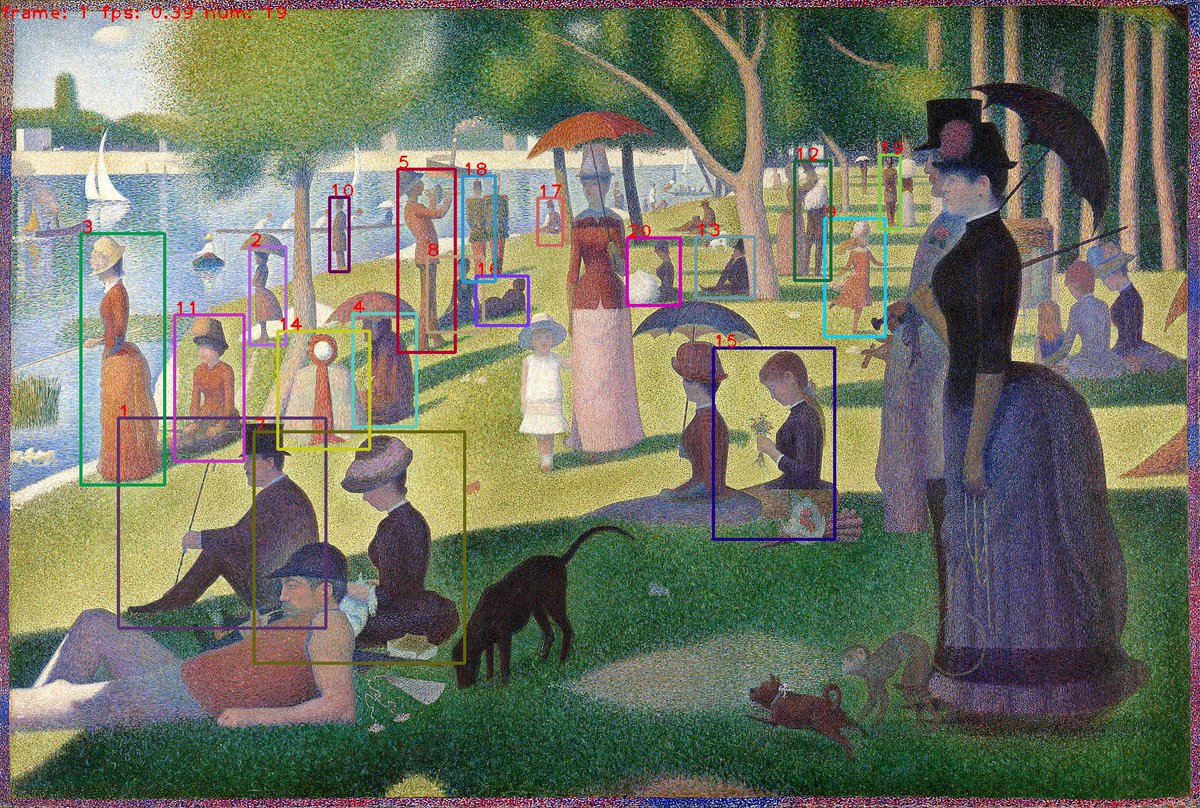GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
abs: arxiv.org/abs/2112.10741
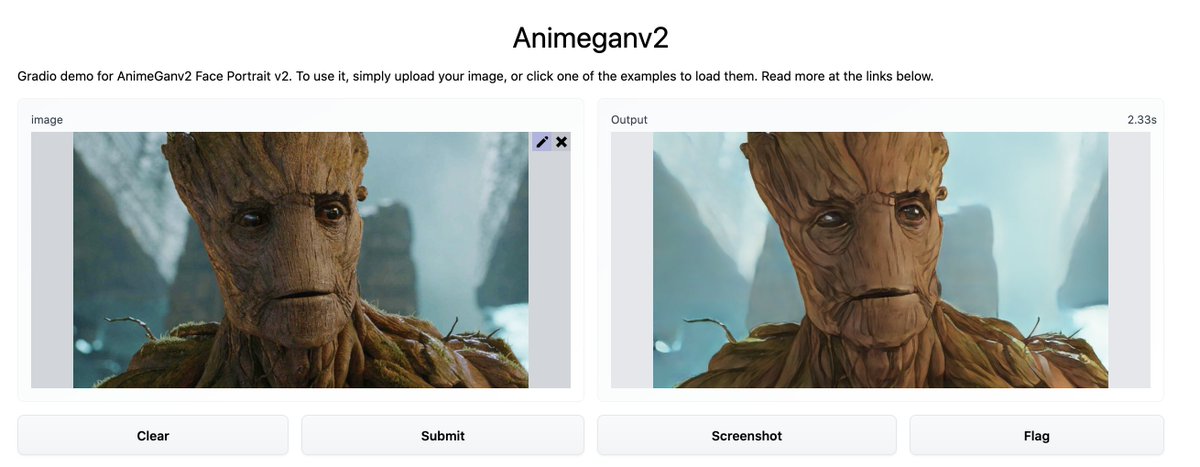
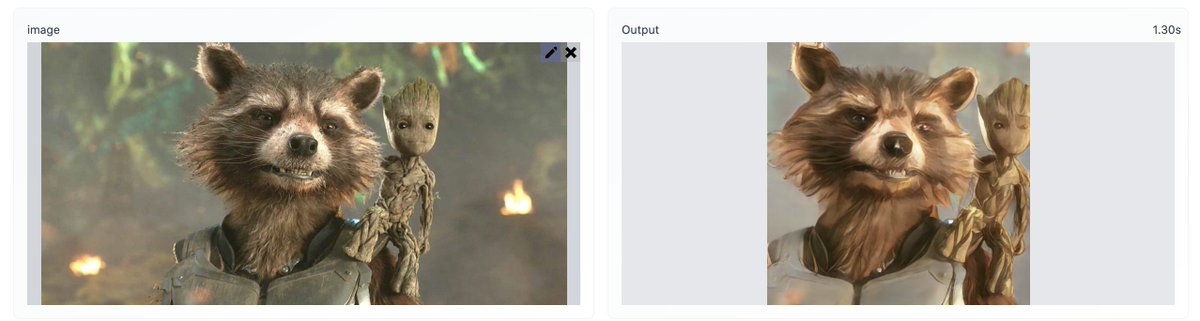
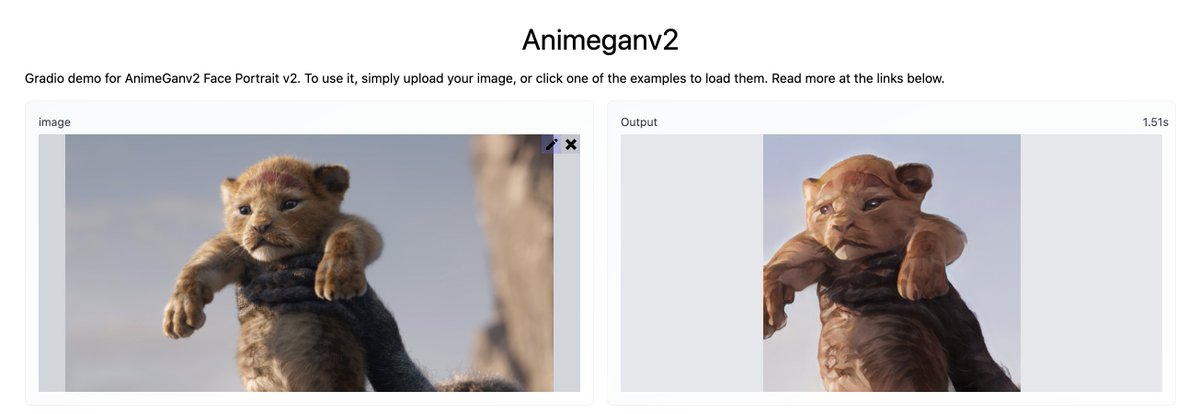
Samples from a 3.5B parameter text-conditional diffusion model using classifier free guidance are favored by human evaluators to those from DALL-E
abs: arxiv.org/abs/2112.10741
Samples from a 3.5B parameter text-conditional diffusion model using classifier free guidance are favored by human evaluators to those from DALL-E

Text-conditional image inpainting examples from GLIDE. The green region is erased, and the model fills it in conditioned on the given prompt. model is able to match the style and lighting of the surrounding context to produce a realistic completion.

Random image samples on MS-COCO prompts. For XMC-GAN,take samples from Zhang et al. (2021). For DALL-E, generate samples at temperature 0.85 and select the best of 256 using CLIP reranking. For GLIDE, use CLIP guidance with scale 2.0 and classifier-free guidance with scale 3.0.

github: github.com/openai/glide-t…
text2im notebook: github.com/openai/glide-t…
# This notebook supports both CPU and GPU.
# On CPU, generating one sample may take on the order of 20 minutes.
# On a GPU, it should be under a minute.
text2im notebook: github.com/openai/glide-t…
# This notebook supports both CPU and GPU.
# On CPU, generating one sample may take on the order of 20 minutes.
# On a GPU, it should be under a minute.
• • •
Missing some Tweet in this thread? You can try to
force a refresh