data model allows easy querying of stats information e.g. likes, views
But, to show information about video associated with the stats (e.g. video name), need to use $lookup to join collections. docs.mongodb.com/manual/referen…
Best practices suggest limiting $lookup for performance.
But, to show information about video associated with the stats (e.g. video name), need to use $lookup to join collections. docs.mongodb.com/manual/referen…
Best practices suggest limiting $lookup for performance.

This decision was a trade-off between ease of development by avoiding data duplication and application performance impact caused by splitting data. In the end, ease of development won.
(Fair enough, esp. for a quick 2-week MVP project!)
(Fair enough, esp. for a quick 2-week MVP project!)
Now that we know the video's name and publish date are needed alongside stats, could use "Extended Reference" pattern.
Duplicate some video information in youtube_stats, use Atlas trigger (or Change Stream) to watch for changes in youtube_videos, push changes to youtube_stats.
Duplicate some video information in youtube_stats, use Atlas trigger (or Change Stream) to watch for changes in youtube_videos, push changes to youtube_stats.

First point, summarized. As long as you know which data needs to be duplicated, and have a mechanism set up to ensure data consistency, duplicating not as scary!
* Triggers: docs.atlas.mongodb.com/triggers/
* Change Streams: docs.mongodb.com/manual/changeS…
* Transactions: docs.mongodb.com/manual/core/tr…
* Triggers: docs.atlas.mongodb.com/triggers/
* Change Streams: docs.mongodb.com/manual/changeS…
* Transactions: docs.mongodb.com/manual/core/tr…

Another brief interlude to answer audience question about Time Series Collections (docs.mongodb.com/manual/core/ti…) and metaField.
A TS Collection stores series of measurements that change over time. metaField stores where data comes from. Just a sub-document; no restrictions on format.
A TS Collection stores series of measurements that change over time. metaField stores where data comes from. Just a sub-document; no restrictions on format.
Similarly, measurements can be stored in whatever structure makes the most sense; no need for them to be restricted to the top level of the document.
To see Time Series in action, check out the demo from the #MongoDB.live 2021 keynote by @judy2k
himself!
To see Time Series in action, check out the demo from the #MongoDB.live 2021 keynote by @judy2k
himself!
Another audience question about keeping duplicated data in sync.
Three methods:
1) Triggers (docs.atlas.mongodb.com/triggers/) for Atlas (DBaaS)
2) Change Streams docs.mongodb.com/manual/changeS… for self-hosted
Both monitor collection for changes, automatically push change to other collection
Three methods:
1) Triggers (docs.atlas.mongodb.com/triggers/) for Atlas (DBaaS)
2) Change Streams docs.mongodb.com/manual/changeS… for self-hosted
Both monitor collection for changes, automatically push change to other collection
3) ACID transactions (mongodb.com/basics/transac…)
This approach automatically pushes the changes to both places at the same time.
This approach automatically pushes the changes to both places at the same time.
Another audience question: How to prevent infinite loops in triggers?
@MBeugnet: "Don't create them." 😂
To clarify: there's no way to prevent infinite loops automatically on the Atlas side, so make sure your trigger has some kind of stop condition (e.g. after 3 loops).
@MBeugnet: "Don't create them." 😂
To clarify: there's no way to prevent infinite loops automatically on the Atlas side, so make sure your trigger has some kind of stop condition (e.g. after 3 loops).
Another audience question: Is there a way to know the performance of an aggregation pipeline?
Yes, with explain plan: docs.mongodb.com/manual/referen… option executionStats. Will break down query by stages to tell you which stage has the performance issue (sort, group...).
Yes, with explain plan: docs.mongodb.com/manual/referen… option executionStats. Will break down query by stages to tell you which stage has the performance issue (sort, group...).
Here's a great talk from Chris Harris, aka "The Query Doctor," from #MongoDB.live last year on optimizing query performance:
(There's also a podcast episode at mongodb.com/developer/podc… if you're more audio inclined.)
(There's also a podcast episode at mongodb.com/developer/podc… if you're more audio inclined.)
Ok, back to lessons learned!
#2: Cleaning data you receive from APIs will make working with data easier.
Can't just dump stuff into the collection and expect everything to work out.
Garbage in, garbage out. :)
#2: Cleaning data you receive from APIs will make working with data easier.
Can't just dump stuff into the collection and expect everything to work out.
Garbage in, garbage out. :)

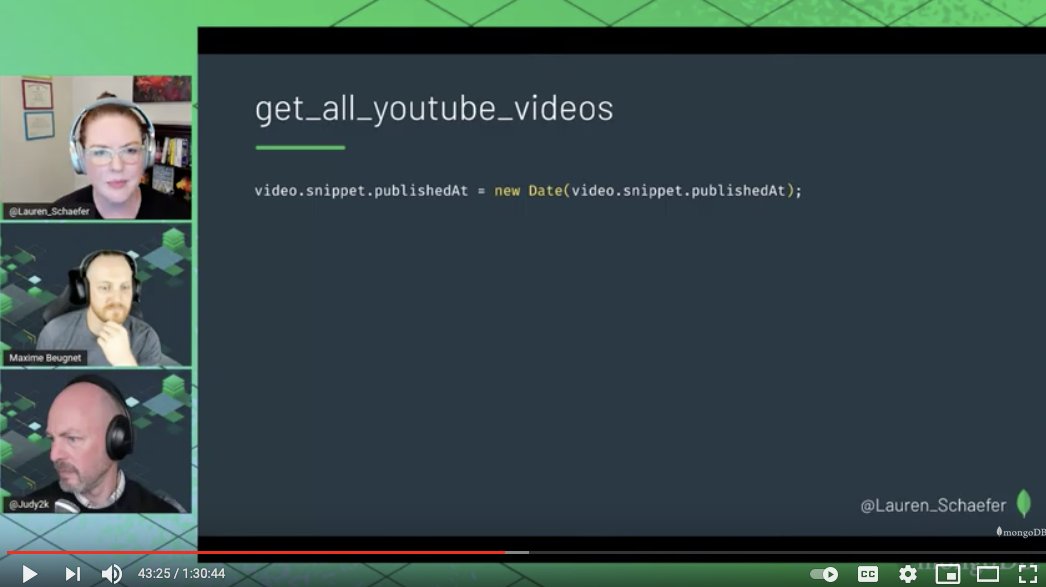
One example: publishedAt field is a *string*, not a date. (Same for "month" and "year" in youtube_stats.)
While you can clean this up on the #MongoDB Charts side, best to fix it at the data level so *all* queries come back consistently.
While you can clean this up on the #MongoDB Charts side, best to fix it at the data level so *all* queries come back consistently.

Here's how to fix it. *Before* storing the data, convert it to the ideal type (in this case, by using the Date method docs.mongodb.com/manual/referen…).
(You can also remodel data before storing to optimize the structure of the incoming data for your use case.)
(You can also remodel data before storing to optimize the structure of the incoming data for your use case.)
Lesson #3: Optimizing for your use case is really hard when you don't fully know what your use case will be.
Team knew they wanted to show YouTube stats on a dashboard. But, didn't know what stats we could pull, or how we want to visualize data.
Team knew they wanted to show YouTube stats on a dashboard. But, didn't know what stats we could pull, or how we want to visualize data.

One core strength of #MonogDB is the ability to rapidly make schema changes as your requirements develop/change.
(Schema versioning pattern mongodb.com/blog/post/buil… helps with this.)
(Schema versioning pattern mongodb.com/blog/post/buil… helps with this.)
One unknown requirement: correlating video publish date to fiscal quarter (e.g. "FY21Q3")
@MBeugnet pulled this off with a fancy Aggregation Pipeline! docs.mongodb.com/manual/core/ag…
But, if calculated as a field in the youtube_stats collection, it's available to Charts OR queries.
@MBeugnet pulled this off with a fancy Aggregation Pipeline! docs.mongodb.com/manual/core/ag…
But, if calculated as a field in the youtube_stats collection, it's available to Charts OR queries.

Takeaways:
* Model data for YOUR use case vs. what's convenient to store/retrieve (do some requirements gathering up front)
* When requirements inevitably change, you can remodel your data easily with #MongoDB's flexible schema.
* Model data for YOUR use case vs. what's convenient to store/retrieve (do some requirements gathering up front)
* When requirements inevitably change, you can remodel your data easily with #MongoDB's flexible schema.

Audience Q: What is $lookup? What does it do?
$lookup (docs.mongodb.com/manual/referen…) is effectively an INNER JOIN, used to group data from collections together on a common field value.
(Not to be confused with $match (docs.mongodb.com/manual/referen…) which filters results by date, name...)
$lookup (docs.mongodb.com/manual/referen…) is effectively an INNER JOIN, used to group data from collections together on a common field value.
(Not to be confused with $match (docs.mongodb.com/manual/referen…) which filters results by date, name...)
How about $facet? docs.mongodb.com/manual/referen…
Let's say you have an online store and want to show how many items of each colour (red, blue...), size (large, small...), etc. you have (e.g. search results)
$group can do one or the other; $facet can compute several groups in parallel.
Let's say you have an online store and want to show how many items of each colour (red, blue...), size (large, small...), etc. you have (e.g. search results)
$group can do one or the other; $facet can compute several groups in parallel.
Lesson #4: There is no "right way" to model your data.
Resist the urge to strive for perfection in your data model; #MongoDB's flexibility means there's no "one" right answer; revisiting your data model as your requirements become more clear is OK!
Resist the urge to strive for perfection in your data model; #MongoDB's flexibility means there's no "one" right answer; revisiting your data model as your requirements become more clear is OK!

Takeaways:
* Don't let the flexibility freak you out; evolve data model as requirements become more clear/change
* Once you feel more confident in choices, schema validation docs.mongodb.com/manual/core/sc… can help lock down part or all of schema (See stream at )
* Don't let the flexibility freak you out; evolve data model as requirements become more clear/change
* Once you feel more confident in choices, schema validation docs.mongodb.com/manual/core/sc… can help lock down part or all of schema (See stream at )
Final lesson! Determine how much you want to tweak your data model based on the ease of working with the data and your performance requirements.
Since there's no "right way" to model data, you'll likely find further ways to optimize data model as you go.
Since there's no "right way" to model data, you'll likely find further ways to optimize data model as you go.

So when is your data model "good enough"? Two key questions to ask yourself and your team:
1. Is the ease of working with the data good enough?
2. Is the performance good enough?
1. Is the ease of working with the data good enough?
2. Is the performance good enough?

For first question, initially the answer was "no," because there had to be work done on the Charts side to get dates into the right format, for example.
Since fixing that, however, yeah! It seems ease of working with data is good enough. Check.
Since fixing that, however, yeah! It seems ease of working with data is good enough. Check.
Second question is a bit subjective, unless you have specific requirements (e.g. web page must load in 5ms).
Because Charts utilizes caching, with default 1 hour refresh (docs.mongodb.com/charts/saas/em…), our dashboard comes back nice and snappy. Check!
Because Charts utilizes caching, with default 1 hour refresh (docs.mongodb.com/charts/saas/em…), our dashboard comes back nice and snappy. Check!
So, to recap:
1. Duplicating data can be scary. But tools exist to make sure data remains consistent.
2. Clean your data: remodel/reformat before storing it (also protects against upstream API changes)
3. Know your use case. Otherwise, data model is a guessing game.
1. Duplicating data can be scary. But tools exist to make sure data remains consistent.
2. Clean your data: remodel/reformat before storing it (also protects against upstream API changes)
3. Know your use case. Otherwise, data model is a guessing game.
4. There's no "right way" to model your data. Two applications against same data might have different data models based on how it gets used.
5. Determine how much you want to tweak your data model based on working with data, and performance requirements.
5. Determine how much you want to tweak your data model based on working with data, and performance requirements.
Want to learn more? Read the full version of @Lauren_Schaefer's article at mongodb.com/developer/arti… (Bonus: 2 extra lessons! :D)
Other great resources:
* FREE #MongoDB University course: university.mongodb.com/courses/M320/a…
* Schema Design Patterns series: mongodb.com/blog/post/buil…
* Schema Anti-Patterns series: (YouTube) mongodb.com/developer/arti… (articles)
* Community: community.mongodb.com
* FREE #MongoDB University course: university.mongodb.com/courses/M320/a…
* Schema Design Patterns series: mongodb.com/blog/post/buil…
* Schema Anti-Patterns series: (YouTube) mongodb.com/developer/arti… (articles)
* Community: community.mongodb.com

Final parting thought: Every use case is different, so every data model will be different. Focus on how your app will use the data.

Connect with the (amazing!) presenters:
* Lauren: @Lauren_Schaefer / linktr.ee/lauren_schaefer
* Max: @MBeugnet
* Mark: @judy2k
Subscribe to youtube.com/channel/UCK_m2… (YouTube) and/or twitch.tv/mongodb (Twitch) for more live streams!
* Lauren: @Lauren_Schaefer / linktr.ee/lauren_schaefer
* Max: @MBeugnet
* Mark: @judy2k
Subscribe to youtube.com/channel/UCK_m2… (YouTube) and/or twitch.tv/mongodb (Twitch) for more live streams!
@threadreaderapp unroll please!
• • •
Missing some Tweet in this thread? You can try to
force a refresh


