
First modeling paper out of BigScience is here!
T0 shows zero-shot task generalization on English natural language prompts, outperforming GPT-3 on many tasks, while being 16x smaller!
Model: huggingface.co/bigscience/T0pp
Repo: github.com/bigscience-wor…
Paper: arxiv.org/abs/2110.08207
T0 shows zero-shot task generalization on English natural language prompts, outperforming GPT-3 on many tasks, while being 16x smaller!
Model: huggingface.co/bigscience/T0pp
Repo: github.com/bigscience-wor…
Paper: arxiv.org/abs/2110.08207

This was an international collaborative effort, with over 40 people across more than 25 organizations. The group included dedicated researchers and engineers from different universities, companies, and think tanks.

Our approach uses natural language prompts that allow us to share a format for a large variety of NLP tasks. We used a prompted format with the goal of allowing our model to generalize to unseen prompted tasks.

To collect the prompts for these tasks we built an open-source system for prompt engineering at a tremendous scale (as of now, there are ~2’000 prompts for 170+ datasets). The tool PromptSource is open-source and available on github.com/bigscience-wor…
To create T0, we fine-tuned T5 on a multi-task mixture of prompted datasets from Promptsource. When evaluated on zero-shot tasks, we found that it matched or exceeded GPT-3's performance on 9 of 11 datasets.

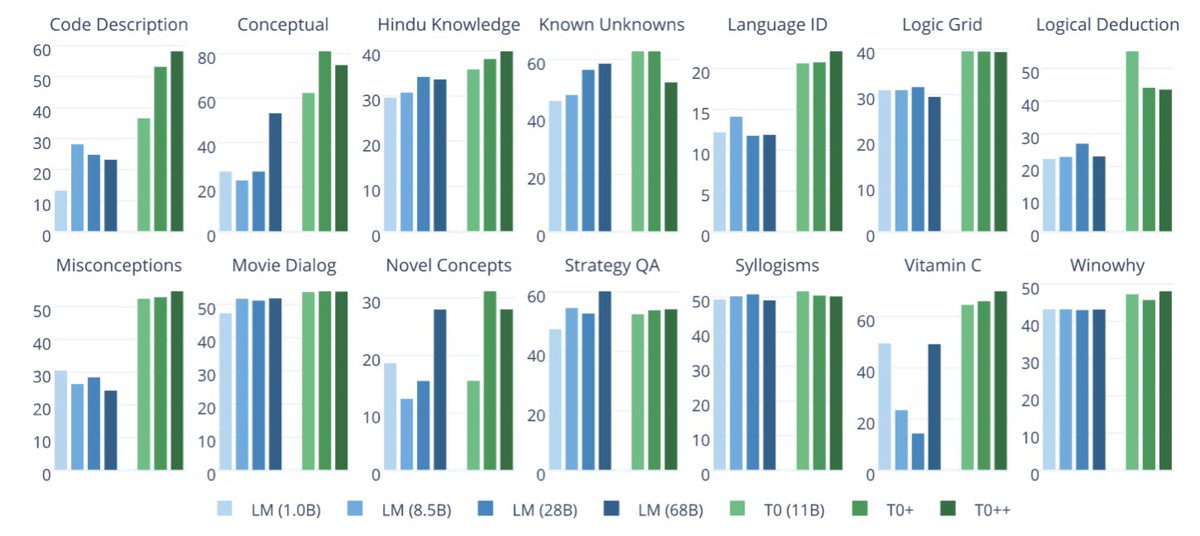
On a subset of BIG-Bench (github.com/google/BIG-ben…), a new collection of diverse and novel tasks intended to be difficult for large language models, T0 outperforms 6x larger language models on 13 out of 14 datasets.
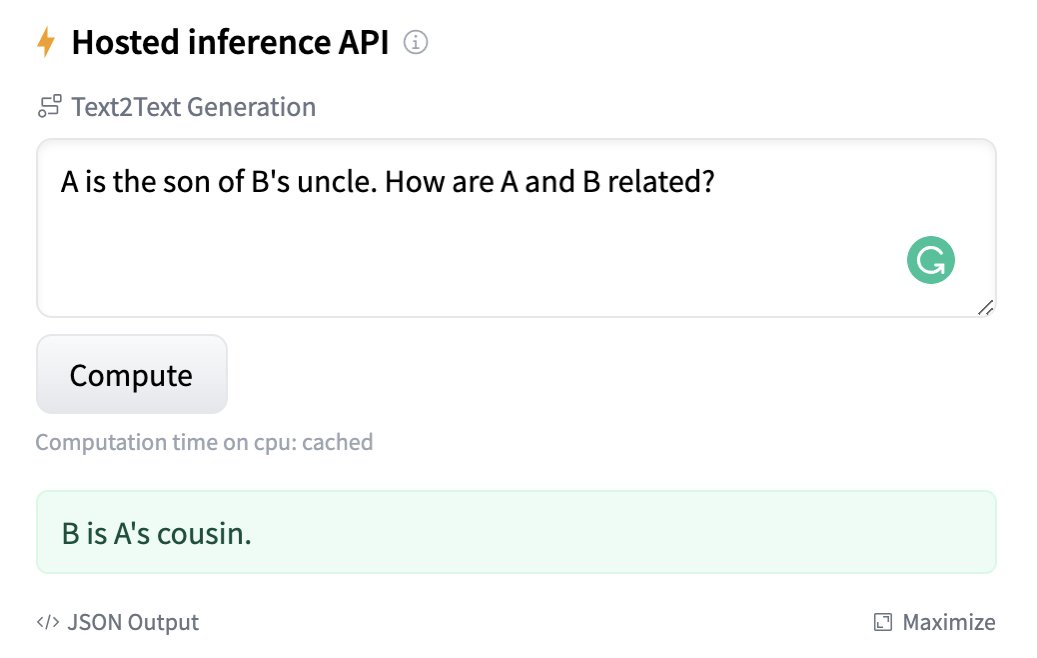
We have released T0 models in the Hugging Face Model Hub and you can try it out in your browser here: huggingface.co/bigscience/T0pp
We are also releasing all of our prompts as the Public Pool of Prompts (P3). You can see them on bigscience.huggingface.co/promptsource.

This is the first results coming out of the modeling working group, focusing on testing the method on English first. We are excited to work on extending the approach to multiple languages especially for languages with fewer existing datasets!
This project was made possible through the support of the TPU Research Cloud (@TensorFlow) and @Genci_fr who provided computational resources to train and evaluate our models.
• • •
Missing some Tweet in this thread? You can try to
force a refresh


