
🚀 Mentor | IceVision Creator
✨I help companies leverage AI and develop innovative products
🧩I assist mentees in becoming the top 1% of AI practitioners

 Here is also an awesome survey about Low-Shot Learning I already shared:
Here is also an awesome survey about Low-Shot Learning I already shared: It covers:
It covers: What's Included
What's Included
 🤔 Context
🤔 Context
 🔸 Scale imbalance
🔸 Scale imbalance
 👉 Data Labeling
👉 Data Labeling

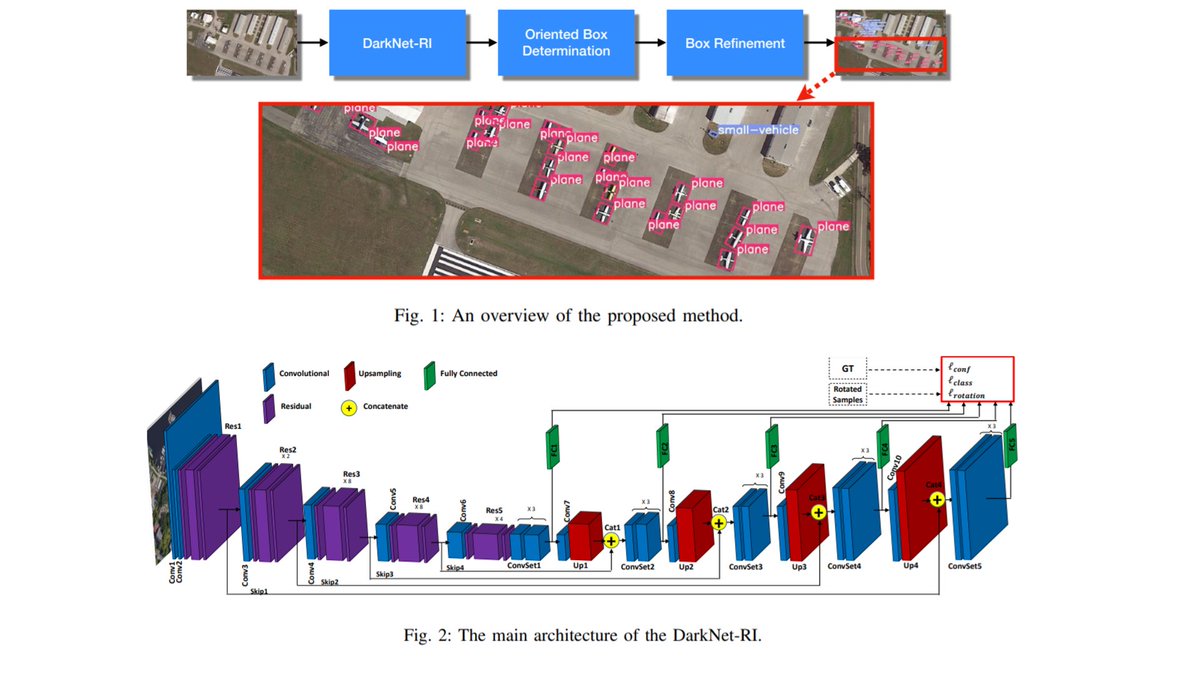
 📌 Prior work uses the classification score or a combination of classification and predicted localization scores (centerness) to rank candidates.
📌 Prior work uses the classification score or a combination of classification and predicted localization scores (centerness) to rank candidates.  🔸 Scale imbalance
🔸 Scale imbalance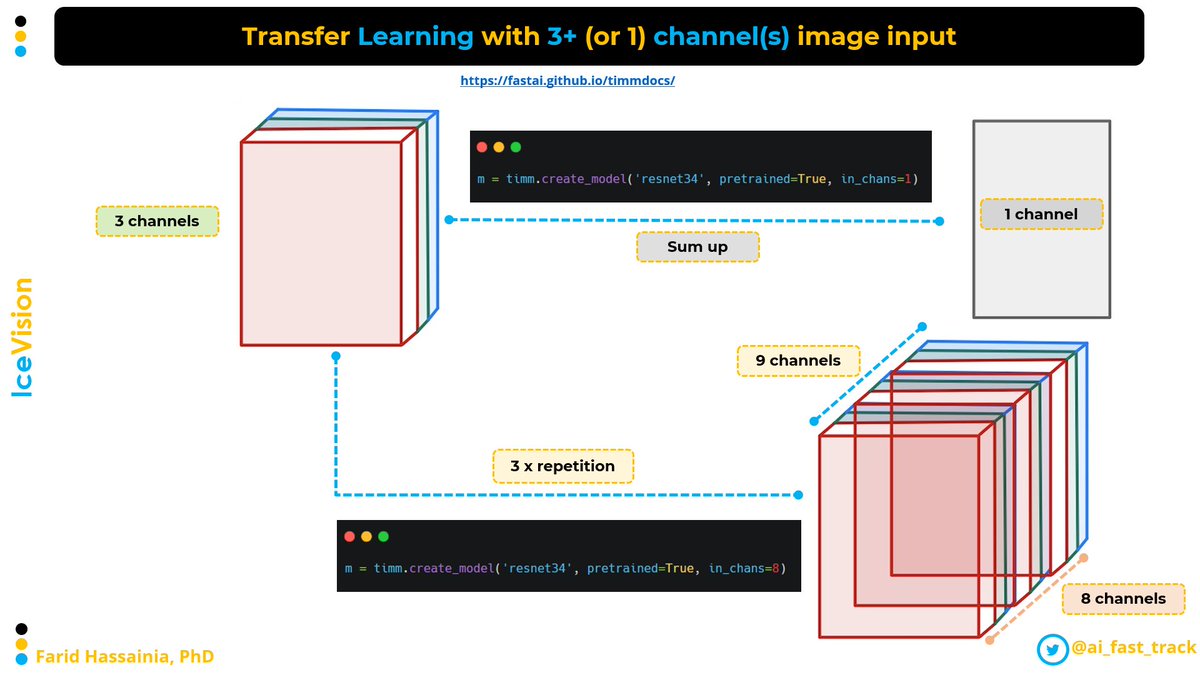 @wightmanr m = timm.create_model('resnet34', pretrained=True, in_chans=8)
@wightmanr m = timm.create_model('resnet34', pretrained=True, in_chans=8) • To address that issue, the authors propose a simple yet surprisingly powerful data augmentation and training scheme they call Learning to Detect Every Thing (LDET)
• To address that issue, the authors propose a simple yet surprisingly powerful data augmentation and training scheme they call Learning to Detect Every Thing (LDET)