
Graph neural networks are driving lots of progress in machine learning by extending deep learning approaches to complex graph data and applications.
Let’s take a look at a few methods ↓
Let’s take a look at a few methods ↓
1) A Graph Convolutional Network, or GCN, is an approach for semi-supervised learning on graph-structured data. It’s based on an efficient variant of CNNs which operates directly on graphs and is useful for semi-supervised node classification.
paperswithcode.com/method/gcn
paperswithcode.com/method/gcn

2) Diffusion-convolutional neural networks (DCNN) introduce a diffusion-convolution operation to extend CNNs to graph data. This enables learning of diffusion-based representations. It's used as an effective basis for node classification.
paperswithcode.com/method/dcnn
paperswithcode.com/method/dcnn

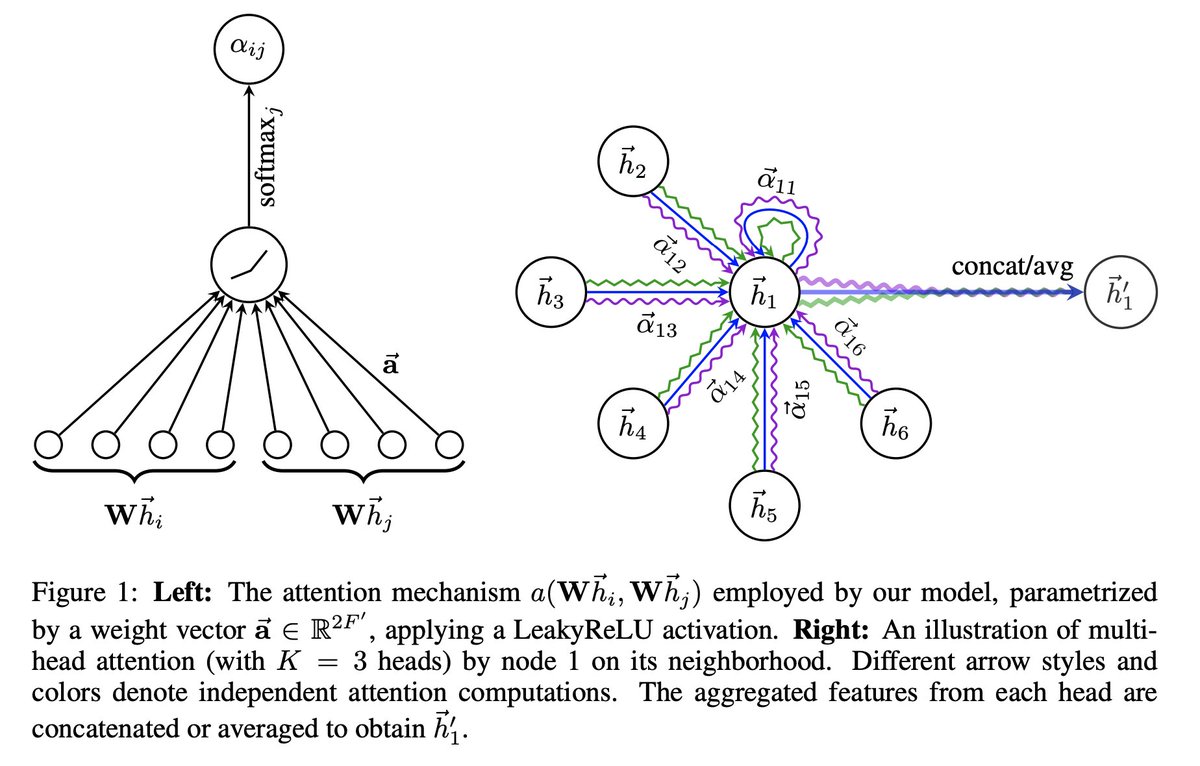
3) Graph Attention Network (GAT) is a graph neural network that leverages masked self-attentional layers. Hidden representations of nodes are computed by attending to neighbours using self-attention. It achieves SOTA results on node classification.
paperswithcode.com/method/gat
paperswithcode.com/method/gat
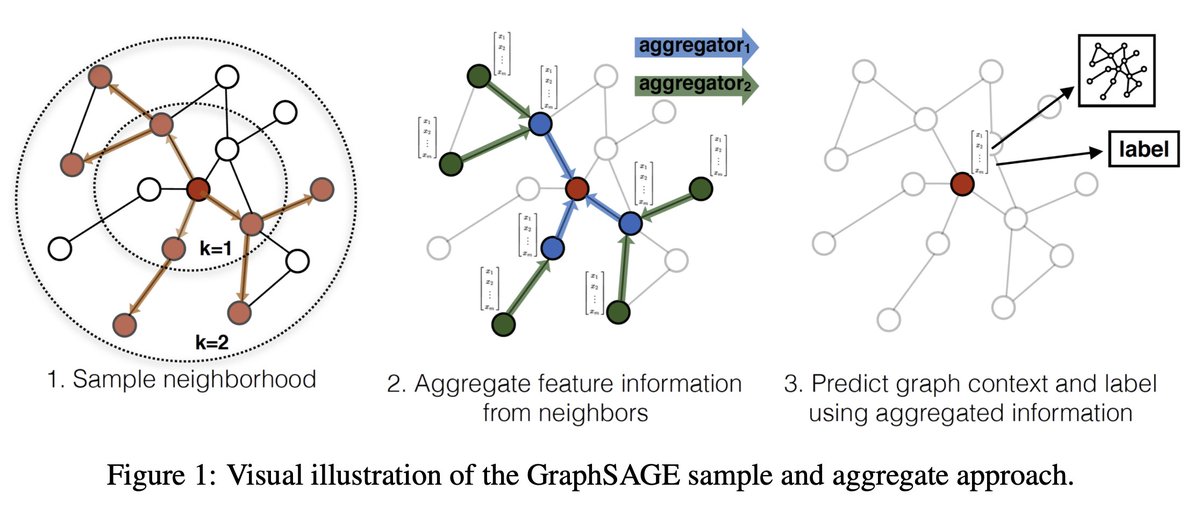
4) GraphSAGE is a general inductive framework that leverages node feature information (e.g., text attributes) to efficiently generate useful node embeddings for previously unseen data.
paperswithcode.com/method/graphsa…
paperswithcode.com/method/graphsa…
5) The Graph Transformer is a generalization of transformer neural networks for arbitrary graphs. The architecture introduces new properties that leverage the graph connectivity inductive bias to perform well on problems where graph topology is important.
paperswithcode.com/method/graph-t…
paperswithcode.com/method/graph-t…

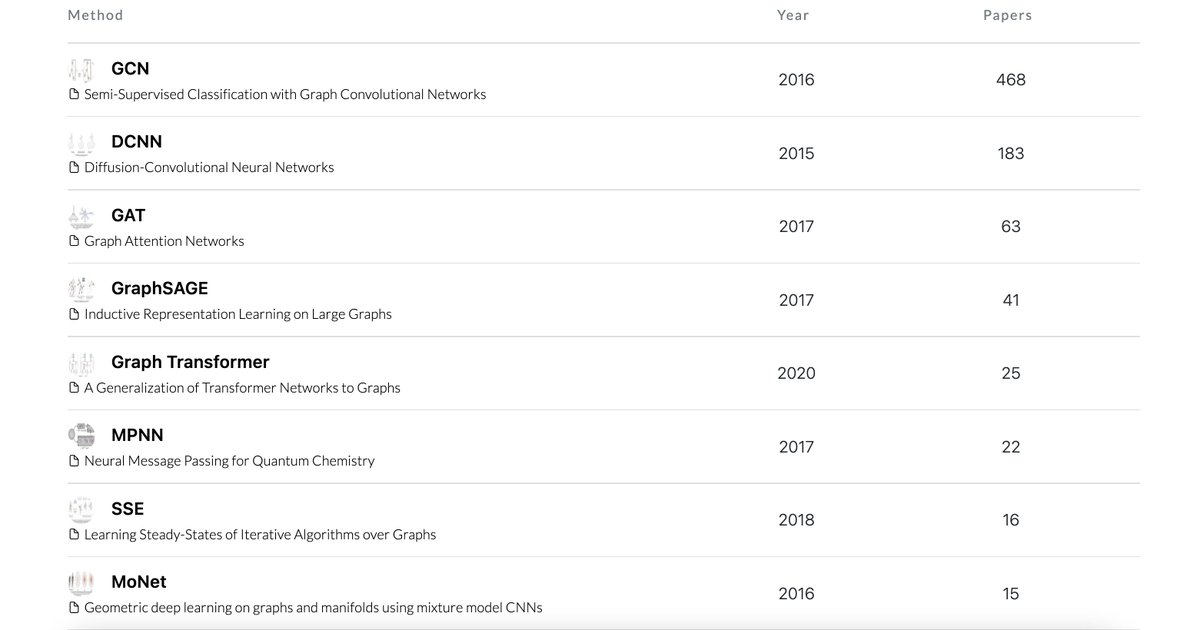
And finally but not least... here is an extended list of graph neural networks and their associated papers, benchmark datasets, trends, and open source codes.
paperswithcode.com/methods/catego…
paperswithcode.com/methods/catego…
• • •
Missing some Tweet in this thread? You can try to
force a refresh

















