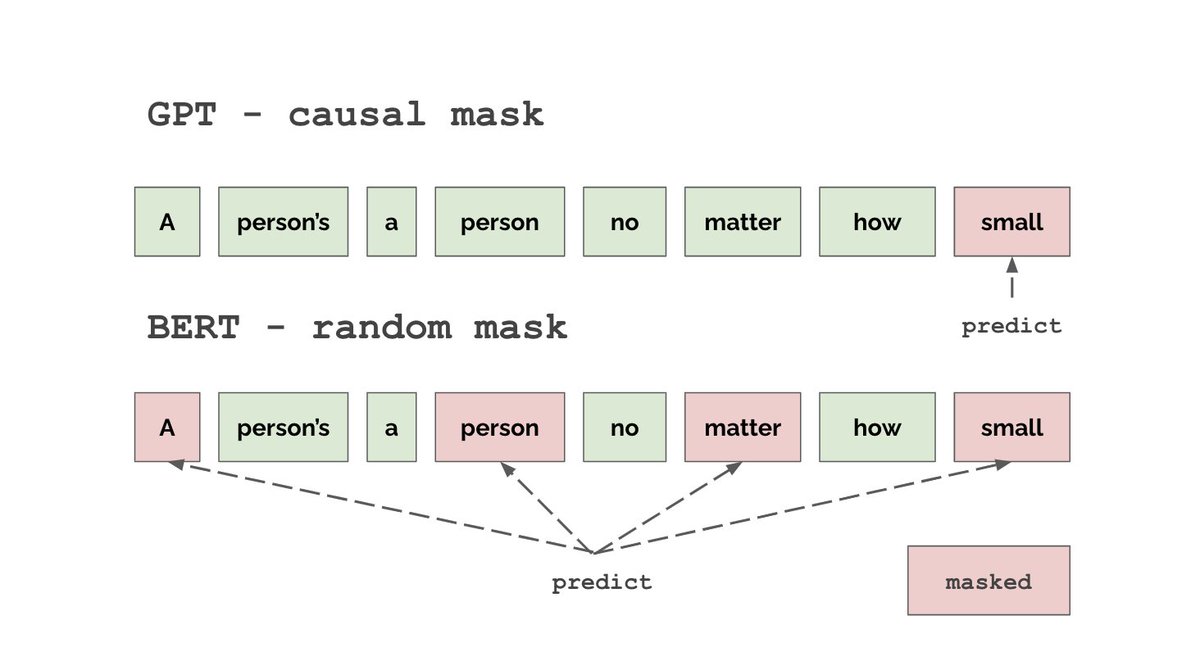
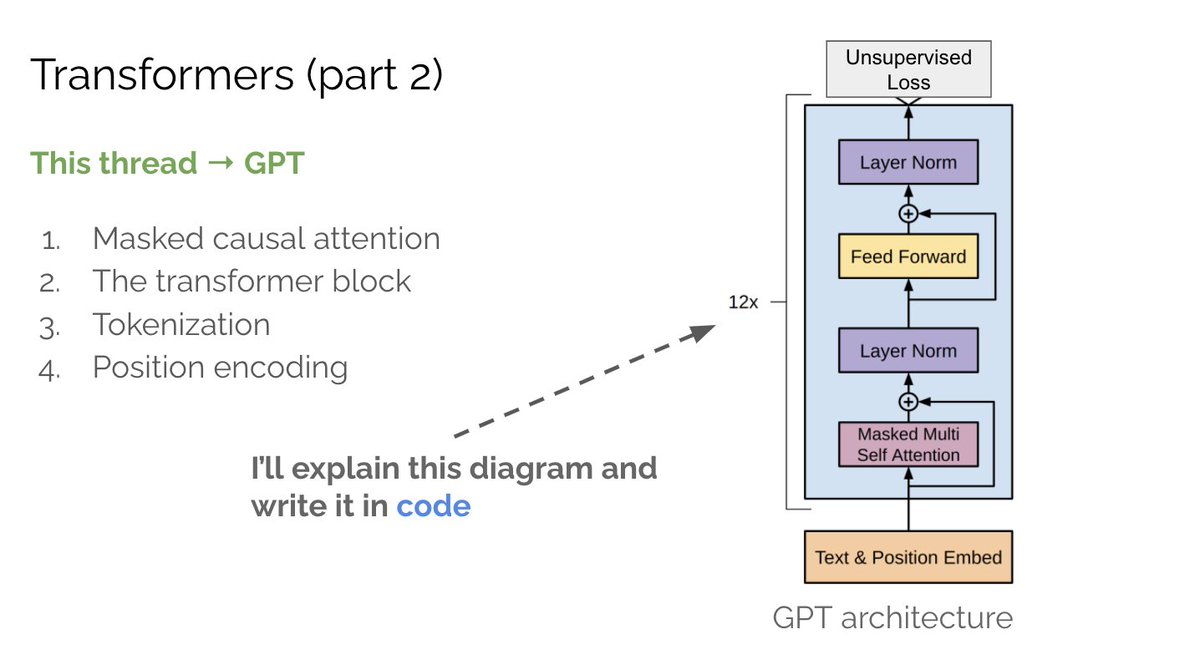
Transformers are arguably the most impactful deep learning architecture from the last 5 yrs.
In the next few threads, we’ll cover multi-head attention, GPT and BERT, Vision Transformer, and write these out in code. This thread → understanding multi-head attention.
1/n
In the next few threads, we’ll cover multi-head attention, GPT and BERT, Vision Transformer, and write these out in code. This thread → understanding multi-head attention.
1/n
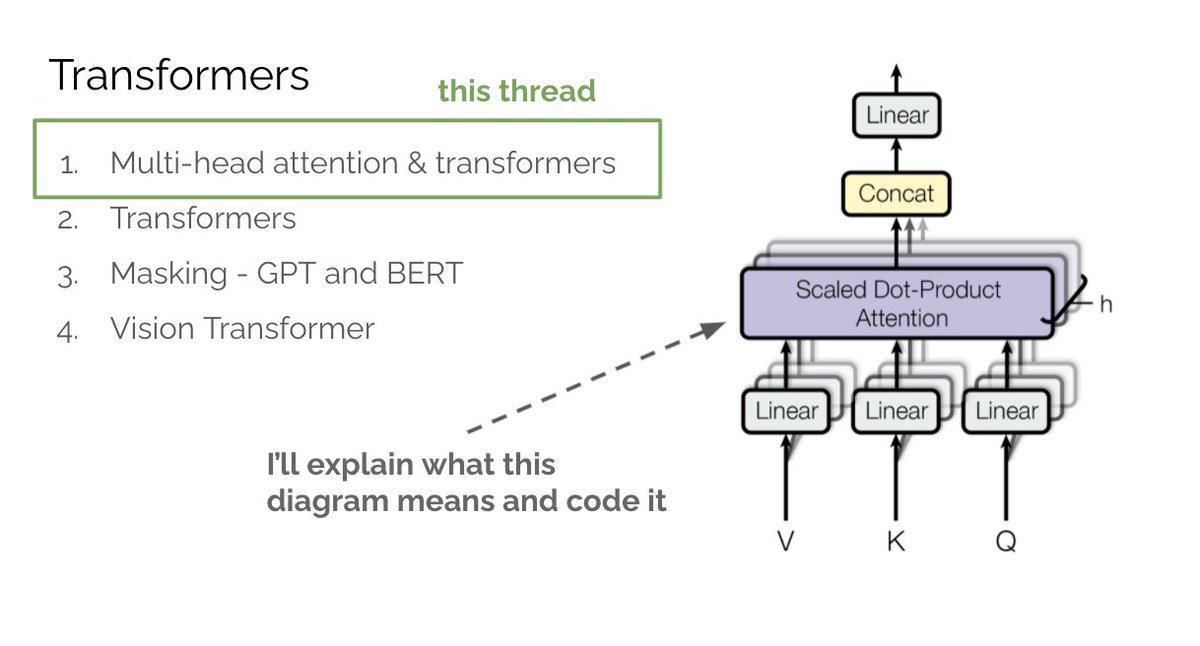
What is attention? Say you want to classify the sentiment of “attention is not too shabby.“ “shabby” suggests 😞 but “not” actually means it's 😀. To correctly classify you need to look at all the words in the sentence. How can we achieve this?
2/n
2/n
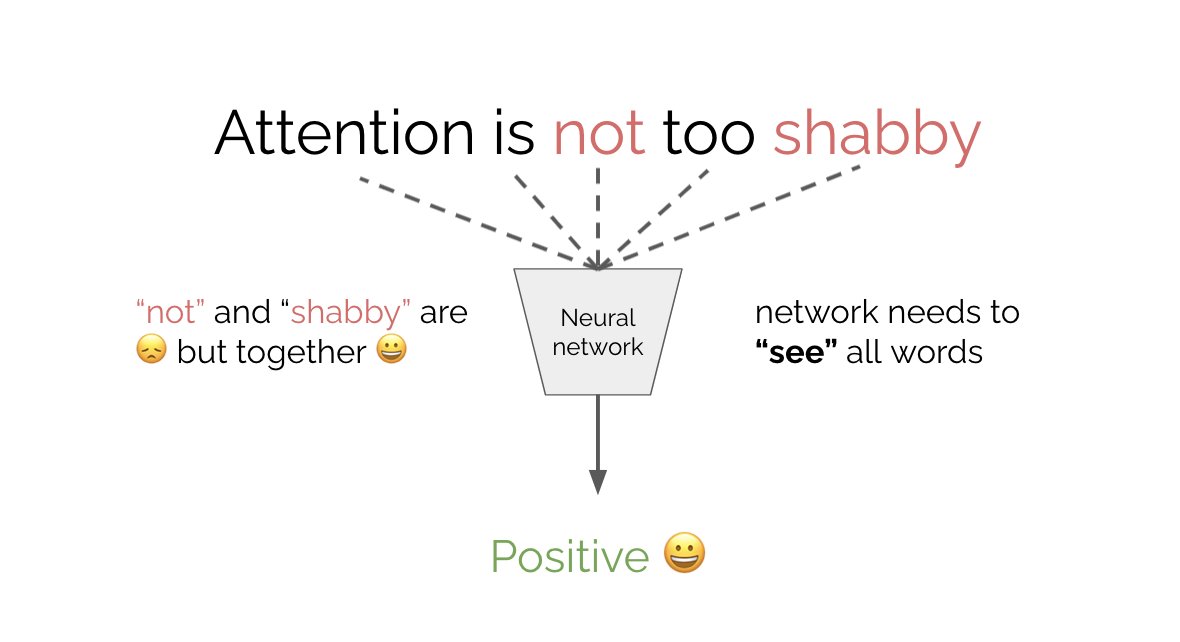
The simplest thing we can do is input all words into the network. Is that enough? No. The net needs to not only see each word but understand its relation to other words. E.g. it’s crucial that “not” refers to “shabby”. This is where queries, keys, values (Q,K,V) come in.
3/n
3/n

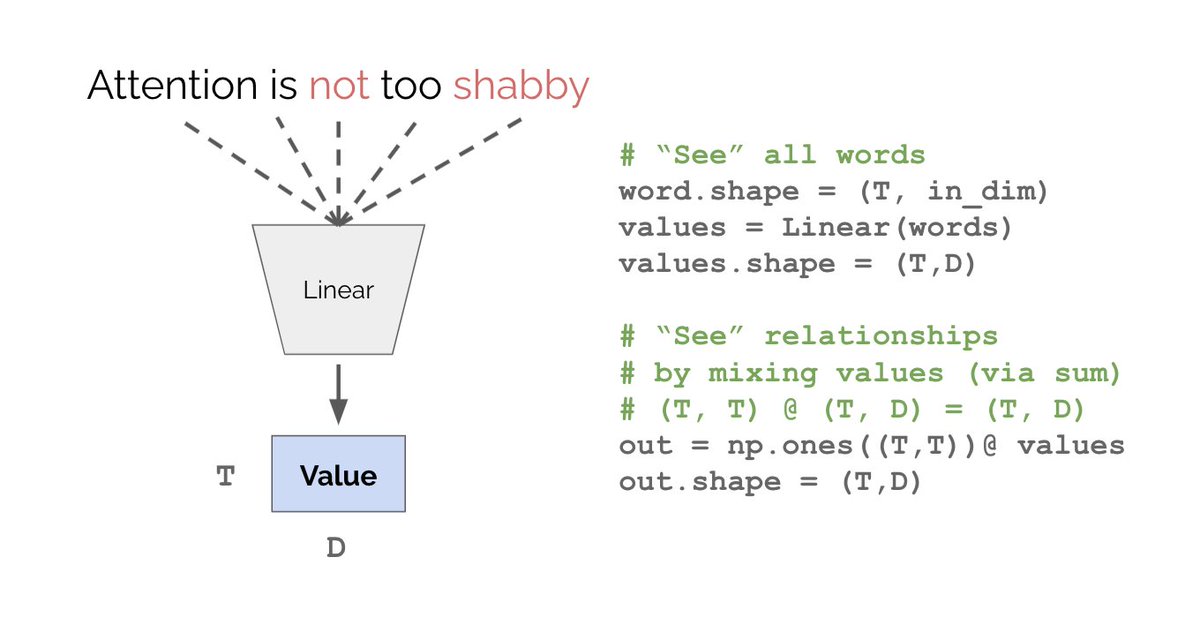
Let’s pass the words through a linear layer and call its outputs “values”. How do we encode relationships between values? We can mix them by summation. Now we “see” both words and relationships, but that’s still not quite right. What’s wrong with this code?
4/n
4/n
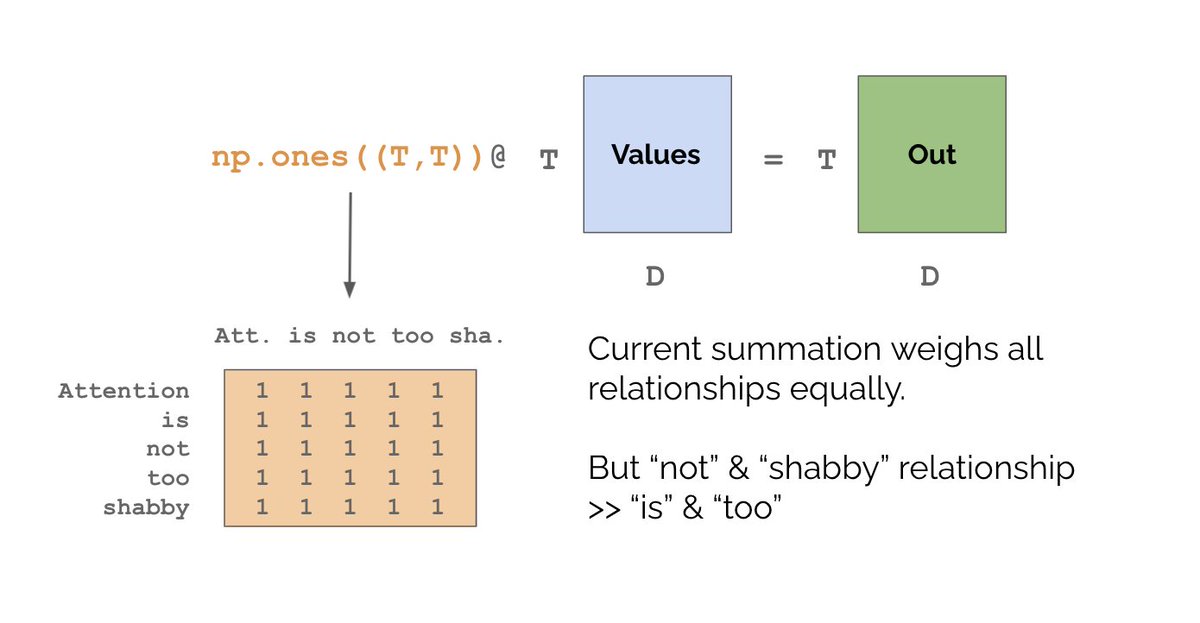
The issue is that naive summing of values assumes the relationships between all words are equal. E.g. relationship between “is” and “too” is equal to that between “not” and “shabby”. But clearly “not” <> “shabby” is more important for sentiment analysis than “is”<>”too”.
5/n
5/n
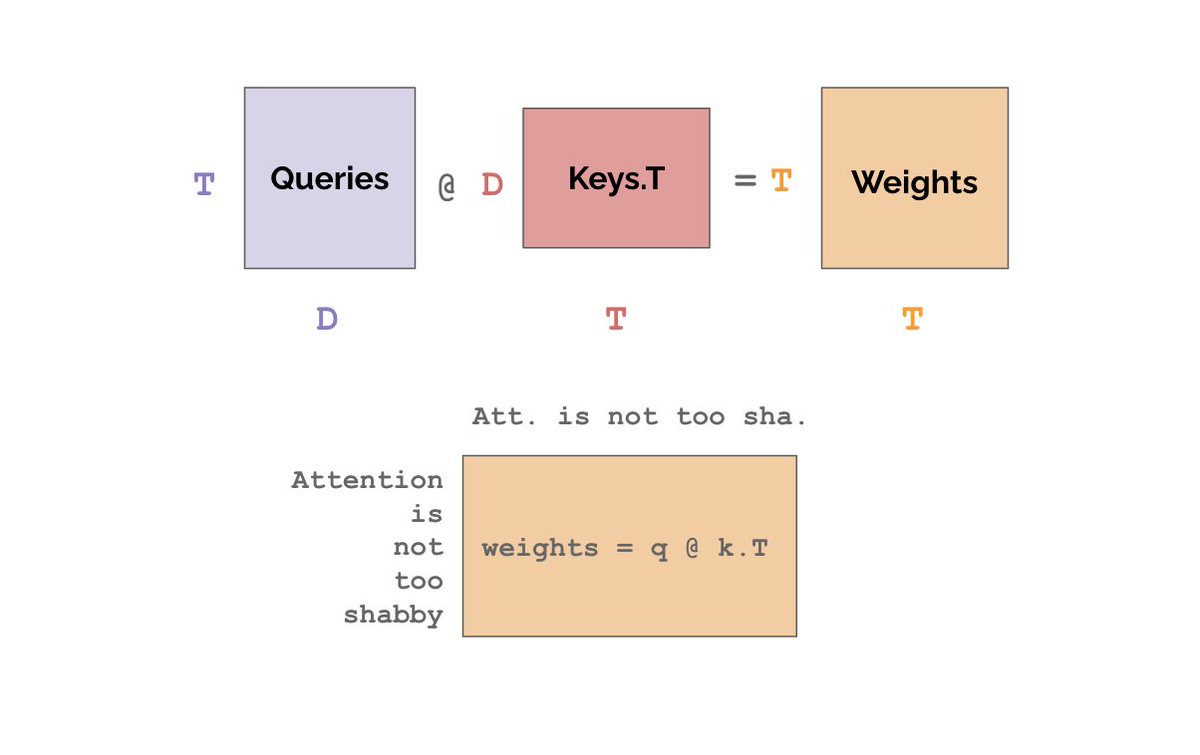
We want the orange matrix to weigh relationships based on how useful word_i is as context for word_j. So let’s create two more linear nets called “queries” and “keys”. The weight w_ij should be proportional to the inner product between the i-th Q and the j-th K.
6/n
6/n
A small but important detail is that we need to re-scale the weights by 1 / sqrt(D). Why this specific scaling? Why not 1 / D or 1 / T or some other constant? The reason is that 1 / sqrt(D) ensures that the standard deviation of the outputs is roughly equal to 1.
7/n
7/n

Finally, we need to normalize the weights along the axis that will be summed, so we use a softmax. Intuitively, Q is a question “how useful am I for word K?” High / low inner product means very / not very useful. With that we are done - this is attention!
8/n
8/n
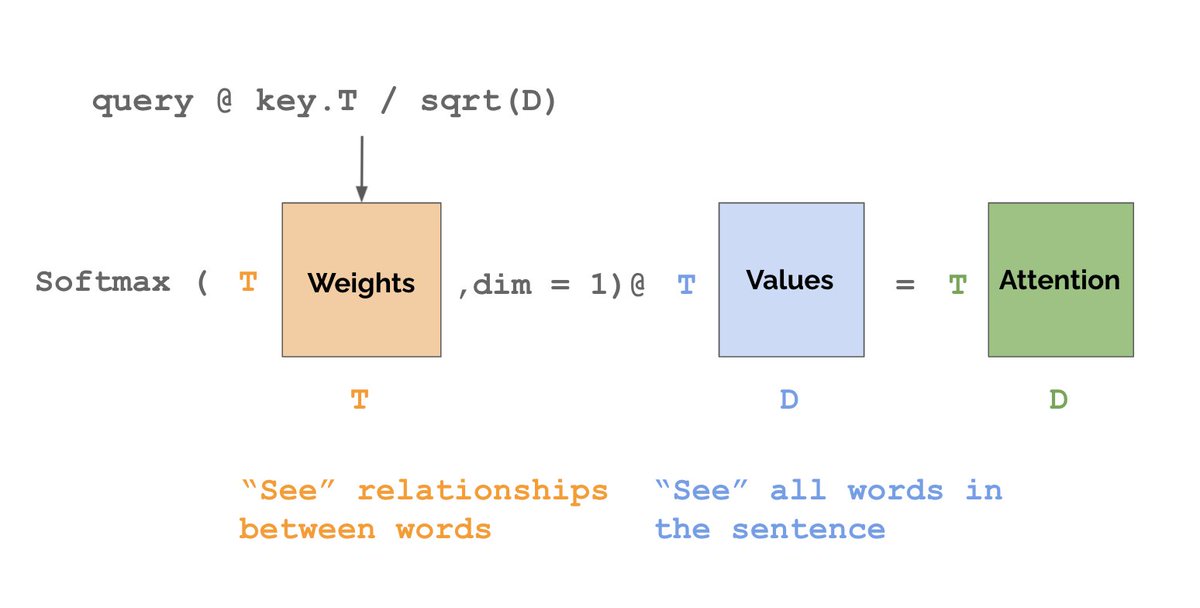
Technically what we’ve shown is called single-head self-attention. Before going to multi-head attention, let’s code up what we’ve done so far.
9/n
9/n

What is multi-head and why do we need it? Our single-head net may overfit to the training data. In ML, ensembles are a common strategy to combat overfitting. By initializing multiple nets we get more robust results. The concat of N single heads is multi-head attention.
10/n
10/n
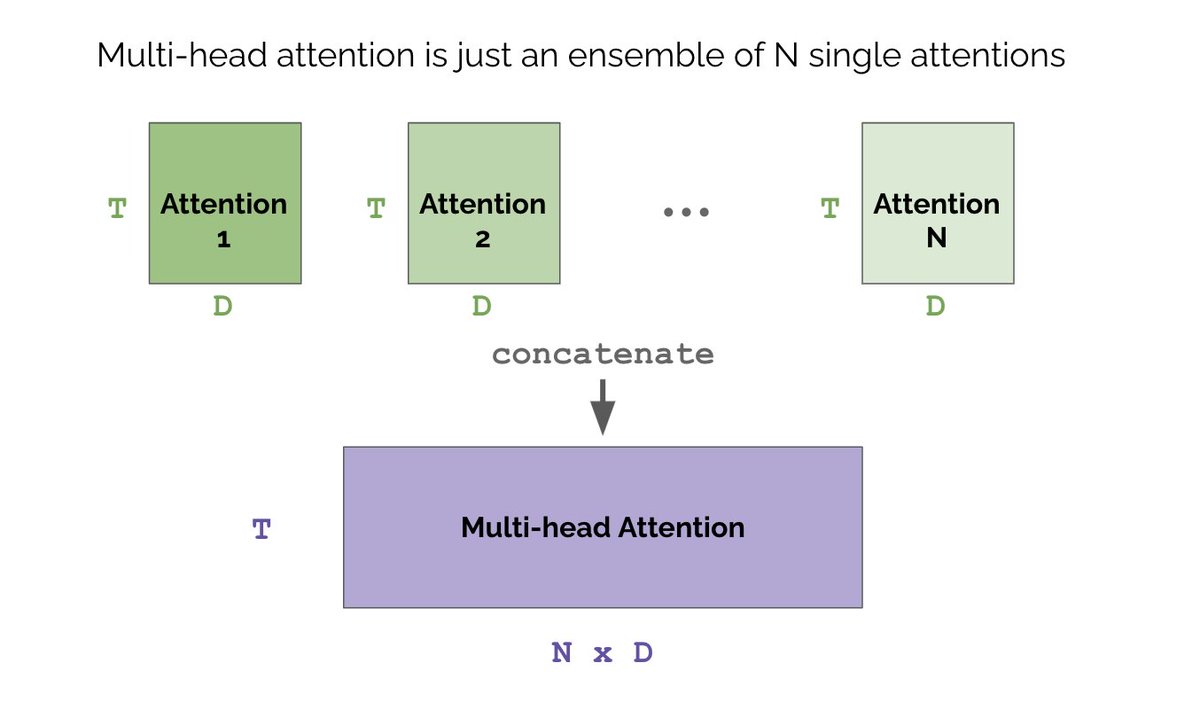
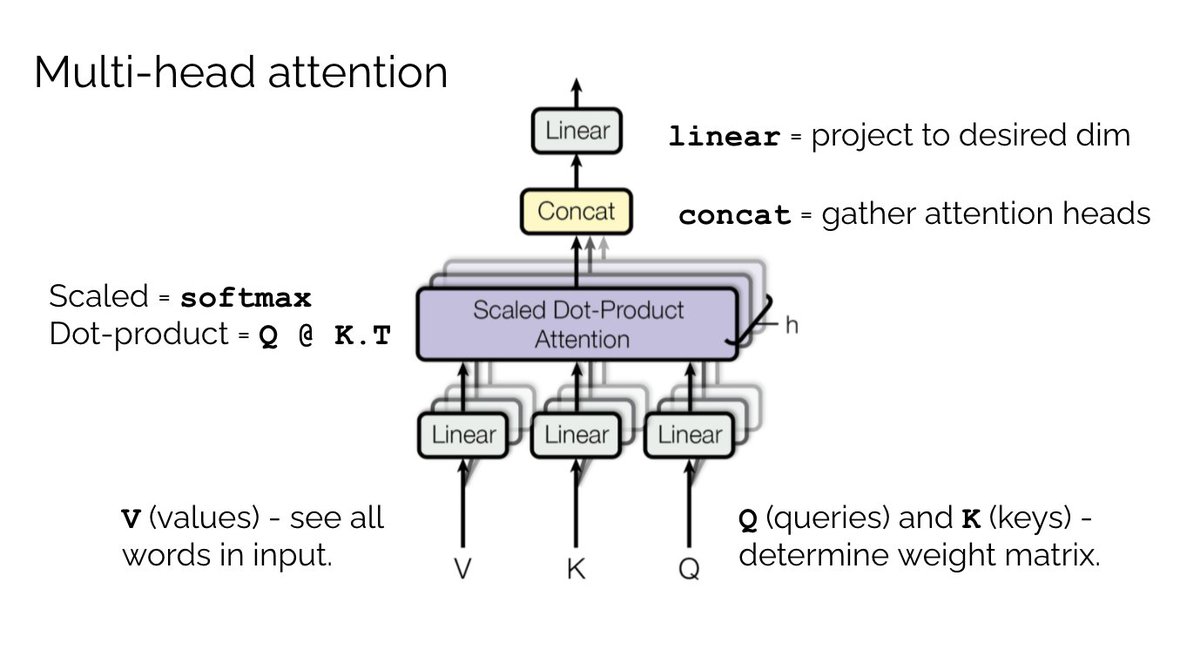
So multi-head is just a small tweak to single-head attention. In practice, we also add dropout layers to further prevent overfitting and a final linear projection layer. This is what a complete vectorized multi-head self-attention block looks like in PyTorch.
11/n
11/n

And there you have it - we derived attention intuitively and wrote it out in code. The main idea is quite simple.
In next posts I will cover Transformers, GPT & BERT, Vision Transformers, and other useful tricks / details. That was fun to write, hope also fun to read!
12/n END
In next posts I will cover Transformers, GPT & BERT, Vision Transformers, and other useful tricks / details. That was fun to write, hope also fun to read!
12/n END
• • •
Missing some Tweet in this thread? You can try to
force a refresh