
захотелось написать про билд системы чутка
нормальных за 10 лет не встречал, плотно работал с Gradle, Buck, Bazel
не оч плотно: Make, Maven, Ant, Cargo, Go build
нормальных за 10 лет не встречал, плотно работал с Gradle, Buck, Bazel
не оч плотно: Make, Maven, Ant, Cargo, Go build
было бы круто иметь в билд системе:
1. статически типизированный современный яп для билд файлов и плагинов вроде Kotlin
2. параллельную конфигурацию модулей
3. кеширование конфигурации
4. параллельное выполнение билд графа
5. локальный билд кеш между проектами
1. статически типизированный современный яп для билд файлов и плагинов вроде Kotlin
2. параллельную конфигурацию модулей
3. кеширование конфигурации
4. параллельное выполнение билд графа
5. локальный билд кеш между проектами
6. распределенный ремоут билд кеш
7. трейсинг и профайлинг конфигурации и билд графа
8. строгое версионирование и верификация зависимостей
9. легковесная контейнерезация окружения выполнения
10. JSON/etc вывод для интеграции с IDE и другим тулингом
11. мониторинг файловой системы
7. трейсинг и профайлинг конфигурации и билд графа
8. строгое версионирование и верификация зависимостей
9. легковесная контейнерезация окружения выполнения
10. JSON/etc вывод для интеграции с IDE и другим тулингом
11. мониторинг файловой системы
12. распределенное ремоутное выполнение билда на кластере машин с контейнерезацией окружения выполнения
13. поддержка зависимостей как исходники и как пребилд
13. поддержка зависимостей как исходники и как пребилд
наверняка шото забыл, разберу по пунктам как это работает в существующих системах
1. яп конфигурирования и плагинов:
Gradle: Groovy мрак, гадаешь типы, интерпретация не оч быстрая, добавили Kotlin, стало получше
но Gradle разрешает сайд эффекты в билд скриптах(!)
1. яп конфигурирования и плагинов:
Gradle: Groovy мрак, гадаешь типы, интерпретация не оч быстрая, добавили Kotlin, стало получше
но Gradle разрешает сайд эффекты в билд скриптах(!)
то есть в конфигурационном файле или плагине буквально можно делать любой файловый или сетевой IO
это безумие
ломает повторяемость конфигурации проекта: два раза запускаешь — результат может зависеть от внешних файторов, секьюрити риск
это безумие
ломает повторяемость конфигурации проекта: два раза запускаешь — результат может зависеть от внешних файторов, секьюрити риск
1. Bazel: яп конфигурации и плагинов
вводная такая, Bazel не супер известная, но довольно крутая билд система от Google
внутри известна как Blaze, начиналась ещё в середине 2000х, где-то в 2015 стала оупен сорсной
у них свой яп конфигурации и плагинов (rules) — Starlark
вводная такая, Bazel не супер известная, но довольно крутая билд система от Google
внутри известна как Blaze, начиналась ещё в середине 2000х, где-то в 2015 стала оупен сорсной
у них свой яп конфигурации и плагинов (rules) — Starlark
Starlark синтаксически копирует Python, но имеет свою стандартную библиотеку без IO и интерпретатор, который жестко ограничивает сайд эффекты и не позволяет хранить глобальное состояние в памяти
docs.bazel.build/versions/main/…
к слову, его можно использовать и без Bazel
docs.bazel.build/versions/main/…
к слову, его можно использовать и без Bazel
из-за этих ограничений он репродюсибл и выполняется параллельно между модулями
Bazel позволяет IO только через свою библиотеку и контроллирует все input/outputы, шо делает конфигурацию повторяемой и кешируемой
из минусов — динамическая — гадаешь типы, но повторяемая типизация
Bazel позволяет IO только через свою библиотеку и контроллирует все input/outputы, шо делает конфигурацию повторяемой и кешируемой
из минусов — динамическая — гадаешь типы, но повторяемая типизация
на Starlark же пишутся плагины (rules), вот тут они имеют право запускать внешние программы и соответственно нарушать повторяемость
Bazel старается бить за это по рукам, используя sandboxing для выполнения билд экшенов
docs.bazel.build/versions/main/…
Bazel старается бить за это по рукам, используя sandboxing для выполнения билд экшенов
docs.bazel.build/versions/main/…
из прикольного, rule в Bazel может создать Persistent Worker — процесс который оборачивает какую-то штуку в демона, удобно для интеграции JVM/etc тулов в билд которые для перформанса лучше держать горячими, чем запускать на каждый чих
пример реализации github.com/buildfoundatio…
пример реализации github.com/buildfoundatio…
единственное шо меня бесит в Starlark — динамическая типизация, оч сложно читать и писать хоть немного сложный код
вызываешь функцию и идешь читать сорцы надеясь шо поймешь возвращаемый тип, а она там вызывает десяток других, компилятора нет
пример github.com/bazelbuild/rul…
вызываешь функцию и идешь читать сорцы надеясь шо поймешь возвращаемый тип, а она там вызывает десяток других, компилятора нет
пример github.com/bazelbuild/rul…
1. Buck: яп конфигурации
вводная такая:
челы из гугла пришли в фейсбук и такие: а как жить без Blaze
сделали свой идейный клон и выложили в оупен сорс быстрее чем гугл выложил Bazel(!)
но, яп у них сначала был именно Python, потом интегрировали Starlark
плагинов нельзя
вводная такая:
челы из гугла пришли в фейсбук и такие: а как жить без Blaze
сделали свой идейный клон и выложили в оупен сорс быстрее чем гугл выложил Bazel(!)
но, яп у них сначала был именно Python, потом интегрировали Starlark
плагинов нельзя
1. Makefile: яп конфигурации
ну он свой, простой и лимитированный
пишешь таргеты и можешь ссылаться на них
типа
compile:
javac -jar A.java
jar: compile
jar -cf A.jar A.class
run: jar
java -jar A.jar
make run
есть супер базовые переменные, и всё…
ну он свой, простой и лимитированный
пишешь таргеты и можешь ссылаться на них
типа
compile:
javac -jar A.java
jar: compile
jar -cf A.jar A.class
run: jar
java -jar A.jar
make run
есть супер базовые переменные, и всё…
на Make ничего особо не напишешь, но использовал и много где вижу как верхнеуровый конфиг для запуска других тулов и билд систем
db_test:
./prepare-test-env.sh
./gradlew test :a
./shutdown-test-env.sh (тут прикол шо если упадет пред, то это не выполнится, не надо так)
db_test:
./prepare-test-env.sh
./gradlew test :a
./shutdown-test-env.sh (тут прикол шо если упадет пред, то это не выполнится, не надо так)
1. Maven: яп конфигурации и плагинов
конфигурация на XML то есть не яп, а разметки, запаришься писать, но строгая схема помогает, билд нельзя программировать
программировать ток через плагины на любом JVM языке, плагинам можно все сайдэффекты
конфигурация на XML то есть не яп, а разметки, запаришься писать, но строгая схема помогает, билд нельзя программировать
программировать ток через плагины на любом JVM языке, плагинам можно все сайдэффекты
1. Maven сильно заточен на сборку Java проектов и их публикацию в виде собсно Maven зависимостей
в принципе артефактом не обязан быть .jar, а языком Java, но это подразумевается
поэтому в отличие от более универсальных Gradle и Bazel вне JVM мира не используется
в принципе артефактом не обязан быть .jar, а языком Java, но это подразумевается
поэтому в отличие от более универсальных Gradle и Bazel вне JVM мира не используется
Maven формат стал однако ☝️ стандартом публикаций библиотек в JVM мире
Maven Central от Sonatype основной JVM репозиторий, с ним работают все JVM билд системы: Gradle, Bazel, Buck, Sbt и тп
JCenter от Bintray был альтернативой, но недавно закрыли
GitHub еще
Maven Central от Sonatype основной JVM репозиторий, с ним работают все JVM билд системы: Gradle, Bazel, Buck, Sbt и тп
JCenter от Bintray был альтернативой, но недавно закрыли
GitHub еще
Maven Central это «Замок» Кафки в мире оупен сорса
шоб опубликовать там библиотеку надо зарегаться в их джире
создать таску с описанием
подождать неск дней(!) пока согласуют именования и выдадут креды
публикация полуручная, автоматизируется с проверками на таймаутах
шоб опубликовать там библиотеку надо зарегаться в их джире
создать таску с описанием
подождать неск дней(!) пока согласуют именования и выдадут креды
публикация полуручная, автоматизируется с проверками на таймаутах
1. яп конфигурации Cargo
TOML, это чуть лучше YAML, но все ещё больно, ну и программировать поведение нельзя, это язык разметки
плагины на расте, заточена на раст
было грустно наблюдать как новый яп тратит много ресурсов на очередную билд систему
TOML, это чуть лучше YAML, но все ещё больно, ну и программировать поведение нельзя, это язык разметки
плагины на расте, заточена на раст
было грустно наблюдать как новый яп тратит много ресурсов на очередную билд систему
если бы раст делали в 2021 я бы топил за Bazel, к слову есть github.com/bazelbuild/rul…
но тогда действительно универсальных и хороших вариантов было немного, хотя могли взять Gradle
для системных лоу левел чуваков использовать JVM тулы это конечно оффенс, но есть ведь CLion!
но тогда действительно универсальных и хороших вариантов было немного, хотя могли взять Gradle
для системных лоу левел чуваков использовать JVM тулы это конечно оффенс, но есть ведь CLion!
да и пишут многие растоводы и плюсовики на Visual Studio Code, а там вообще Electron
меня оффенсит не сам JVM или JS, а их inheritant перформанс, GC паузы и потребление памяти
меня оффенсит не сам JVM или JS, а их inheritant перформанс, GC паузы и потребление памяти
2. параллельная конфигурация модулей
есть в Bazel и Buck
в Gradle её пока нет тк каждый модуль может изменить глобальное состояние Gradle конфигурации
я предложил им режим изоляции конфигурации модулей, сейчас это экспериментальная фича
gradle.github.io/configuration-…
есть в Bazel и Buck
в Gradle её пока нет тк каждый модуль может изменить глобальное состояние Gradle конфигурации
я предложил им режим изоляции конфигурации модулей, сейчас это экспериментальная фича
gradle.github.io/configuration-…

для понимания масштаба проблемы: когда в Lyft проекте было 1k модулей, однопоточная Gradle конфигурация занимала 30 секунд
на любой чих приходилось ждать полминуты прежде чем начнется полезная работа билд системы
Buck справлялся за 1.5 секунды
сейчас там около 2.5к модулей
на любой чих приходилось ждать полминуты прежде чем начнется полезная работа билд системы
Buck справлялся за 1.5 секунды
сейчас там около 2.5к модулей
3. кеширование конфигурации
критически важно для хорошего экспириенса
Buck и Bazel умеют кешировать конфигурацию, это важно для многомодульных проектов
судя по всему Cargo и Go Build это тоже умеют тк зависимости там из исходников и оверхеда на запуск билд команд не испытываю
критически важно для хорошего экспириенса
Buck и Bazel умеют кешировать конфигурацию, это важно для многомодульных проектов
судя по всему Cargo и Go Build это тоже умеют тк зависимости там из исходников и оверхеда на запуск билд команд не испытываю
но ключевое отличие Bazel в данном случае в том, шо он кеширует конфигурацию сгенерированную от результата выполнения кода пользователя
а другие кешируют результат парсинга языка разметки
(Buck я перестану упоминать потому что на фоне Bazel в 2021 он бесполезен)
а другие кешируют результат парсинга языка разметки
(Buck я перестану упоминать потому что на фоне Bazel в 2021 он бесполезен)
это фундаментально разные подходы, яп позволяет очень гибко настроить билд, в отличие от языка разметки
функциональная чистота Starlark, отсутствие IO == повторяемость выполнения
→ позволяют Bazel получить бенефиты обоих миров: гибкость и перформанс
это оч круто
функциональная чистота Starlark, отсутствие IO == повторяемость выполнения
→ позволяют Bazel получить бенефиты обоих миров: гибкость и перформанс
это оч круто
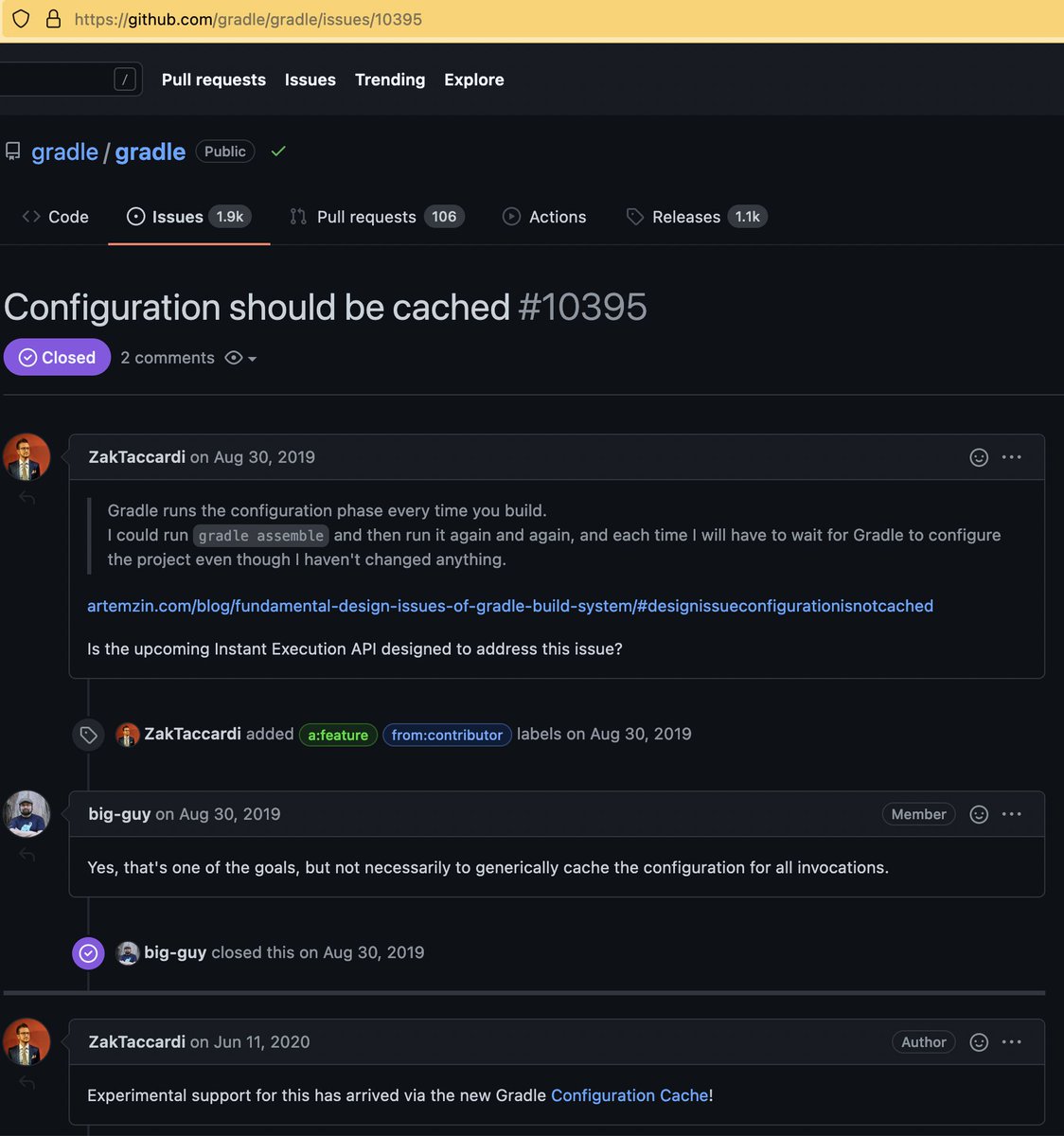
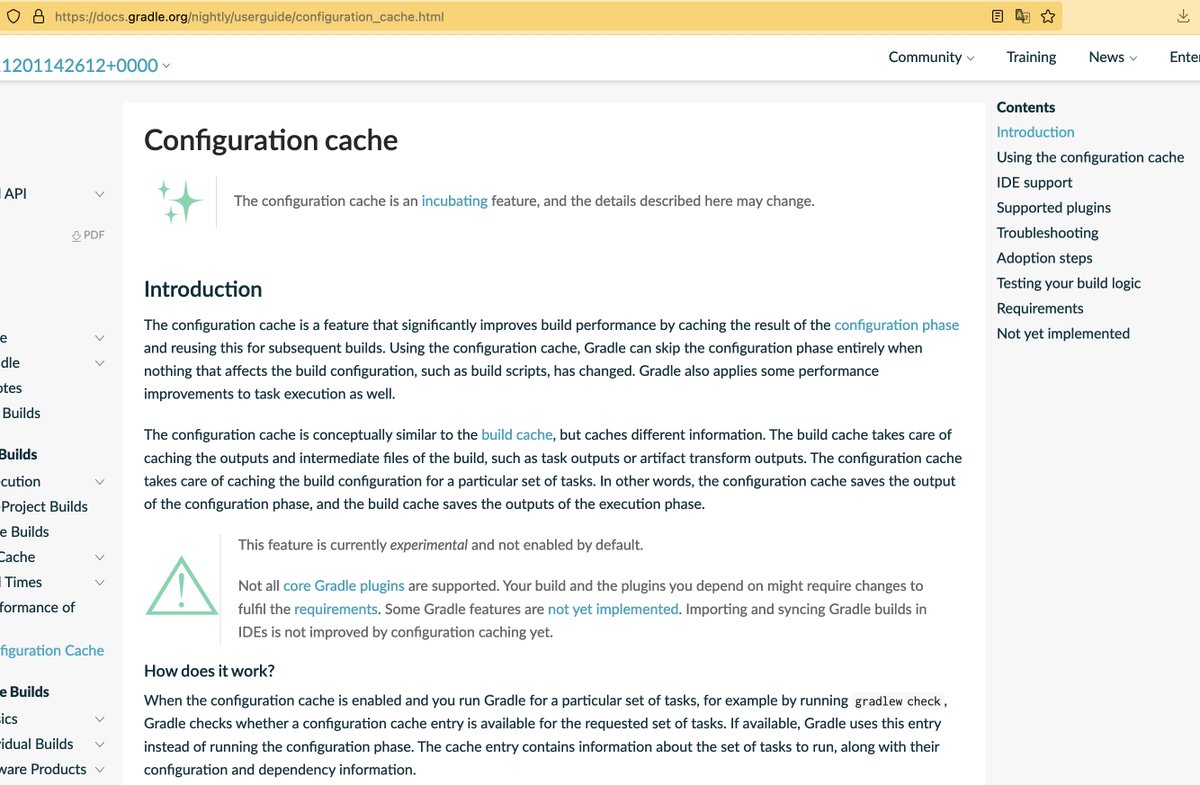
я предложил Gradle вариант оптимистичного кеширования
когда мы надеемся на отсутствие сайд эффектов в юзерском коде build.gradle и плагинах
сейчас это экспериментальная фича
docs.gradle.org/nightly/usergu…
когда мы надеемся на отсутствие сайд эффектов в юзерском коде build.gradle и плагинах
сейчас это экспериментальная фича
docs.gradle.org/nightly/usergu…
фундаментально, однако, это не полноценное решение
тк Gradle не блокирует сайд эффекты, вы можете сделать конфигурацию в зависимости от внешних факторов типа system time, env vars, файлов, сети
и налететь на баги при повторном запуске на кеше
но и эту проблему можно решить!
тк Gradle не блокирует сайд эффекты, вы можете сделать конфигурацию в зависимости от внешних факторов типа system time, env vars, файлов, сети
и налететь на баги при повторном запуске на кеше
но и эту проблему можно решить!
предлагал инженерам из Gradle использовать Java SecurityManager для ограничения доступа к сайд эффектам, но SM удаляют из JVM
альтернативно, можно подкидывать в classpath плагинов и юзер кода кастомную Java stdlib без IO функций
пока Gradle вроде ничего не делает в эту сторону
альтернативно, можно подкидывать в classpath плагинов и юзер кода кастомную Java stdlib без IO функций
пока Gradle вроде ничего не делает в эту сторону
более кардинальный вариант который я бы хотел видеть и в Gradle и в Bazel
взять Kotlin как яп конфигурации и интерпретировать его в изолированном от IO окружении, как Bazel это делает со Starlark
получим строгую статическую типизацию, компиляцию с кешированием и изоляцию
взять Kotlin как яп конфигурации и интерпретировать его в изолированном от IO окружении, как Bazel это делает со Starlark
получим строгую статическую типизацию, компиляцию с кешированием и изоляцию
предлагал это решение мейнтейнерам Bazel с которыми я тогда общался
попросили написать большой техспек, у меня из рук всё уже сыпалось к тому моменту — не сделал
Starlark хоть и крутой, но без статической типизации и гарантий в compile-time неудобный :(
попросили написать большой техспек, у меня из рук всё уже сыпалось к тому моменту — не сделал
Starlark хоть и крутой, но без статической типизации и гарантий в compile-time неудобный :(
https://twitter.com/artem_zin/status/1291205359512608769
4. параллельное выполнение билд графа aka
в 2021м это само-собой разумеещееся и есть во всех более менее живых билд системах: Bazel, Gradle, Maven, Cargo, Go Build, Sbt и тд
в 2021м это само-собой разумеещееся и есть во всех более менее живых билд системах: Bazel, Gradle, Maven, Cargo, Go Build, Sbt и тд
5. локальный билд кеш между проектами
поясню: бывает один и тот же код на одной машине компилируется в разных проектах, например, если внешние зависимости собираются из исходников
поддержка этого есть Gradle и Bazel, остальные хранят кеш на каждый проект
поясню: бывает один и тот же код на одной машине компилируется в разных проектах, например, если внешние зависимости собираются из исходников
поддержка этого есть Gradle и Bazel, остальные хранят кеш на каждый проект
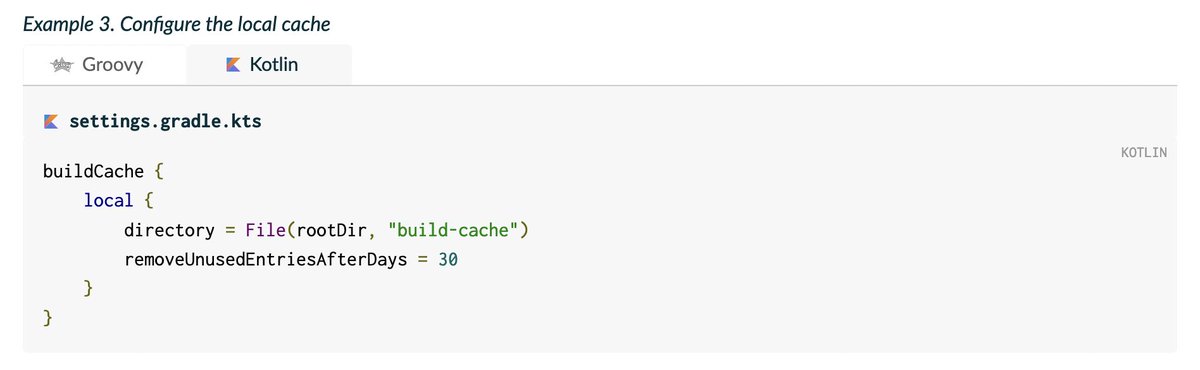
чтобы это работало корректно, билд система должна в ключ для кеша класть ещё и опции компиляции которые влияют на результат
один и тот же исходник можно скомпилировать например под разные архитектуры CPU и получить невзаимозаменяемые бинарники
оч большая проблема
один и тот же исходник можно скомпилировать например под разные архитектуры CPU и получить невзаимозаменяемые бинарники
оч большая проблема
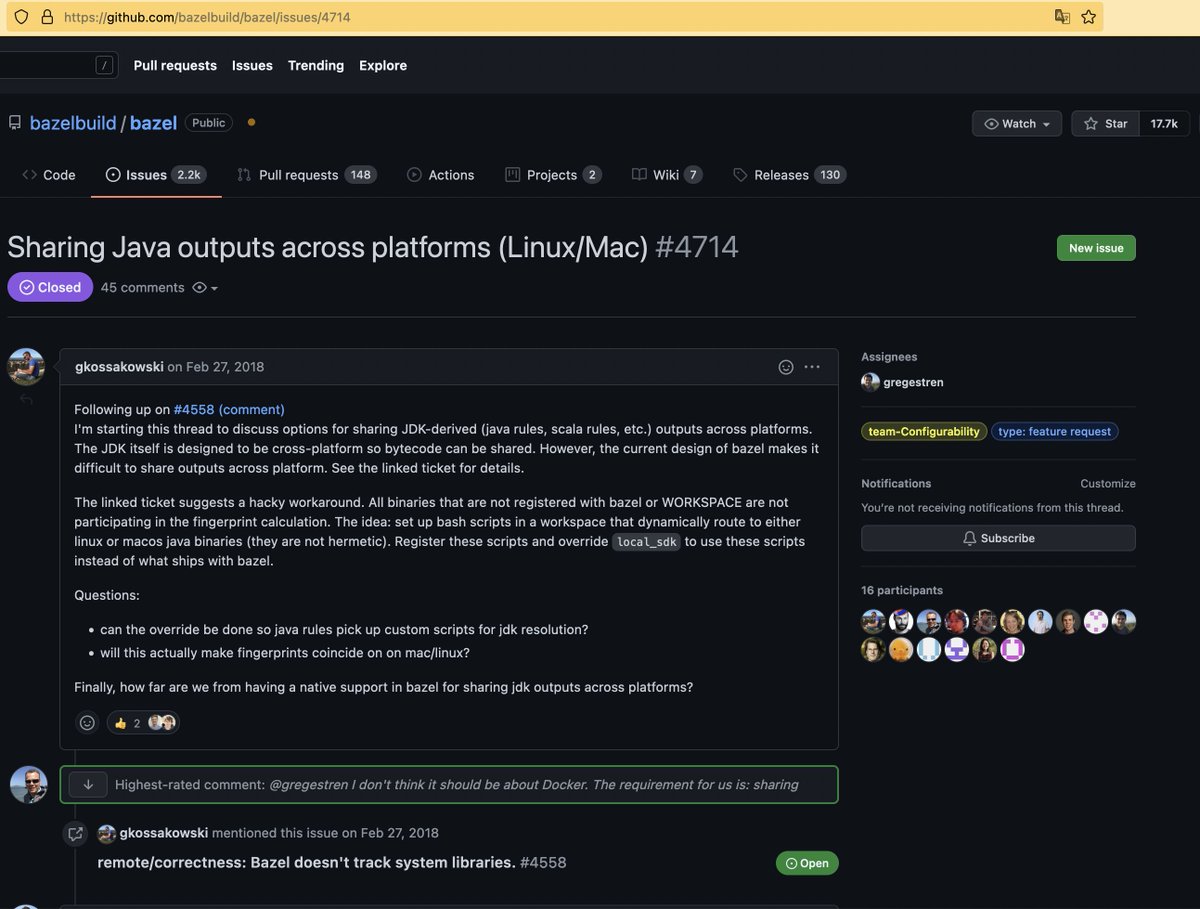
конкретно в Bazel она сейчас решается в лоб, так что host OS учитывается в билд ключе
получаем тупые ситуации в духе платформонезависимый JVM код сбилженный на Linux (например на CI) имеет другой кеш ключ по сравнению с macOS
и разработчики на маке не могут достучаться до кеша
получаем тупые ситуации в духе платформонезависимый JVM код сбилженный на Linux (например на CI) имеет другой кеш ключ по сравнению с macOS
и разработчики на маке не могут достучаться до кеша
в Lyft у нас был форк Bazel где мы исключали host OS из ключа для кеша
крайне неприятная особенность, надеюсь скоро пофиксят
в Gradle наоборот host OS и target OS не учитывается, но через build variants кешируется на разных таргетах корректно(?)
весело в общем
крайне неприятная особенность, надеюсь скоро пофиксят
в Gradle наоборот host OS и target OS не учитывается, но через build variants кешируется на разных таргетах корректно(?)
весело в общем

6. распределенный ремоут билд кеш
подходим к моему личному интересному
я плотно работал над этой штукой для Gradle, Buck и Bazel
идея простая: CI и разработчики постоянно билдят один и тот же код (кусочками: task, action, etc)
зачем это повторять на каждой машине?
подходим к моему личному интересному
я плотно работал над этой штукой для Gradle, Buck и Bazel
идея простая: CI и разработчики постоянно билдят один и тот же код (кусочками: task, action, etc)
зачем это повторять на каждой машине?
вместо этого можно иметь сетевой распределенный кеш в который билд система пишет и из которого читает
ключем будет хеш от инпутов build action, а значением его бинарный output
простая, очень эффективная идея — экономит кучу CPU time, ускоряя и CI и локальные билды
ключем будет хеш от инпутов build action, а значением его бинарный output
простая, очень эффективная идея — экономит кучу CPU time, ускоряя и CI и локальные билды
для гугла это была одна из ключевых причин разработки Bazel
чтобы десятки тысяч разработчиков и CI билдов переиспользовали результаты компиляции друг друга
а не тратили ресурсы на компиляцию одного и того же из раза в раз
кешируются разные экшены: прогоны тестов, трансформации
чтобы десятки тысяч разработчиков и CI билдов переиспользовали результаты компиляции друг друга
а не тратили ресурсы на компиляцию одного и того же из раза в раз
кешируются разные экшены: прогоны тестов, трансформации
конечно, иногда нужно оставить какой-то экшн, например, деплой как сайд эффект, но и Bazel и Gradle по умолчанию закешируют
оба предоставляют апи для исключения task/action из кеширования
но рекомендуют переосмыслить задачу, разбить на более мелкие и кешировать по максимуму
оба предоставляют апи для исключения task/action из кеширования
но рекомендуют переосмыслить задачу, разбить на более мелкие и кешировать по максимуму
распределенный ремоут билд кеш это то, что мы сейчас в Pushtorefresh делаем как первый продукт
на примере Lуft — в день моя поделка пропускала через себя неск TB трафика, c пиками в десятки тысяч запросов в секунду
большая команда, много билдов
на примере Lуft — в день моя поделка пропускала через себя неск TB трафика, c пиками в десятки тысяч запросов в секунду
большая команда, много билдов
https://twitter.com/artem_zin/status/1276614252191600641
экономически удаленный кеш это крайне целесообразная штука тк сохраняет человеко и cpu часы
надеюсь, сможем стабильно продавать и окупаться
делаем большой упор на производительность: min latency, max throughput
на этой задаче можно собаку съесть, разрабатывать in-house дорого
надеюсь, сможем стабильно продавать и окупаться
делаем большой упор на производительность: min latency, max throughput
на этой задаче можно собаку съесть, разрабатывать in-house дорого
естественно есть оупен сорс реализации
на небольших нагрузках они работают, можно и S3 использовать если по деньгам, перформансу и лимитам ок
Grаdle предоставляет это как часть их Enterprise решения, но оно оч дорогое
норм облачного я пока не видел, есть шанс быть первыми
на небольших нагрузках они работают, можно и S3 использовать если по деньгам, перформансу и лимитам ок
Grаdle предоставляет это как часть их Enterprise решения, но оно оч дорогое
норм облачного я пока не видел, есть шанс быть первыми
планирую запустить в двух режимах:
free с лимитами для оупен сорс проектов
paid для коммерческих клиентов, выбираешь сколько нужно места, регион, рейт лимиты
→ ускорение билдов!
self-hosted может позже, сложно упаковать в удобный для распределенного деплоя и обновлений
free с лимитами для оупен сорс проектов
paid для коммерческих клиентов, выбираешь сколько нужно места, регион, рейт лимиты
→ ускорение билдов!
self-hosted может позже, сложно упаковать в удобный для распределенного деплоя и обновлений
как мы оптимизируем latency и throughput на бекенде:
- только NVMe диски
- non-blocking IO (io_uring) оч рад что нашел человека который по этому тоже загоняется
- альфа на Kotlin JVM, бета на Rust -> уберем GC паузы, будем профилировать конечно
- аккуратная работа с БД
- только NVMe диски
- non-blocking IO (io_uring) оч рад что нашел человека который по этому тоже загоняется
- альфа на Kotlin JVM, бета на Rust -> уберем GC паузы, будем профилировать конечно
- аккуратная работа с БД
7. трейсинг и профайлинг конфигурации и билд графа
во многих билд системах хорошо если время в логах есть
а вот Bazel и Gradle молодцы
у Bazel мега крутой трейсинг в формате Chrome Trace
у Gradle есть Build Scan и gradle-profiler
тк оба на JVM можно цеплять JVM профайлеры
во многих билд системах хорошо если время в логах есть
а вот Bazel и Gradle молодцы
у Bazel мега крутой трейсинг в формате Chrome Trace
у Gradle есть Build Scan и gradle-profiler
тк оба на JVM можно цеплять JVM профайлеры
тулкит для профайлинга билда это критический инструмент для средних-больших проектов
у меня коллега 8 месяцев потратил на свое решение, чтобы анализировать проблемные места
без данных это гадание на кофейной гуще, легко потратить время на оптимизацию того, что не так важно
у меня коллега 8 месяцев потратил на свое решение, чтобы анализировать проблемные места
без данных это гадание на кофейной гуще, легко потратить время на оптимизацию того, что не так важно
оптимизации для инфраструктурных команды build eng и devops — большИй кусок работы после введения системы в эксплуатацию
дорогущий Grаdle Enterprise в этом плане комплексно решает проблему тк централизованно собирает статистику
для других систем надо велосипедить
дорогущий Grаdle Enterprise в этом плане комплексно решает проблему тк централизованно собирает статистику
для других систем надо велосипедить
удивлен шо JеtBrains до сих пор не предоставили какой-то аналог Google Analytics для разработчиков
могут очень много данных из IntelliJ собирать и классифицировать как по билдам так и по работе с кодом
мы делали кастомную аналитику для тулинга, это больно
могут очень много данных из IntelliJ собирать и классифицировать как по билдам так и по работе с кодом
мы делали кастомную аналитику для тулинга, это больно
периодически задумываюсь может стоит как второй коммерческий проект Pushtorefresh сделать
но раз за разом прихожу к осознанию
шо аналитика уровня Google Analytics и Я Метрики оч сложная задача по хранению и анализу огромного кол-ва данных
есть другие low hanging fruits
но раз за разом прихожу к осознанию
шо аналитика уровня Google Analytics и Я Метрики оч сложная задача по хранению и анализу огромного кол-ва данных
есть другие low hanging fruits
8. строгое версионирование и верификация зависимостей
меня как-то раскритиковали Go-шники, за мой наезд на то что у них зависимости тянутся как гит репозитории просто с мастер ветки
и есть КОНВЕНЦИЯ шо не надо ломать совместимость и пожалуйста не внедряйте бэкдоры
треш
меня как-то раскритиковали Go-шники, за мой наезд на то что у них зависимости тянутся как гит репозитории просто с мастер ветки
и есть КОНВЕНЦИЯ шо не надо ломать совместимость и пожалуйста не внедряйте бэкдоры
треш
с тех пор воды утекло, почти все билд системы позволяют четко указать версии зависимостей
генерируют dependencies-lock файл, в котором их version solver вычисляет какую версию конкретной зависимости нужно использовать
+ проверка подписи, шобы не подсунули фейк
и хорошо
генерируют dependencies-lock файл, в котором их version solver вычисляет какую версию конкретной зависимости нужно использовать
+ проверка подписи, шобы не подсунули фейк
и хорошо
без фиксированных версий зависимостей я не знаю как спать по ночам
когда любой следующий билд может получить более новую версию какой-то библиотеки
и ваш продукт уйдет в прод с неизвестными багами, а еще хуже с какими-нибудь бекдорами или уязвимостями
фиксируйтесь!
когда любой следующий билд может получить более новую версию какой-то библиотеки
и ваш продукт уйдет в прод с неизвестными багами, а еще хуже с какими-нибудь бекдорами или уязвимостями
фиксируйтесь!
то же самое относится к удалению зависимостей из централизованных репозиториев
известный случай в JS комьюнити — удаление библиотеки left-pad из NPM Registry
чел снес 17 строчек кода и на несколько дней поставил тысячи JS команд в состояние — у нас не работает билд
безумие
известный случай в JS комьюнити — удаление библиотеки left-pad из NPM Registry
чел снес 17 строчек кода и на несколько дней поставил тысячи JS команд в состояние — у нас не работает билд
безумие
с тех пор большинство подобных репозиториев приняли политику
шо библиотеку с реальным использованиями нельзя удалить, кроме случаев когда там вредоносный код или шото около того
также решается self-hosted репозиторием артефактов типа Artifactory от JFrog, который хранит копии
шо библиотеку с реальным использованиями нельзя удалить, кроме случаев когда там вредоносный код или шото около того
также решается self-hosted репозиторием артефактов типа Artifactory от JFrog, который хранит копии
9. легковесная контейнерезация окружения выполнения
для разных build action/task нужно разное окружение: какие-то SDK, утилиты определенных версий в PATH и тп
условно говоря, это то что дает Docker: повторяемое окружение для программы
afaik это нет ни в одной из билд систем
для разных build action/task нужно разное окружение: какие-то SDK, утилиты определенных версий в PATH и тп
условно говоря, это то что дает Docker: повторяемое окружение для программы
afaik это нет ни в одной из билд систем
и это задача разработчиков или билд инженеров поддерживать локальное и CI окружение в нужном состоянии для успешного билда
задача паршивая, часто это macOS/Windows у разработчиков, Linux на CI
Docker спасибо за всё легенда
хочется на action иметь возможность указать image
задача паршивая, часто это macOS/Windows у разработчиков, Linux на CI
Docker спасибо за всё легенда
хочется на action иметь возможность указать image
это оч больно мейнтейнить в больших командах
я писал тулы и скрипты чисто для этой проблемы, шобы при вызове билда у разработчика быстро проверить все ли пакеты нужных версий есть или доставить
все это версионировалось с проектом в VCS
я писал тулы и скрипты чисто для этой проблемы, шобы при вызове билда у разработчика быстро проверить все ли пакеты нужных версий есть или доставить
все это версионировалось с проектом в VCS
на CI естественно контнейнеры
в Lуft я перед уходом сделал CI на k8s с разными версионированными образами на разные задачи и динамическим шедулингом и автоскейлингом
он стал летать и потреблять 10x меньше денег в месяц, но менеджмент не особо оценил :/
в Lуft я перед уходом сделал CI на k8s с разными версионированными образами на разные задачи и динамическим шедулингом и автоскейлингом
он стал летать и потреблять 10x меньше денег в месяц, но менеджмент не особо оценил :/
https://twitter.com/artem_zin/status/1275704502671364101
делал на основе BuildKite CI и вот этого плагина для шедулинга на k8s
вдоль и поперек пришлось переписать налетая на проблемы, все мои наработки сейчас доступны для всех
имхо это как должны работать современные CI системы
github.com/EmbarkStudios/…
вдоль и поперек пришлось переписать налетая на проблемы, все мои наработки сейчас доступны для всех
имхо это как должны работать современные CI системы
github.com/EmbarkStudios/…
10. JSON/etc вывод для интеграции с IDE и другим тулингом
шо это и зачем: некий набор команд для интроспекции проекта
типа build-system project-info --output json
шобы другой тулинг, например, IDE могла их вызывать и на основе этих данных построить свою модель проекта и тп
шо это и зачем: некий набор команд для интроспекции проекта
типа build-system project-info --output json
шобы другой тулинг, например, IDE могла их вызывать и на основе этих данных построить свою модель проекта и тп
в Bazel это сделано лучше всего
там есть и команды query и возможность выполнить код для интроспекции (aspect)
так Bazel IntelliJ плагин синхронизирует проектную модель с IntelliJ
в Gradle это делается путем внезапно сокет соединения с демоном или плагинами
там есть и команды query и возможность выполнить код для интроспекции (aspect)
так Bazel IntelliJ плагин синхронизирует проектную модель с IntelliJ
в Gradle это делается путем внезапно сокет соединения с демоном или плагинами
в остальных системах часто приходится парсить текстовый аутпут или вообще повторять их парсинг билд файлов
в Bazel же можно делать ЗАПРОСЫ о проекте, буквально почти SQL: пересечения, исключения и тп, гениально
на масштабах гугла и яндекса это очень полезно в монорепозиториях
в Bazel же можно делать ЗАПРОСЫ о проекте, буквально почти SQL: пересечения, исключения и тп, гениально
на масштабах гугла и яндекса это очень полезно в монорепозиториях
на основе Bazel query можно делать оч прикольные вещи
например на CI кверим все таргеты с нужными атрибутами, бьем их на куски и динамически шедулим шарды на CI кластер
собсно я такой шардинг и делал, к распределенному выполнению еще вернусь
в других системах это сложно
например на CI кверим все таргеты с нужными атрибутами, бьем их на куски и динамически шедулим шарды на CI кластер
собсно я такой шардинг и делал, к распределенному выполнению еще вернусь
в других системах это сложно
11. мониторинг файловой системы и NON-Blocking IO
современная билд система должна хукаться в механизмы ОС по мониторингу изменений файлов
это нужно, шобы при запуске билда она быстро понимала что в проекте поменялось и отсекала проверку всех файлов на изменения
современная билд система должна хукаться в механизмы ОС по мониторингу изменений файлов
это нужно, шобы при запуске билда она быстро понимала что в проекте поменялось и отсекала проверку всех файлов на изменения
неблокирующая работа с файлами и сокетами нужна для эффективной утилизации CPU, минимизации сисколлов из билд системы в ядро и тп
io_uring, epoll, kqueue и шо там на шиндоус
Bazel тут ок, Gradle so so, у остальных где как
io_uring, epoll, kqueue и шо там на шиндоус
Bazel тут ок, Gradle so so, у остальных где как
12. распределенное ремоутное выполнение билда на кластере машин с контейнерезацией окружения выполнения
подбираемся к самому прикольному и сложному
зачем полагаться на слабый комп разработчика или покупать им $$ машины
если можно выполнять билд на распределенном кластере машин
подбираемся к самому прикольному и сложному
зачем полагаться на слабый комп разработчика или покупать им $$ машины
если можно выполнять билд на распределенном кластере машин
в 2016 в Juno меня бесили медленные билды на 13 макбуке
но менять на 15шку я не хотел да и не особо они быстрее
родиласть простейшая идея:
1. копируем файлы на мощный сервер
2. по ssh выполняем билд команду
3. копируем файлы обратно
так появился github.com/buildfoundatio…
но менять на 15шку я не хотел да и не особо они быстрее
родиласть простейшая идея:
1. копируем файлы на мощный сервер
2. по ssh выполняем билд команду
3. копируем файлы обратно
так появился github.com/buildfoundatio…
я пробовал разные варианты синхронизации файлов между сервером и локальной машиной:
NFS и похожие штуки, scp, rsync
rsync своей инкрементальностью и простотой рвал всё и вся, за секунды тягая диффы на тысячи файлов
мне легко выделили стоимость одного макбука на железо сервера
NFS и похожие штуки, scp, rsync
rsync своей инкрементальностью и простотой рвал всё и вся, за секунды тягая диффы на тысячи файлов
мне легко выделили стоимость одного макбука на железо сервера
и все 10 андроид разработчиков быстро пересели на Mainframer, ускорив сборку в несколько раз
бонусом стала возможность работы в офисе на крыше или кухне, тк ноут не разряжался за час
я балдел, один сервер тянул 10 человек без проблем
многие компании до сих пор используют
бонусом стала возможность работы в офисе на крыше или кухне, тк ноут не разряжался за час
я балдел, один сервер тянул 10 человек без проблем
многие компании до сих пор используют
бывший коллега, мы никогда и не общались, написал как-то в ЖЖ критику этой моей поделки 🙃
я с ним согласен, Mainframer простой как две копейки, и это замечательно
там конечн есть и config, localignore, remoteignore файлы и параллельность, но да
theiced.livejournal.com/499970.html
я с ним согласен, Mainframer простой как две копейки, и это замечательно
там конечн есть и config, localignore, remoteignore файлы и параллельность, но да
theiced.livejournal.com/499970.html
ему безразлична система сборки, яп и тп
нужно просто рабочее окружение на удаленной машине и можно запускать билд удаленно
пример использования выглядит так:
mainframer ./gradlew test
какие то ребята написали IntelliJ плагин, и другие варианты более плотной интеграции
нужно просто рабочее окружение на удаленной машине и можно запускать билд удаленно
пример использования выглядит так:
mainframer ./gradlew test
какие то ребята написали IntelliJ плагин, и другие варианты более плотной интеграции
в самих системах сборки есть наработки по удаленному выполнению
state of the art сейчас это Bazel Remote Execution:
каждый билд action передает свои input файлы в кластер, там он шедулится, выполняется, и возвращается клиенту, все это параллельно + ремоут кеш
state of the art сейчас это Bazel Remote Execution:
каждый билд action передает свои input файлы в кластер, там он шедулится, выполняется, и возвращается клиенту, все это параллельно + ремоут кеш
какое-то время гугл предоставлял облачный сервис для этого на базе Google Cloud Platform, но потом свернули как нерентабельный
внутри гугла это естественно работает и десятки тысяч их разработчиков билдят ремоутно
есть оупен сорс реализации, но задача сложная и кластерная
внутри гугла это естественно работает и десятки тысяч их разработчиков билдят ремоутно
есть оупен сорс реализации, но задача сложная и кластерная
Gradle пока предоставляет только распределенное выполнение тестов
но не билда, это будет позже
но не билда, это будет позже
есть наработки и в других билд системах, например, distcpp для плюсов
в идеале вы покупаете это как любой другой облачный сервис
прописываете в конфиге билда настройки для соединения
и получаете перформанс кластера на вашем ноутбуке
Bazel наиболее близкая к этому система
CI в таком варианте тоже может быть тонким клиентом этого кластера
прописываете в конфиге билда настройки для соединения
и получаете перформанс кластера на вашем ноутбуке
Bazel наиболее близкая к этому система
CI в таком варианте тоже может быть тонким клиентом этого кластера
но повторюсь, эффективный менеджмент контейнеров в кластере, шедулинг, сетевые задержки и производительность реально сложные проблемы
короче говоря, это сложно сделать и продать за деньги не сильно больше аренды виртуалок у всяких AWS
гугл решил не продавать
короче говоря, это сложно сделать и продать за деньги не сильно больше аренды виртуалок у всяких AWS
гугл решил не продавать
в общем с большего пока всё шо я хотел сказать про современные билд системы
вроде довольно систематизированно, материала тут на несколько докладов
распространите среди жителей жека, особенно если они из JetBrains наконец делают JetBrains Build Tool хыы
вроде довольно систематизированно, материала тут на несколько докладов
распространите среди жителей жека, особенно если они из JetBrains наконец делают JetBrains Build Tool хыы
14. инкрементальная компиляция
совершенно забыл, это оч сложная тема
в некоторых яп это частично умеет компилятор — кормим предыдущий и новый стейт, он сам диффит
например, Kotlin
в других — компилятор простой и билд система если хочет делает дифф и кормит ему
— Java
совершенно забыл, это оч сложная тема
в некоторых яп это частично умеет компилятор — кормим предыдущий и новый стейт, он сам диффит
например, Kotlin
в других — компилятор простой и билд система если хочет делает дифф и кормит ему
— Java
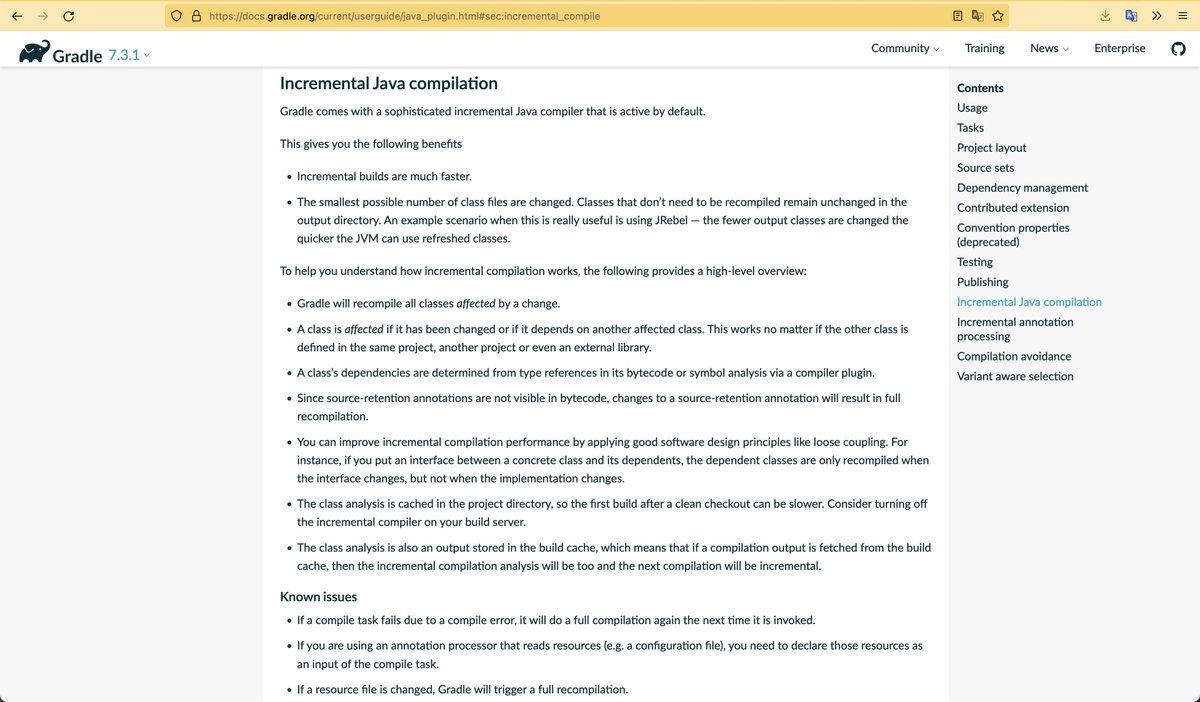
в Bazel инкрементальную компиляцию считают внимание ОПАСНОСТЬЮ
тк сложно гарантировать корректность диффа, стейта компилятора и повторяемость сборки
поэтому все известные интеграции компиляторов там неикнрементальны: Java, Kotlin, Rust, C++, TypeScript
тк сложно гарантировать корректность диффа, стейта компилятора и повторяемость сборки
поэтому все известные интеграции компиляторов там неикнрементальны: Java, Kotlin, Rust, C++, TypeScript
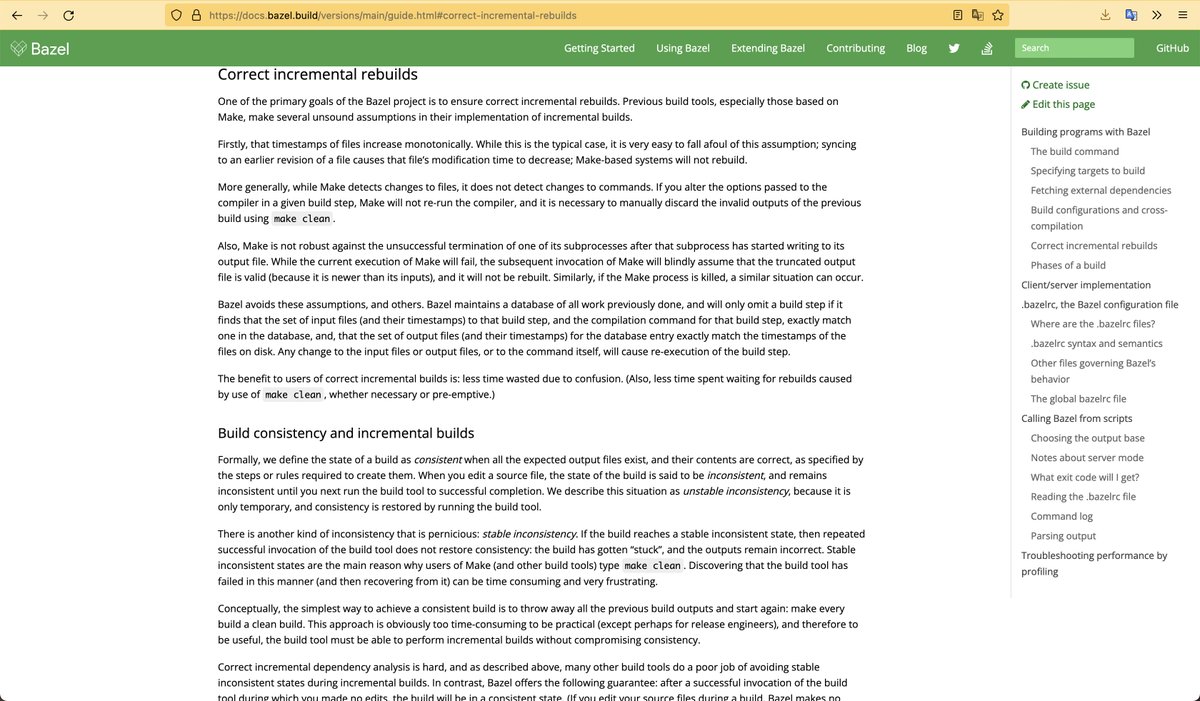
поэтому иметь модуль с большим количеством кода в Bazel плохо
— он будет полностью перекомпилироваться на малейших изменениях
рекомендуется дробить проект на большое кол-во модулей
в Gradle оч крутая инкрементальная компиляция Java и Kotlin
— он будет полностью перекомпилироваться на малейших изменениях
рекомендуется дробить проект на большое кол-во модулей
в Gradle оч крутая инкрементальная компиляция Java и Kotlin
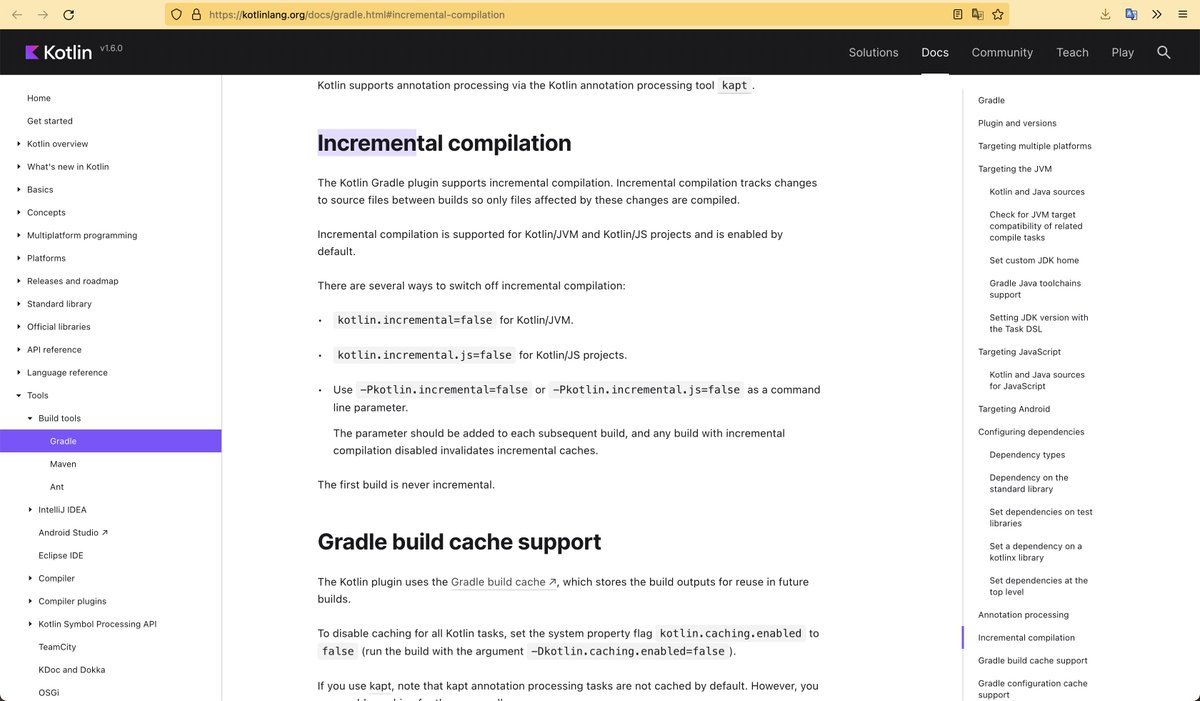
но, в Bazel есть концепция Persistent Workers — демоны для тулов
через них некоторые рулы реализуют stateful компиляцию
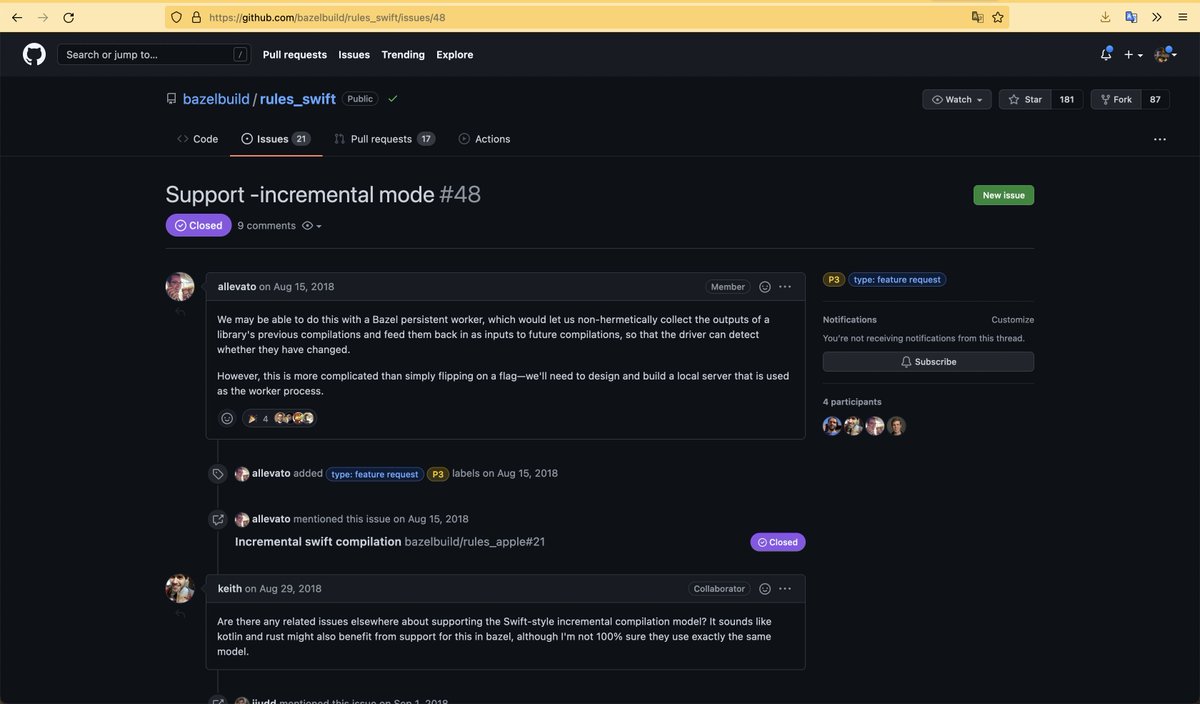
вспомнил шо у моих iOS коллег были большие перформас проблемы с компиляцией Swift
и они работали над поддержкой инкрементальности в rules_swift
через них некоторые рулы реализуют stateful компиляцию
вспомнил шо у моих iOS коллег были большие перформас проблемы с компиляцией Swift
и они работали над поддержкой инкрементальности в rules_swift
• • •
Missing some Tweet in this thread? You can try to
force a refresh


