
Our mission is to organize science by converting information into useful knowledge.

 1) An Image is Worth One Word - a new approach that allows for more creative freedom with image generation; proposes "textual inversions" to find pseudo-words that compose new sentences that guide personalized creations.
1) An Image is Worth One Word - a new approach that allows for more creative freedom with image generation; proposes "textual inversions" to find pseudo-words that compose new sentences that guide personalized creations.
 1️⃣ Mask DINO (Li et al) - extends DINO (DETR with Improved Denoising Anchor Boxes) with a mask prediction branch to support image segmentations tasks (instance, panoptic, and semantic).
1️⃣ Mask DINO (Li et al) - extends DINO (DETR with Improved Denoising Anchor Boxes) with a mask prediction branch to support image segmentations tasks (instance, panoptic, and semantic).
 1⃣ OPT (Zhang et al) - release open pre-trained transformer language models ranging from 125M to 175B parameters. The release include: logbook detailing infrastructure challenges and code to experiment with the released models. 2/11
1⃣ OPT (Zhang et al) - release open pre-trained transformer language models ranging from 125M to 175B parameters. The release include: logbook detailing infrastructure challenges and code to experiment with the released models. 2/11

 Our program would not be possible without the support of our awesome reviewers! To honor their hard work, we are excited to announce the Outstanding Reviewer Awards!
Our program would not be possible without the support of our awesome reviewers! To honor their hard work, we are excited to announce the Outstanding Reviewer Awards! 




 📄Trending Papers for 2021, featuring:
📄Trending Papers for 2021, featuring:



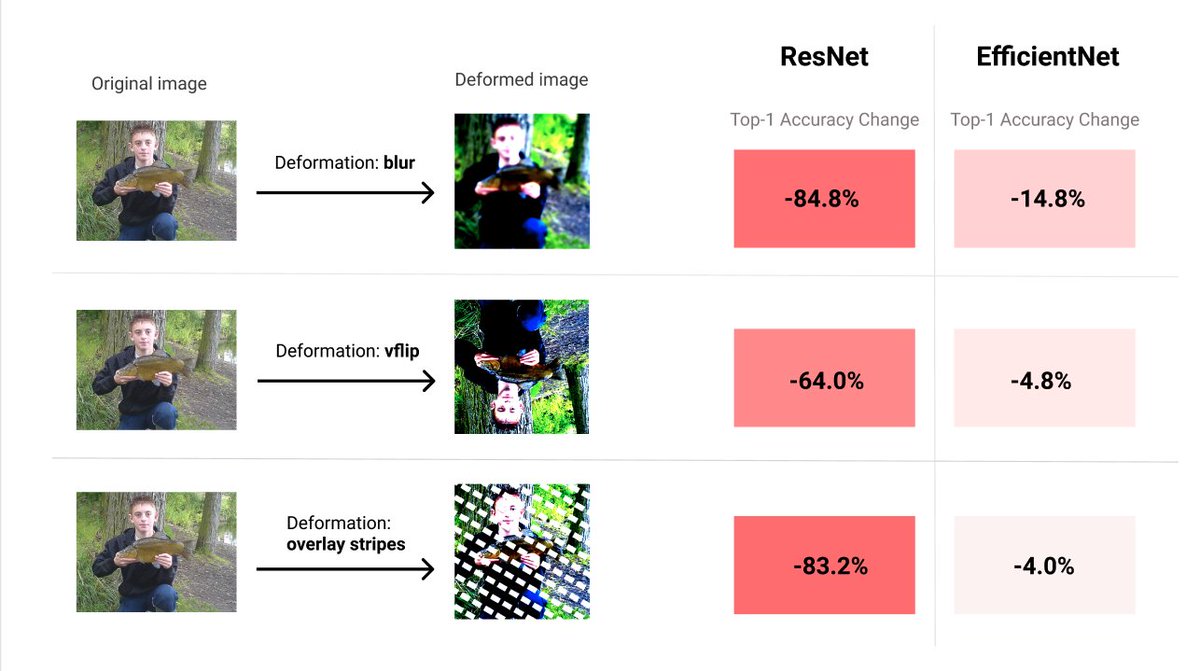 Reports shows that EfficientNet not only has higher accuracy on ImageNet, but is also significantly more robust than older models.
Reports shows that EfficientNet not only has higher accuracy on ImageNet, but is also significantly more robust than older models.



 The paper catalogues the exact training settings to provide a robust baseline for future experiments:
The paper catalogues the exact training settings to provide a robust baseline for future experiments: 
 👩🔬 Research: featuring work by @hieupham789 et al., @LiamFedus et al., @Pengcheng2020 et al., Stergiou et al., Ding et al., @quocleix, among others.
👩🔬 Research: featuring work by @hieupham789 et al., @LiamFedus et al., @Pengcheng2020 et al., Stergiou et al., Ding et al., @quocleix, among others. 





 📄 Trending Papers for 2020, featuring:
📄 Trending Papers for 2020, featuring: 


