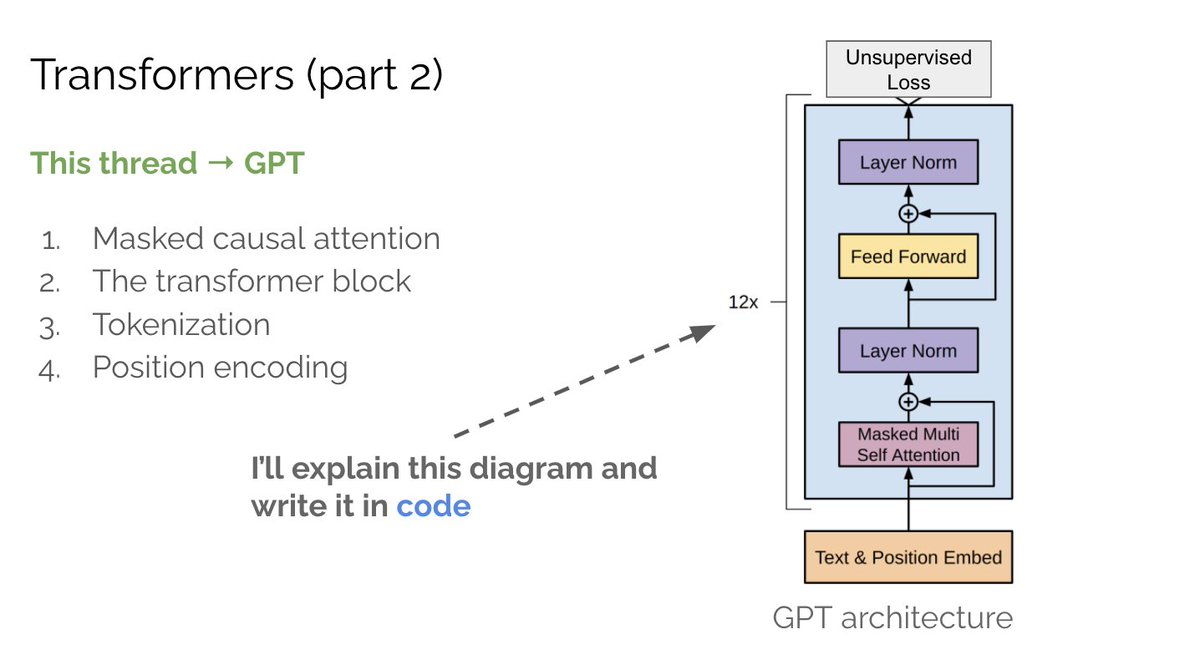
GPT has been a core part of the unsupervised learning revolution that’s been happening in NLP.
In part 2 of the transformer series, we’ll build GPT from the ground up. This thread → masked causal self-attention, the transformer block, tokenization & position encoding.
1/N
In part 2 of the transformer series, we’ll build GPT from the ground up. This thread → masked causal self-attention, the transformer block, tokenization & position encoding.
1/N
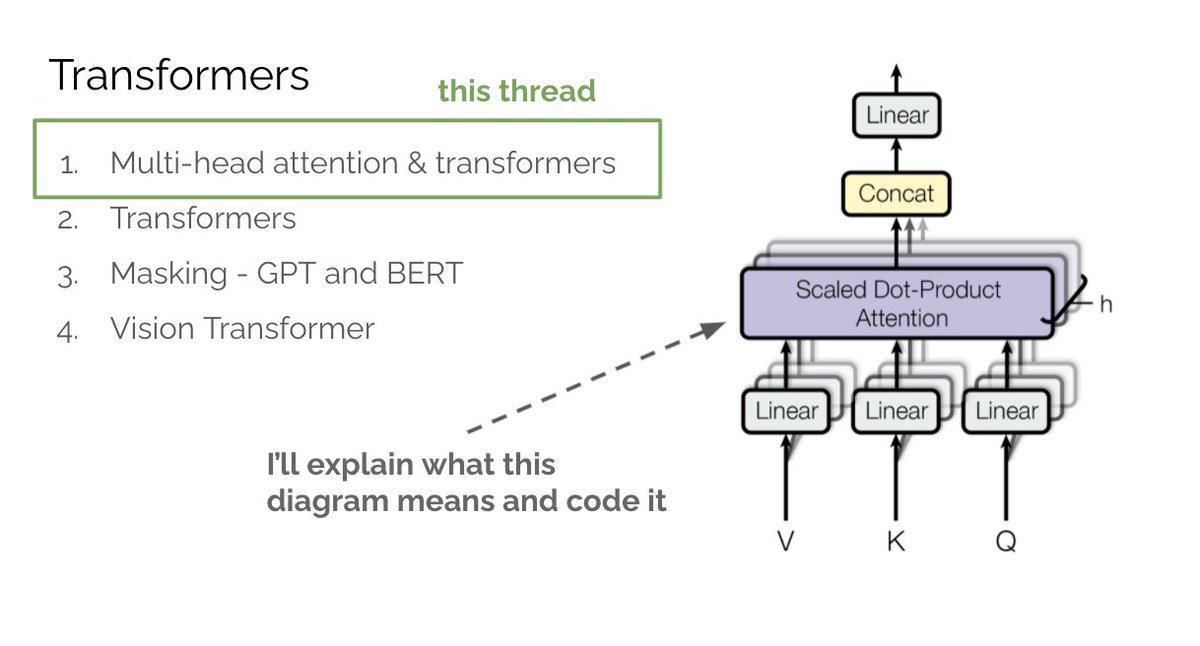
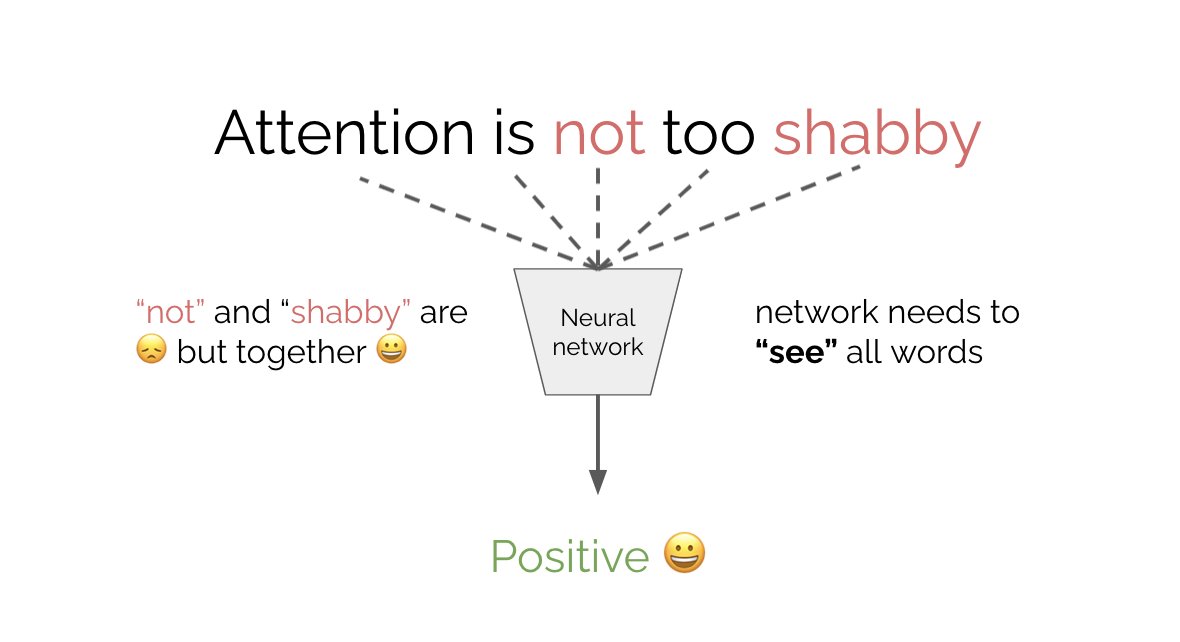
In part 1 we covered multi-head attention (MHA). tl;dr attention allows a neural network to “see” all words in the input as well as their relationships. As a result the net attends to the most important words for optimizing its objective.
2/N
https://twitter.com/MishaLaskin/status/1479246928454037508
2/N
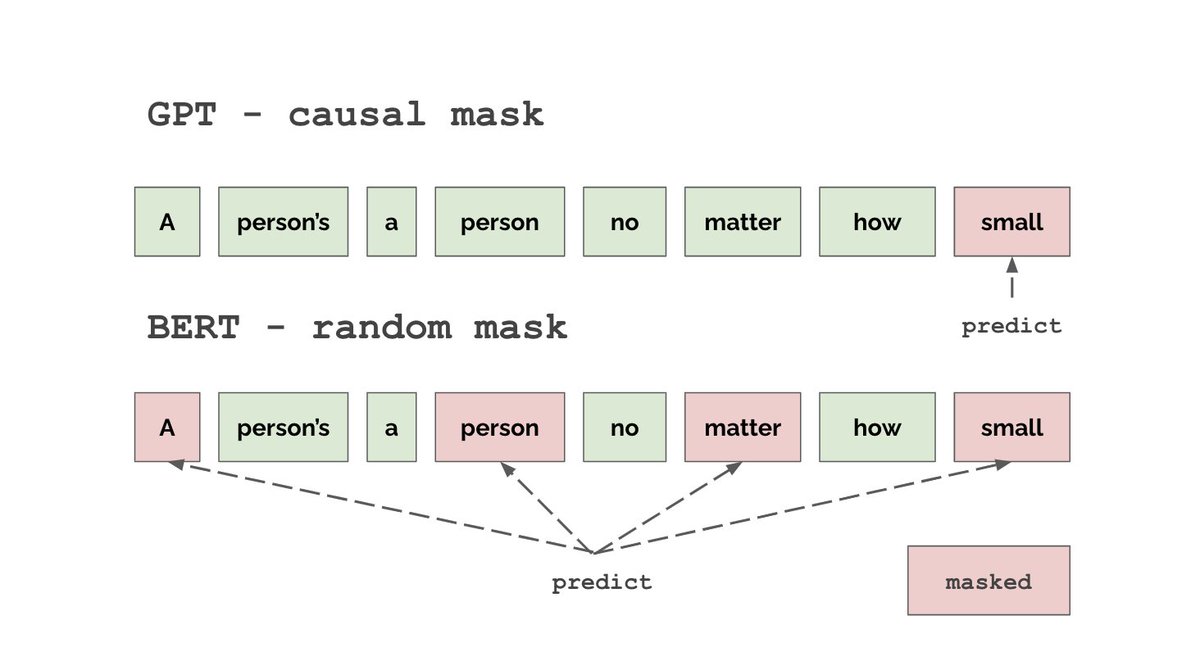
So far, we haven’t defined an objective for MHA to optimize. GPT uses a very simple unsupervised objective - predict the next word in a sentence given previous words. This objective is called unsupervised because it doesn’t require any labels.
3/N
3/N

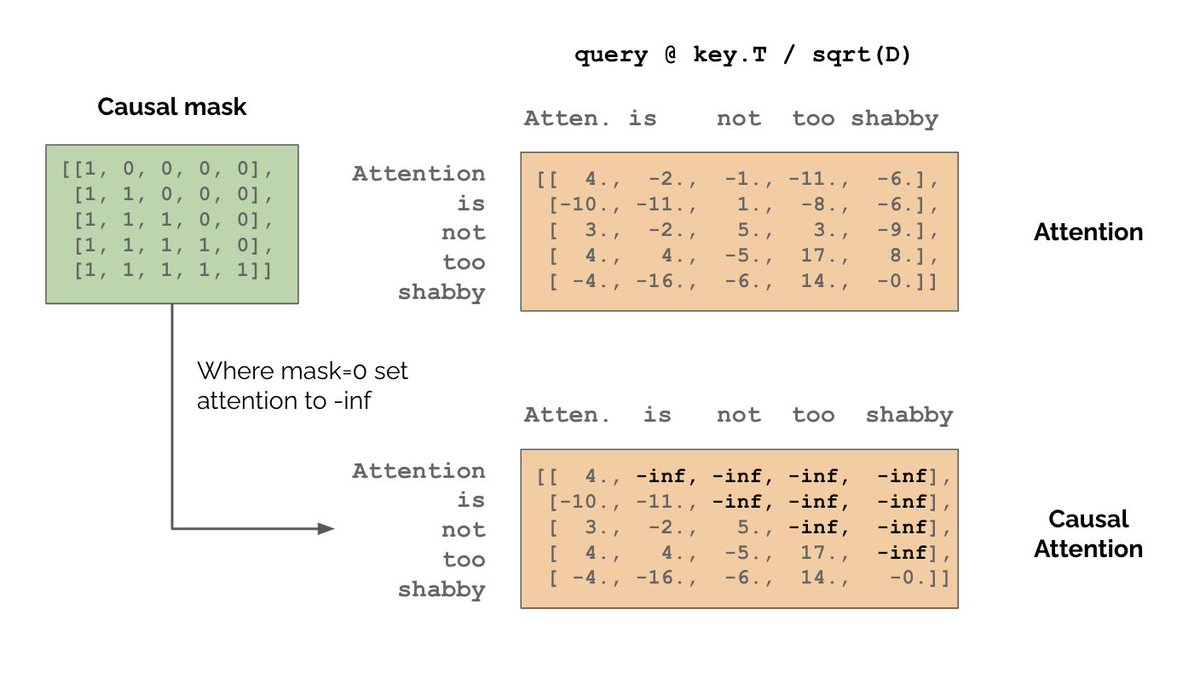
To predict future words we need to enforce causal structure. We can do this with the attention matrix. A value of 0 means “no relationship”. So we need to set attentions between current & future words to 0. We do this by setting Q*K.T = -inf for future words. Why -inf?
4/N
4/N
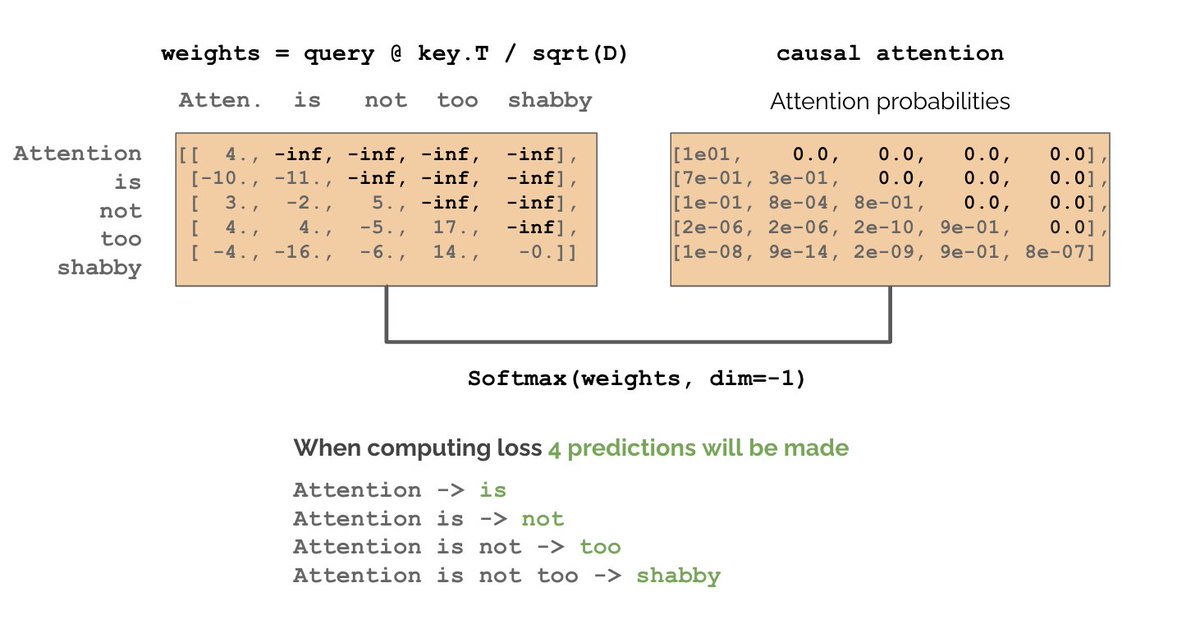
We want attention to be 0 for future words, but if we apply the mask after the softmax, attention will no longer be normalized. So we set QK.T where mask=0 to -inf and then normalize. Notice how although we only have 1 sentence we’re making 4 predictions.
5/N
5/N
Masked causal attention is the main idea of GPT. Now we just need to define the full architecture. The transformer block for GPT is MHA → LayerNorm → MLP → LayerNorm. MHA does the bulk of the work, LayerNorms normalize outputs, MLP projects + adds capacity.
6/N
6/N

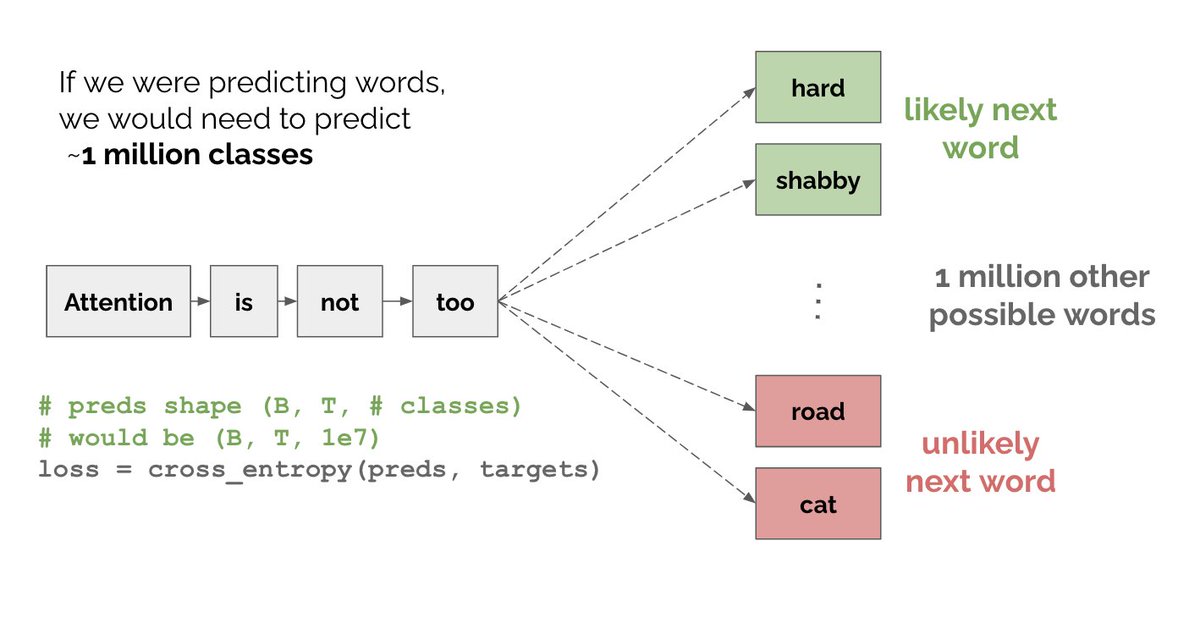
So far, we’ve been saying that GPT predicts words. That’s not entirely true. There are ~1M words in English - if we were literally predicting words each prediction would be a classification across 1M classes. To see this clearly, let’s write down the loss GPT optimizes.
7/N
7/N
To reduce the # of classes in the loss we instead use “tokens”. Tokens are a map between chars and vectors. E.g. chars in the alphabet can be represented by 26 unique vectors - these vectors are called tokens. The map from strings to unique vectors is called tokenization.
8/N
8/N
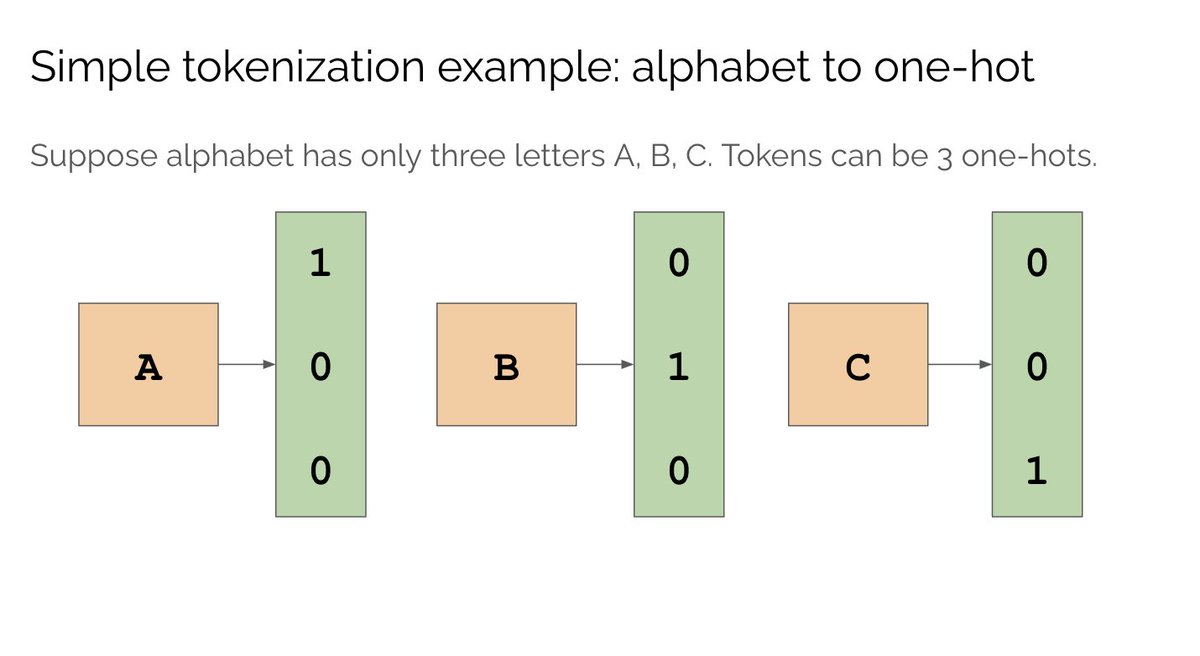
For simple problems tokenizing each char is OK. But it’s not efficient - char groups like “it” “the” occur frequently so we’d prefer to group them into their own tokens. For this reason, GPT uses Byte Pair Encoding which iteratively clusters common char groups into tokens.
9/N
9/N

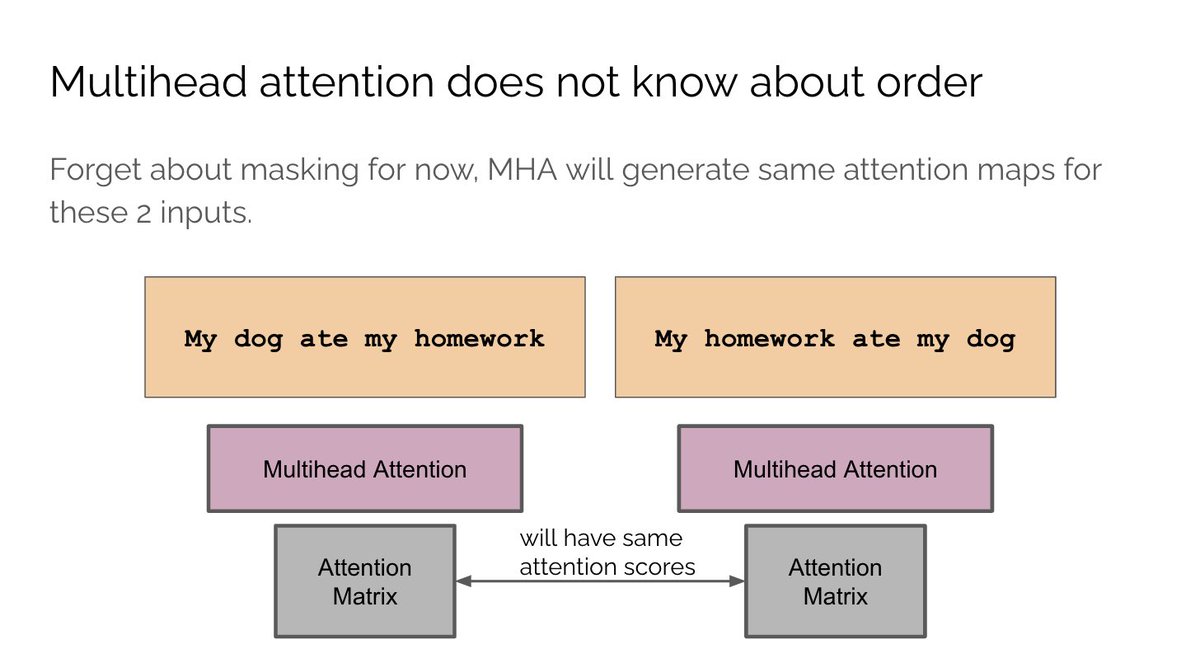
A final but *very* important detail is that our model currently has no way of knowing the order of words. As it stands, our model cannot distinguish between “my dog ate my homework” and “my homework ate my dog” despite them having opposite meanings.
10/N
10/N
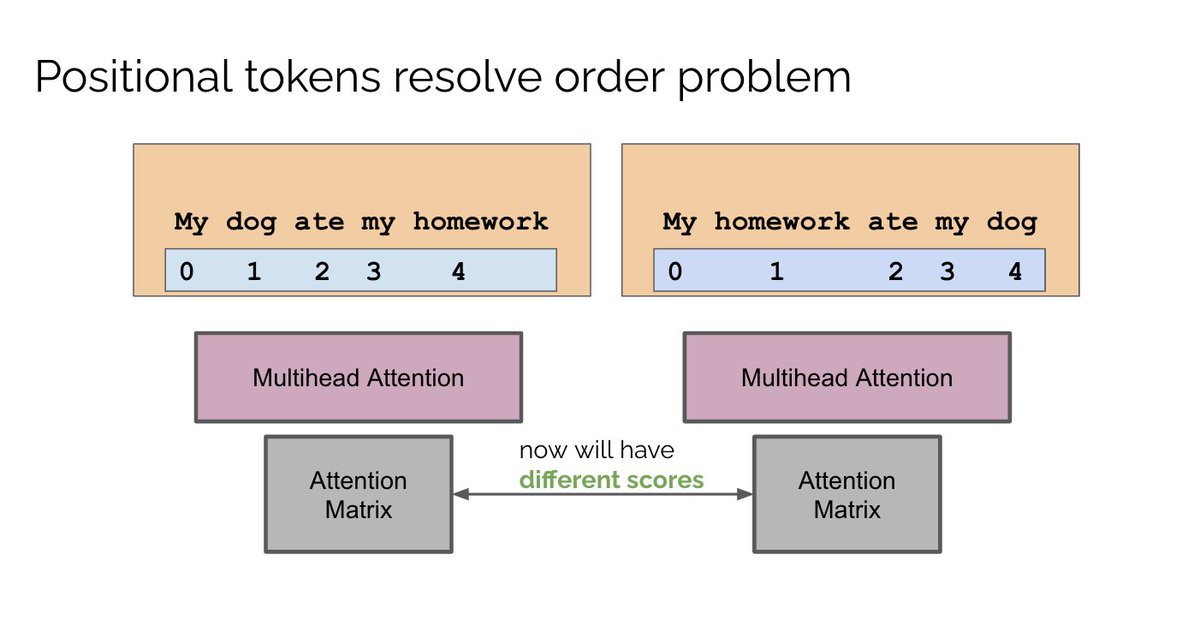
To encode order into the model, we use positional tokens. Similar to char tokens, we label each position with a unique vector. We then project the char and position tokens with linear layers and add them. This embedding is then passed to the transformer block.
11/N
11/N
We covered masked causal attention, the GPT objective, transformer blocks, tokens & positions. Note: there are ofc many other strategies for tokenization / pos encoding.
Putting it all together, here’s the code for the GPT architecture! tinyurl.com/mr2dj2z6
12/N END
Putting it all together, here’s the code for the GPT architecture! tinyurl.com/mr2dj2z6
12/N END



• • •
Missing some Tweet in this thread? You can try to
force a refresh