
Deep learning models for tabular data continue to improve. What are the latest methods and recent progress?
Let’s have a look ↓
Let’s have a look ↓
1) Wide&Deep jointly trains wide linear models and deep neural networks to combine the benefits of memorization and generalization for real-world recommender systems. The model was productionized and evaluated on Google Play.
paperswithcode.com/method/wide-de…
paperswithcode.com/method/wide-de…

2) TaBERT is a pretrained LM that jointly learns representations for natural language sentences and (semi-)structured tables. TaBERT works well for semantic parsing and is trained on a large corpus of 26 million tables and their English contexts.
paperswithcode.com/method/tabert
paperswithcode.com/method/tabert
3) TabTransformer is a deep tabular data modeling architecture for supervised and semi-supervised learning. It is built upon self-attention based Transformers. The model learns robust contextual embeddings to achieve higher prediction accuracy.
paperswithcode.com/method/tabtran…
paperswithcode.com/method/tabtran…

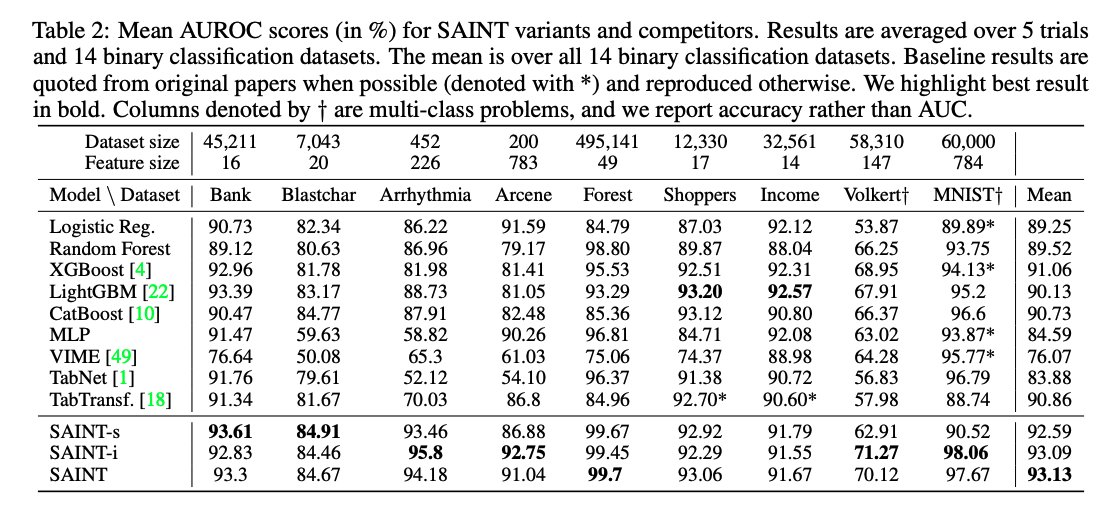
4) SAINT is a recent hybrid deep learning approach for tabular data. It performs attention over both rows and columns, and it includes an enhanced embedding method. It outperforms gradient boosting methods like CatBoost on a variety of benchmark tasks.
paperswithcode.com/method/saint
paperswithcode.com/method/saint
5) FT-Transformer is a Transformer-based architecture for the tabular domain. The model transforms all features (categorical and numerical) to tokens and runs a stack of Transformer layers over the tokens. It outperforms other DL models on several tasks.
paperswithcode.com/method/ft-tran…
paperswithcode.com/method/ft-tran…
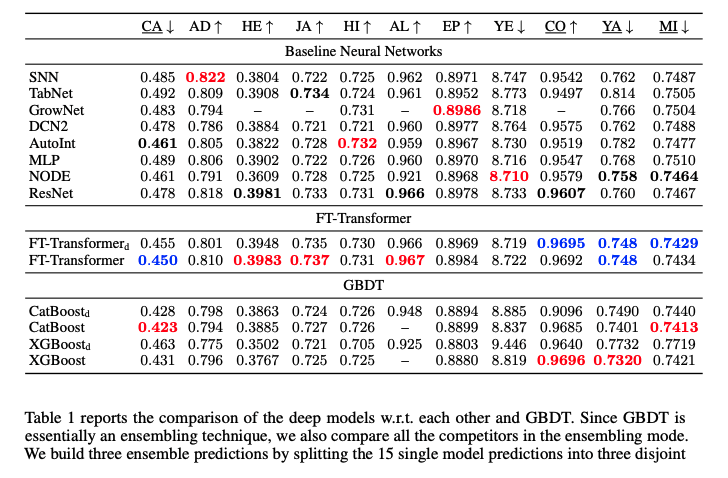
To track the latest deep learning models applied to tabular data here is an extended list of methods, including associated papers, open source codes, benchmark datasets, and trends.
paperswithcode.com/methods/catego…
paperswithcode.com/methods/catego…

• • •
Missing some Tweet in this thread? You can try to
force a refresh

















