
Transformers pioneered the principle of attention mechanisms to access past information.
However, most Transformer models discard older memories to prioritize more recent activations.
@DeepMind's Compressive Transformer tackles that problem.
1/4
However, most Transformer models discard older memories to prioritize more recent activations.
@DeepMind's Compressive Transformer tackles that problem.
1/4
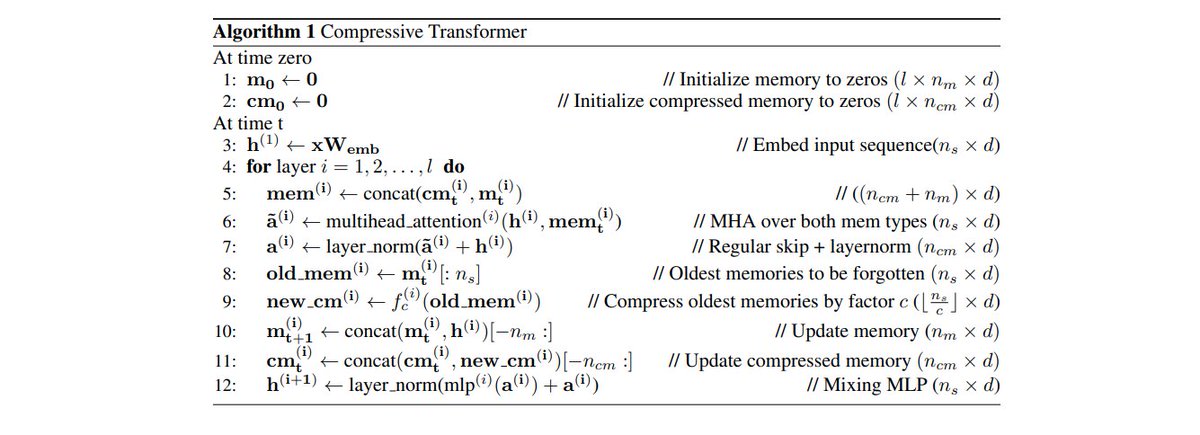
The Compressive Transformer tries to imitate the process of consolidating memories.
Under that approach, previous activations are compacted into a "compressed memory" that can be used in long-range tasks.
2/4
Under that approach, previous activations are compacted into a "compressed memory" that can be used in long-range tasks.
2/4

Compressive Transformer was evaluated against state-of-the-art memory models using WikiText-103 and Enwik8.
In both cases, it showed significant improvements over more established models both in memory and efficiency.
3/4
In both cases, it showed significant improvements over more established models both in memory and efficiency.
3/4

Thanks for being with us!
You can find additional info on Compressive Transformers in the original @DeepMind's paper: arxiv.org/abs/1911.05507
We've discussed the concept of attention used by transformer models here:
4/4
You can find additional info on Compressive Transformers in the original @DeepMind's paper: arxiv.org/abs/1911.05507
We've discussed the concept of attention used by transformer models here:
https://twitter.com/TheSequenceAI/status/1422579423811940358
4/4
• • •
Missing some Tweet in this thread? You can try to
force a refresh












