
I am excited to share my latest work: 8-bit optimizers – a replacement for regular optimizers. Faster 🚀, 75% less memory 🪶, same performance📈, no hyperparam tuning needed 🔢. 🧵/n
Paper: arxiv.org/abs/2110.02861
Library: github.com/facebookresear…
Video:
Paper: arxiv.org/abs/2110.02861
Library: github.com/facebookresear…
Video:

8-bit optimizers are mostly useful to finetune large models that did not fit into memory before. It is also easier to pretrain larger models and it has great synergy with sharded data parallelism. 8-bit Adam is already used across multiple teams in Facebook.

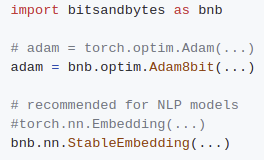
The CUDA-heavy bitsandbytes library was designed to be easy to use/install. It features 8-bit Adam/AdamW, SGD momentum, LARS, LAMB, and RMSProp, as well as high-performance quantization routines. It only requires a two-line code change to get you started!
There are other cool things that did not quite make it into the main paper. We also developed a quantization technique, quantile quantization, which quantizes an input tensor so that each bit combination is used equally often (a lossy minimum entropy encoding).
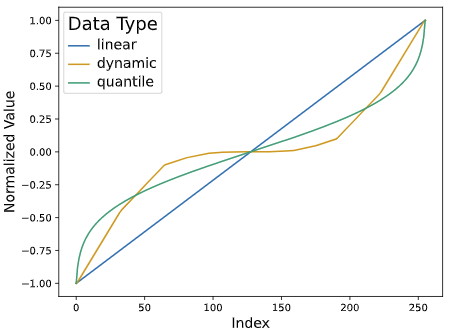

To make that computationally feasible, we developed a very fast approximate quantile estimation algorithm. It is 75x faster than the other best GPU quantile estimation algorithm.
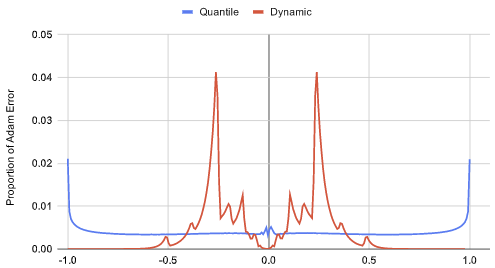
Quantile quantization has a much lower average quantization error than any other quantization technique, but there is a catch – it has high errors for large magnitude values due to quantile estimation uncertainty at the tails. This makes training unstable and degrades performance
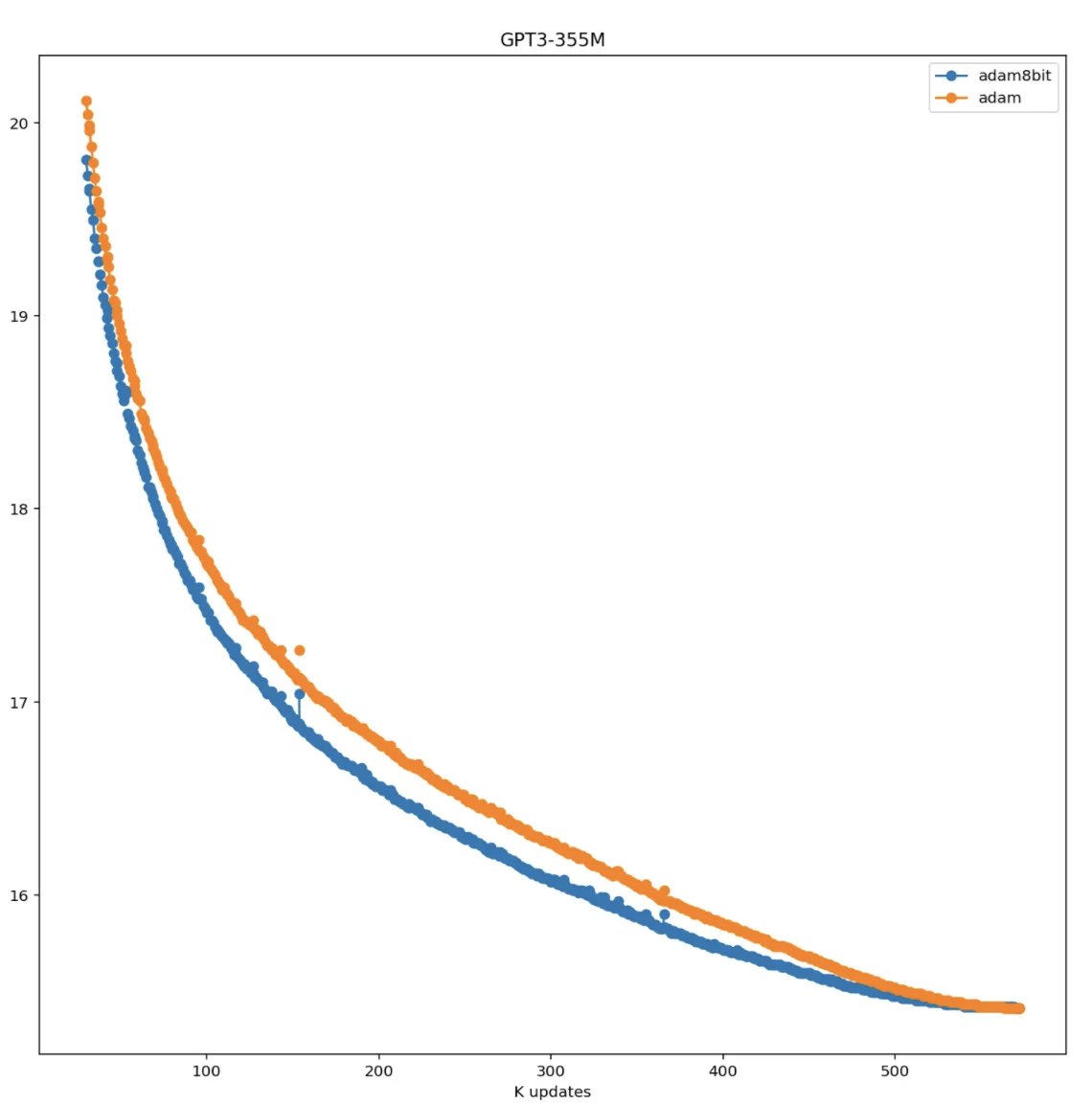
In this project I learned a lot about optimizers and I feel there is still large room for improving optimizers beyond Adam/LAMB. Quantization can also be improved by a lot. I think 6-bit optimizers are possible. There are also other interesting research questions on the horizon.
For example, some teams reported better numbers than 32-bit Adam when they use 8-bit Adam + Stable Embedding layer for NMT and large LM models when they use an inverse sqrt schedule. The effect disappears for a cosine schedule at small learning rates.
Two things seems to be at play here: (1) it is actually good to have smooth (approximate) estimates of the running squared sum for optimizers – I saw the same effect with Adafactor. (2) Quantization of small values is hard. Stochastic rounding helps, but is not the full solution
Another thing very clear to me is that we have very little understanding about why models become unstable during training. There seem to be a "rogue wave" like effects that the more parameters you have the higher the probability of a instability-cascade which derails training.
I tracked some running statistics of every single parameter of a 1B LM using some CUDA code and found that in two cases what seemed to be an update of a single parameter caused a cascade of loss scale reduction and eventual divergence.
I believe if we would understand these phenomena it would be much easier to train large models without all the hacks that we currently have. We probably could also train models faster with larger learning rates.
It was super fun working on this project with my great collaborators and mentors! I am grateful that I can work with such wonderful people: @ml_perception @sam_shleifer @LukeZettlemoyer
• • •
Missing some Tweet in this thread? You can try to
force a refresh


