🔥2 New Super Models to Handle Any Type of Dataset
We build models optimized for a specific type of dataset like:
- text
- audio
- computer vision
- etc.
Is it possible to create a general model? @DeepMind unveils the answer.
1/7
We build models optimized for a specific type of dataset like:
- text
- audio
- computer vision
- etc.
Is it possible to create a general model? @DeepMind unveils the answer.
1/7


Recently, DeepMind published two papers about general-purpose architectures that can process different types of input datasets.
1) Perceiver supports any kind of input
2) Perceiver IO supports any kind of output
2/7
1) Perceiver supports any kind of input
2) Perceiver IO supports any kind of output
2/7
Perceivers can handle new types of data with only minimal modifications.
They process inputs using domain-agnostic Transformer-style attention.
Perceiver IO matches a Transformer-based BERT baseline on the GLUE language benchmark.
3/7
They process inputs using domain-agnostic Transformer-style attention.
Perceiver IO matches a Transformer-based BERT baseline on the GLUE language benchmark.
3/7
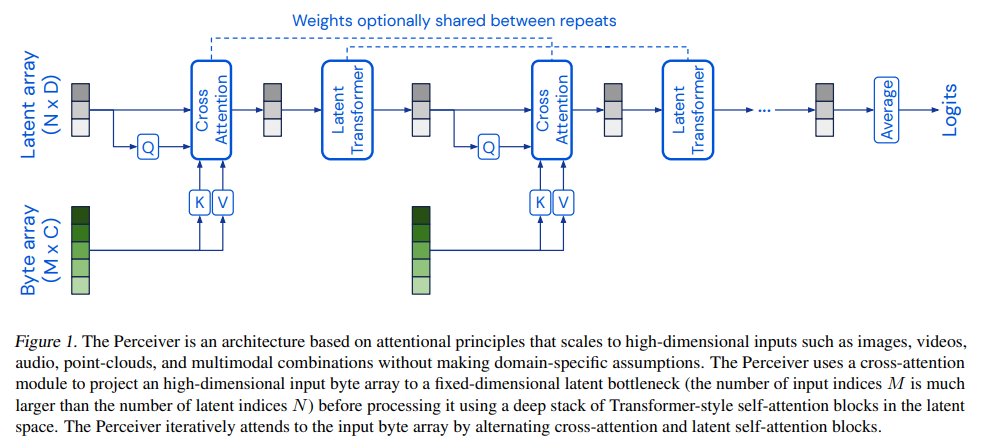
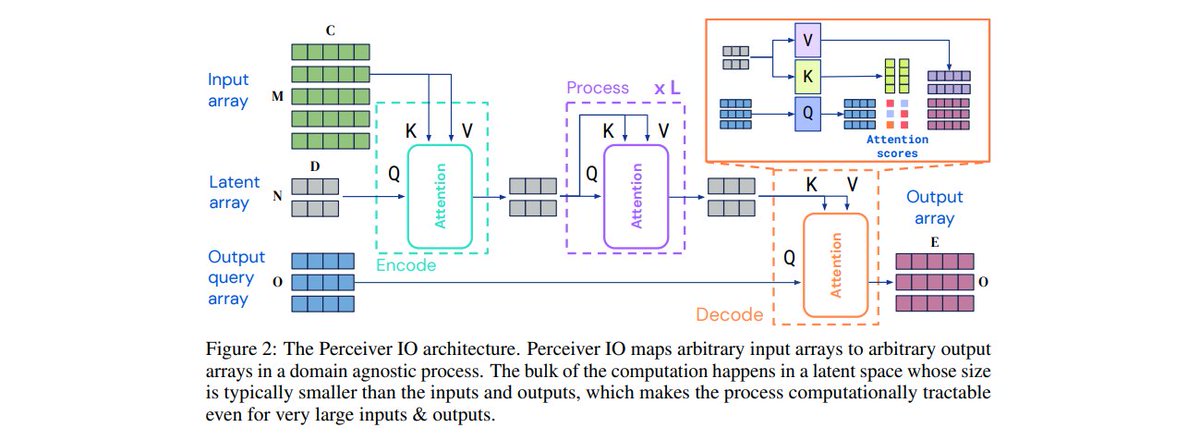
Unlike Transformers, Perceivers first map inputs to a small latent space where processing is cheap and doesn't depend on the input size.
See the architectures of both Perceiver (pic 1) and Perceiver IO (pic 2).
4/7
See the architectures of both Perceiver (pic 1) and Perceiver IO (pic 2).
4/7
Results:
Perceiver outperforms strong, specialized models on classification tasks across various modalities:
- images
- point clouds
- audio
- video
- video+audio.
5/7
Perceiver outperforms strong, specialized models on classification tasks across various modalities:
- images
- point clouds
- audio
- video
- video+audio.
5/7
Perceiver IO achieves strong results on tasks with highly structured output spaces, such as:
- natural language
- visual understanding
- StarCraft II
- multi-task and multi-modal domains.
6/7
- natural language
- visual understanding
- StarCraft II
- multi-task and multi-modal domains.
6/7
Thanks for learning ML and AI with us!
If you are curious about general-purpose architectures, here is the link for you: github.com/deepmind/deepm…
Share this thread with your friends and spread the open ML knowledge!
7/7
If you are curious about general-purpose architectures, here is the link for you: github.com/deepmind/deepm…
Share this thread with your friends and spread the open ML knowledge!
7/7
• • •
Missing some Tweet in this thread? You can try to
force a refresh