Since we'll be referencing multi-head attention and GPT, make sure to read parts 1 & 2 if you're unfamiliar with these concepts.
Since we'll be referencing multi-head attention and GPT, make sure to read parts 1 & 2 if you're unfamiliar with these concepts.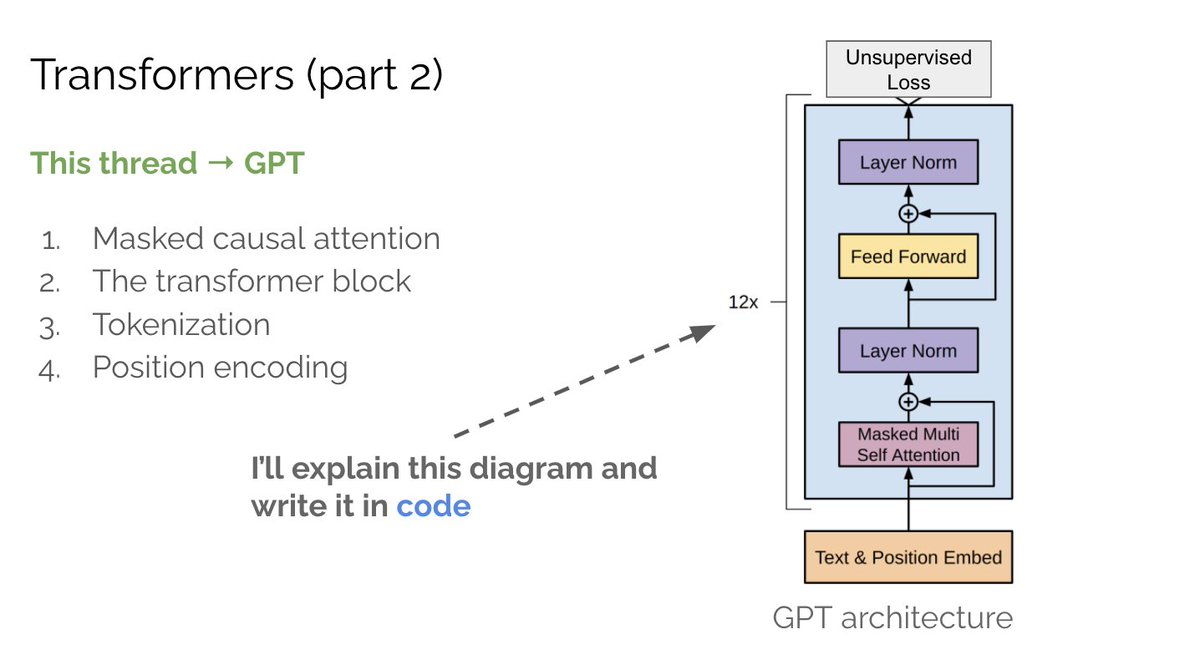 In part 1 we covered multi-head attention (MHA). tl;dr attention allows a neural network to “see” all words in the input as well as their relationships. As a result the net attends to the most important words for optimizing its objective.
In part 1 we covered multi-head attention (MHA). tl;dr attention allows a neural network to “see” all words in the input as well as their relationships. As a result the net attends to the most important words for optimizing its objective.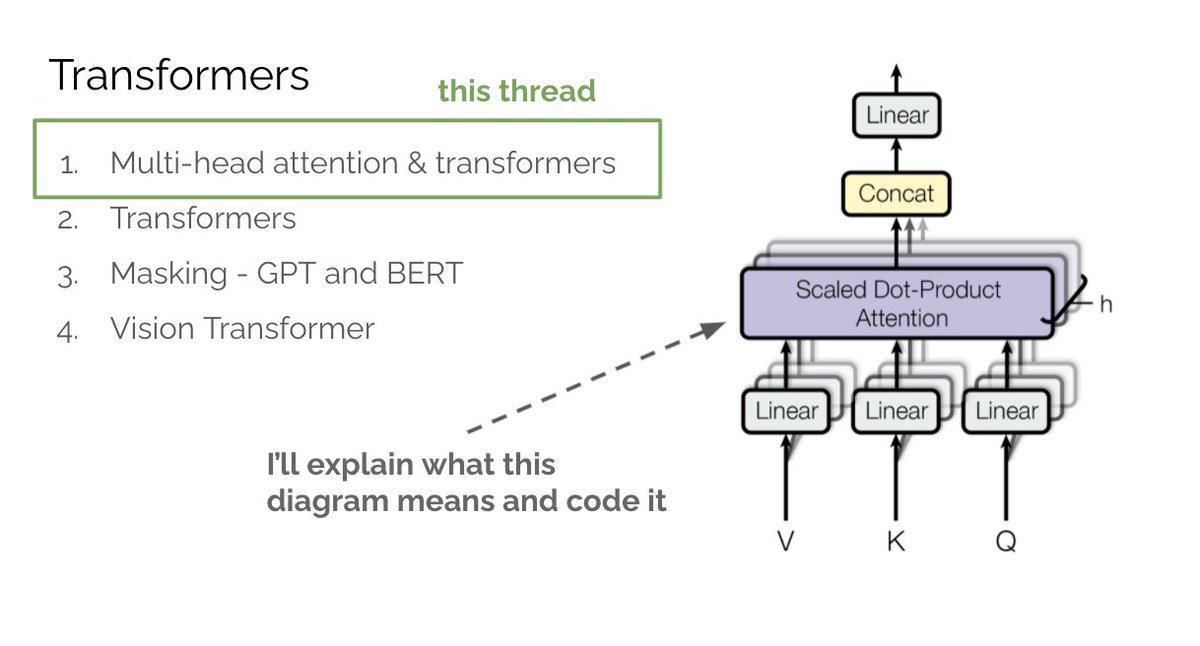 What is attention? Say you want to classify the sentiment of “attention is not too shabby.“ “shabby” suggests 😞 but “not” actually means it's 😀. To correctly classify you need to look at all the words in the sentence. How can we achieve this?
What is attention? Say you want to classify the sentiment of “attention is not too shabby.“ “shabby” suggests 😞 but “not” actually means it's 😀. To correctly classify you need to look at all the words in the sentence. How can we achieve this?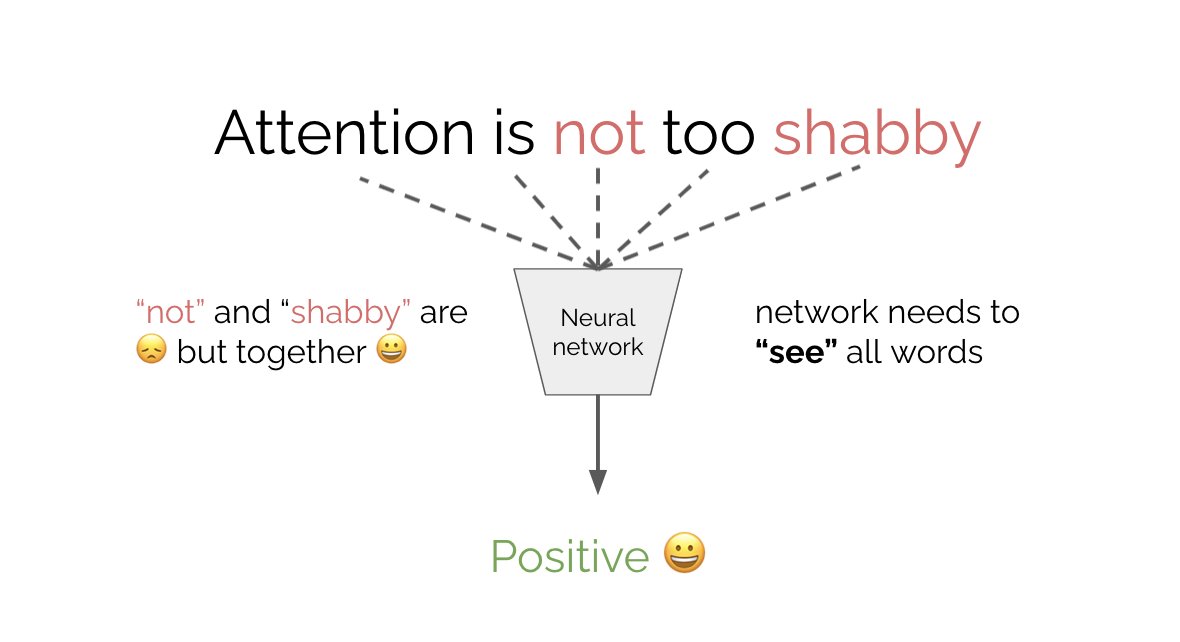
 In deep learning we often need to preprocess inputs into patches. This can mean splitting an image into overlapping or non-overlapping 2D patches or splitting a long audio or text input into smaller equally sized chunks.
In deep learning we often need to preprocess inputs into patches. This can mean splitting an image into overlapping or non-overlapping 2D patches or splitting a long audio or text input into smaller equally sized chunks.