The ongoing consolidation in AI is incredible. Thread: ➡️ When I started ~decade ago vision, speech, natural language, reinforcement learning, etc. were completely separate; You couldn't read papers across areas - the approaches were completely different, often not even ML based.
In 2010s all of these areas started to transition 1) to machine learning and specifically 2) neural nets. The architectures were diverse but at least the papers started to read more similar, all of them utilizing large datasets and optimizing neural nets.
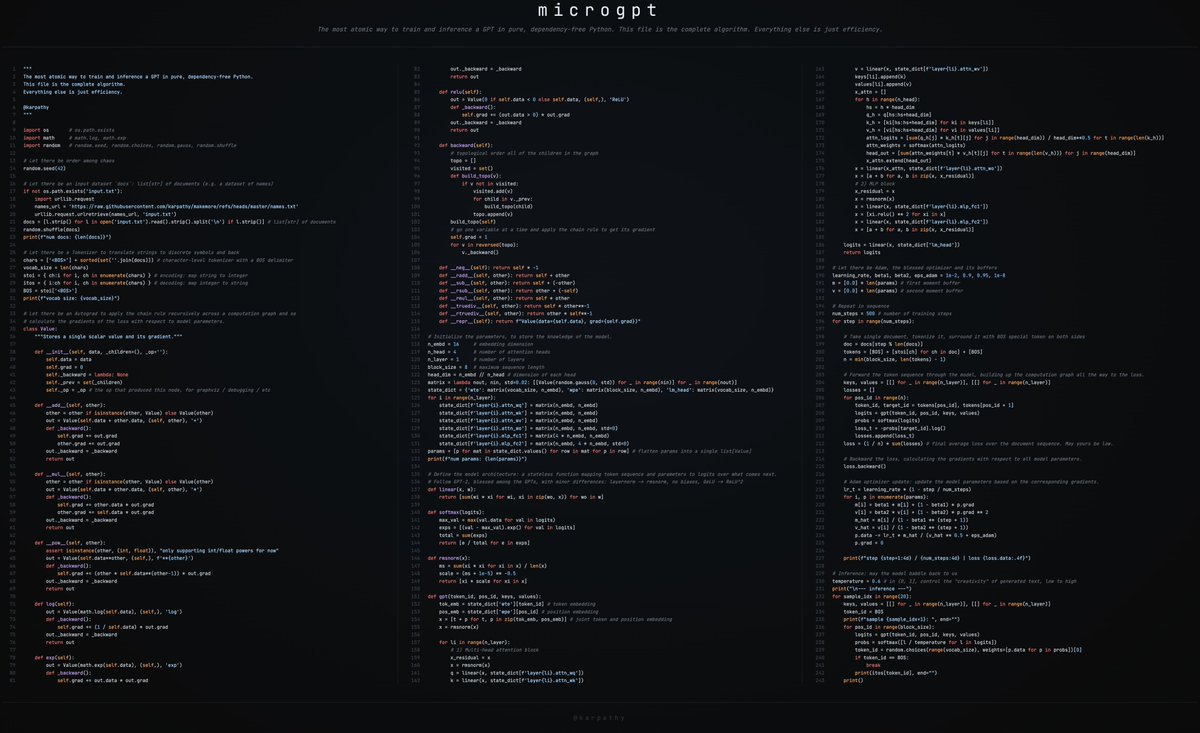
But as of approx. last two years, even the neural net architectures across all areas are starting to look identical - a Transformer (definable in ~200 lines of PyTorch github.com/karpathy/minGP…), with very minor differences. Either as a strong baseline or (often) state of the art.
You can feed it sequences of words. Or sequences of image patches. Or sequences of speech pieces. Or sequences of (state, action, reward) in reinforcement learning. You can throw in arbitrary other tokens into the conditioning set - an extremely simple/flexible modeling framework
Even within areas (like vision), there used to be some differences in how you do classification, segmentation, detection, generation, but all of these are also being converted to the same framework. E.g. for detection take sequence of patches, output sequence of bounding boxes.
The distinguishing features now mostly include 1) the data, and 2) the Input/Output spec that maps your problem into and out of a sequence of vectors, and sometimes 3) the type of positional encoder and problem-specific structured sparsity pattern in the attention mask.
So even though I'm technically in vision, papers, people and ideas across all of AI are suddenly extremely relevant. Everyone is working with essentially the same model, so most improvements and ideas can "copy paste" rapidly across all of AI.
As many others have noticed and pointed out, the neocortex has a highly uniform architecture too across all of its input modalities. Perhaps nature has stumbled by a very similar powerful architecture and replicated it in a similar fashion, varying only some of the details.
This consolidation in architecture will in turn focus and concentrate software, hardware, and infrastructure, further speeding up progress across AI. Maybe this should have been a blog post. Anyway, exciting times.
• • •
Missing some Tweet in this thread? You can try to
force a refresh