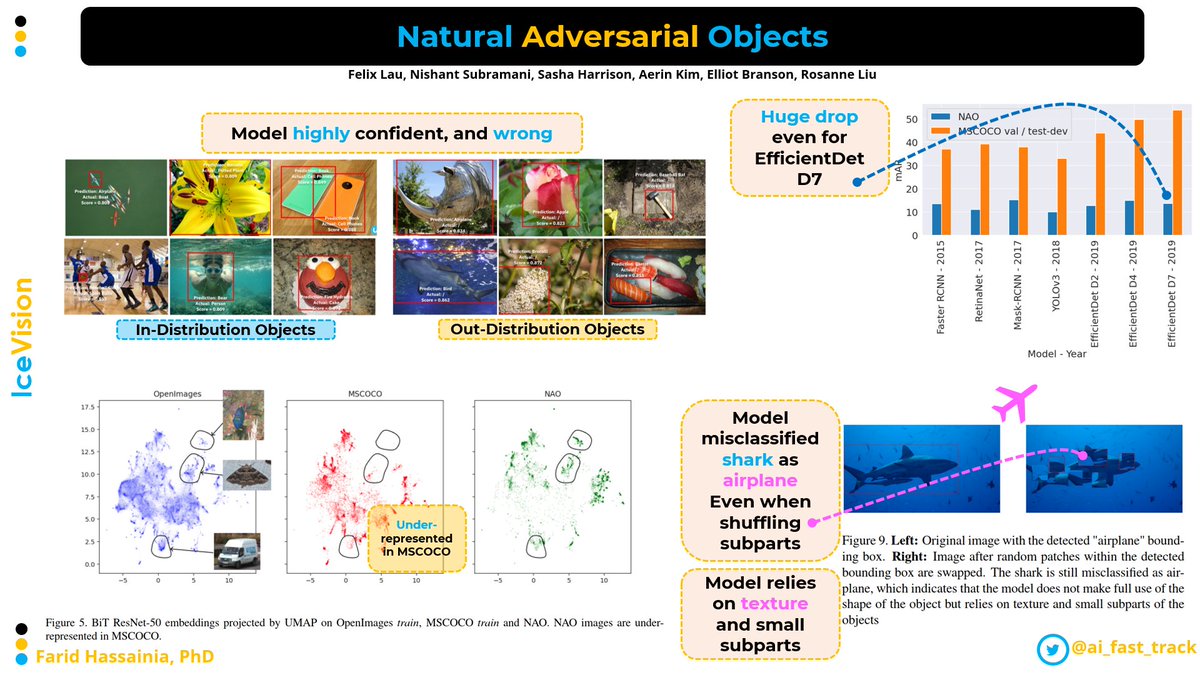
Day 24/30: 🥇 EfficientDet is a very popular object detection model for a good reason!
Let’s see why
📌 EfficientDet achieved State-Of-The-Art (SOTA) accuracy while reducing both the size of parameters, and the FLOPS, when it was released. It’s still a very good contender.
Let’s see why
📌 EfficientDet achieved State-Of-The-Art (SOTA) accuracy while reducing both the size of parameters, and the FLOPS, when it was released. It’s still a very good contender.
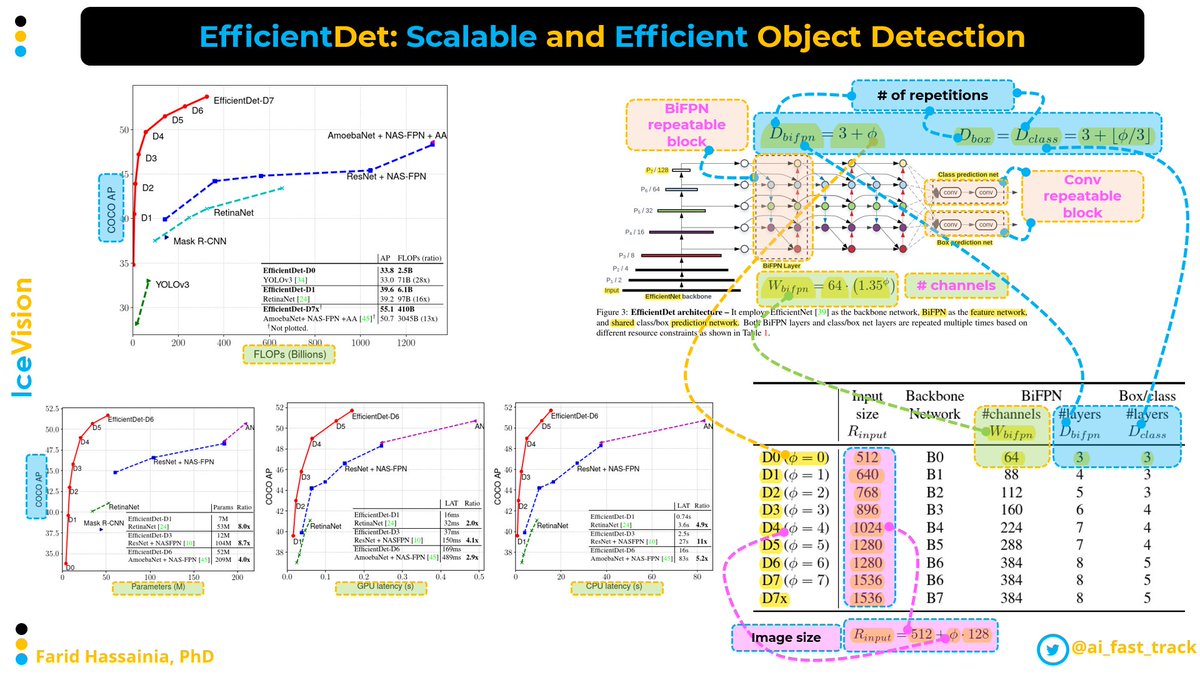
📌 Before introducing EfficientDet, models were getting impressively big to achieve SOTA results
❓ The authors asked the following question:
Is it possible to build a scalable detection architecture with both higher accuracy and better efficiency across # resource constraints?
❓ The authors asked the following question:
Is it possible to build a scalable detection architecture with both higher accuracy and better efficiency across # resource constraints?
So, they systematically studied neural network architecture design choices for object detection, and proposed several key optimizations to improve efficiency:
1- A weighted bi-directional feature pyramid network (BiFPN), which allows easy and fast multiscale feature fusion
1- A weighted bi-directional feature pyramid network (BiFPN), which allows easy and fast multiscale feature fusion
2- A compound scaling method that uniformly scales the resolution (image size), depth (# layers), and width (# channels) for all backbone, feature network, and box/class prediction networks at the same time
As you might noticed in the figure, image size, # of layers, and # of channels are all dependent on the phi factor. The latter determines the values of those 3 components to consistently achieve better accuracy with much fewer parameters and FLOPs than previous object detectors.
📌 EfficientDet-D7 achieves state-of-the-art 55.1 AP on COCO test-dev with 77M parameters and 410B FLOPs, being 4x - 9x smaller and using 13x - 42x fewer FLOPs than previous detectors.
IceVision supports EfficientDet. Check out how simple instantiating an EfficientDet model.
IceVision supports EfficientDet. Check out how simple instantiating an EfficientDet model.
Paper: EfficientDet: Scalable and Efficient Object Detection
abs: arxiv.org/abs/1911.09070
pdf: arxiv.org/pdf/1911.09070…
- Official TensorFLow version: github.com/google/automl/…
@wightmanr implemented the canonical pytorch version: github.com/rwightman/effi…
(supported in IceVision)
abs: arxiv.org/abs/1911.09070
pdf: arxiv.org/pdf/1911.09070…
- Official TensorFLow version: github.com/google/automl/…
@wightmanr implemented the canonical pytorch version: github.com/rwightman/effi…
(supported in IceVision)
⭐️ If you find this thread helpful, feel free to follow @ai_fast_track for more OD / CV demystified content in your feed
⭐️ If you could give this thread a quick retweet, it would help others discover this content. Thanks!
⭐️ If you could give this thread a quick retweet, it would help others discover this content. Thanks!
https://twitter.com/ai_fast_track/status/1463578147090317312
• • •
Missing some Tweet in this thread? You can try to
force a refresh