✨ Training Object Detection Models Tips & Tricks ✨
🧊 Data Labeling:
📌 Avoid adding low quality data: it confuses your model
📌 Prevent data leak
📌 Dataset size: Smaller size if using pretrained models. Bigger size if training from scratch
...
🧊 Data Labeling:
📌 Avoid adding low quality data: it confuses your model
📌 Prevent data leak
📌 Dataset size: Smaller size if using pretrained models. Bigger size if training from scratch
...

📌 Use prototypical (representative) data for each class
📌 Identify incorrect classes
📌 Identify ambiguous labelled images
📌 Balance your data distribution
📌 Identify incorrect classes
📌 Identify ambiguous labelled images
📌 Balance your data distribution
📌 Train from scratch if your dataset is different from the COCO dataset
📌 When your model stops improving, you might add more data to move the needle:
📌 When your model stops improving, you might add more data to move the needle:
📌 Use Soft-Labelling: label new data with pretrained models => Free labels
📌 Use Self-Training: label new data with your model you are training. Add newly labelled data to your training dataset. Loop
📌 Use Self-Training: label new data with your model you are training. Add newly labelled data to your training dataset. Loop
🧊 Modeling
📌 Use larger models. They outperform smaller ones
📌 Use smaller models 😀 when training small dataset
📌 Use Focal Loss for the classification head (RetinaNet , EfficientDet, ...)
📌 Use GIoU Loss for the regression head (box location): Need a separate post 😄
📌 Use larger models. They outperform smaller ones
📌 Use smaller models 😀 when training small dataset
📌 Use Focal Loss for the classification head (RetinaNet , EfficientDet, ...)
📌 Use GIoU Loss for the regression head (box location): Need a separate post 😄
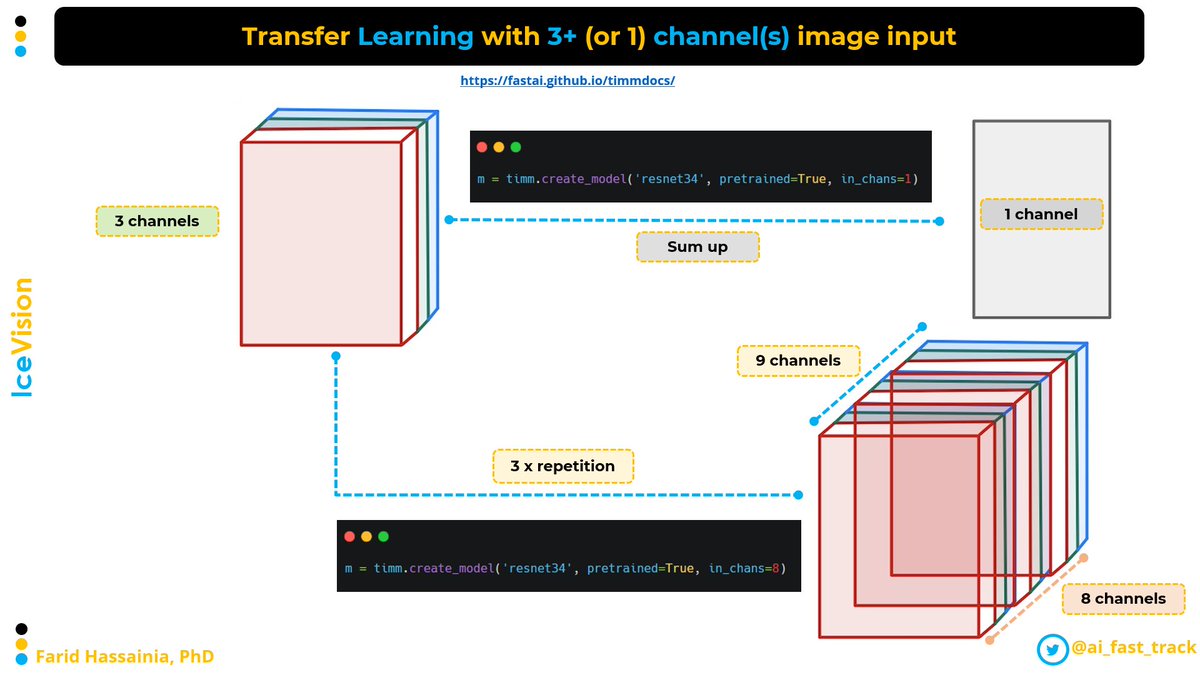
📌 Trained with ImageNet isn't always effective
📌 YOLO-ReT paper showed that using the whole pretrained backbone harms model performance
📌 Use Backbone Truncation (like YOLO-ReT): Only 60% of the backbone is initialised with pretrained weights.
📌 YOLO-ReT paper showed that using the whole pretrained backbone harms model performance
📌 Use Backbone Truncation (like YOLO-ReT): Only 60% of the backbone is initialised with pretrained weights.
🧊 Anchor Boxes
📌 Use anchor boxes with size/ratio close to target boxes
📌 Make sure you know how your anchor boxes look like
📌 Use some anchor-free OD models (e.g., VFNet): No anchor boxes. Some perform even better than anchor-based models
📌 Use anchor boxes with size/ratio close to target boxes
📌 Make sure you know how your anchor boxes look like
📌 Use some anchor-free OD models (e.g., VFNet): No anchor boxes. Some perform even better than anchor-based models
🧊 Data augmentation
📌 Oversample images with small boxes
📌 Use transforms close to your use case
📌 Use Copy & Paste boxes data augmentation
📌 Oversample images with small boxes
📌 Use transforms close to your use case
📌 Use Copy & Paste boxes data augmentation
📌 Use mosaic data augmentation
📌 Some suggest using heavy data augmentation at the beginning of training, and light data augmentation at the end
📌 Some suggest using heavy data augmentation at the beginning of training, and light data augmentation at the end
🧊 Training
📌 Don’t worry too much about overfitting at the beginning of project: Adding more data/ data augmentation should mitigate that
📌 Train for a longer period (more epochs): As long as your loss is decreasing
📌 Don’t worry too much about overfitting at the beginning of project: Adding more data/ data augmentation should mitigate that
📌 Train for a longer period (more epochs): As long as your loss is decreasing
📌 In transfer learning, when freezing NN layers, you should leave BatchNorm layers as trainable
📌 Train using progressive resizing
📌 Use discriminative learning rate. Low learning rate for backbones, higher learning rate for the head
📌 Use the recommended LR scheduler
📌 Train using progressive resizing
📌 Use discriminative learning rate. Low learning rate for backbones, higher learning rate for the head
📌 Use the recommended LR scheduler
🧊 Inference
📌 Use the same image size as the one you train your model with
📌 With high resolution images, apply inference on patches/slices and then stitch them together: e.g., Slicing-Aided Hyper Inference
📌 Use the same image size as the one you train your model with
📌 With high resolution images, apply inference on patches/slices and then stitch them together: e.g., Slicing-Aided Hyper Inference
📌 Don’t forget to put the model on evaluation mode (eval_mode): It automatically disables Dropout, BatchNorm, and backpropagation.
🎉This is my longest thread since I joined🐦
If you like this kind of content, follow @ai_fast_track for more OD / CV demystified content in your feed
🙏If you could give the thread a quick retweet, it would help others discover this content! Thanks!
If you like this kind of content, follow @ai_fast_track for more OD / CV demystified content in your feed
🙏If you could give the thread a quick retweet, it would help others discover this content! Thanks!
https://twitter.com/ai_fast_track/status/1458493806362378244
• • •
Missing some Tweet in this thread? You can try to
force a refresh