Сегодня я расскажу простым языком про три сортировки, с которых неизбежно начинается изучение алгоритмов. Первые шаги в создании алгоритмического мышления! 

Речь пойдет о трёх самых базовых алгоритмах сортировки — о Bubble Sort, Insertion Sort и Selection Sort.
Цель всей истории — показать, какие идеи и мысли лежат в основе этой троицы, а также продемонстрировать их сильные и слабые стороны.
Цель всей истории — показать, какие идеи и мысли лежат в основе этой троицы, а также продемонстрировать их сильные и слабые стороны.
Мы выстроим эти алгоритмы по шагам, рассмотрим их простые версии и попробуем их немножко улучшить.
Френдли ремайндер о ретвитах моих тредов. Это простое действие делает сон крепче, здоровье стабильнее, пельмени сочнее и вызывает у ваших врагов рак рака.
Кстати, если вы новичок в теории алгоритмов, и тред с основами основ прошел мимо вас — я настойчиво, очень настойчиво советую вам ознакомиться. В нём всё про О-Нотацию и псевдокод, а так же приведена парочка простых алгоритмов.
https://twitter.com/ValeriiZhyla/status/1470666237286010881
Итак, дальше я действую и пишу исходя из того, что слова "Worst Case алгоритма по времени равен O(n^2)" для вас не пустой звук. Иначе — последний настойчивый совет посетить Алгосы #0 моего авторства.
Вступление окончено. Чем именно мы займемся? Может, попробуем захватить мир?!
Лучше! Мы будем сортировать массивы целых чисел. Положительных. По возрастанию, от меньшего к большему. А ещё рисовать писать псевдокод и разглядывать примеры.
Time Complexity я буду называть "сложностью по времени", а Space Complexity — "сложностью по памяти".
Time Complexity я буду называть "сложностью по времени", а Space Complexity — "сложностью по памяти".
Давайте разберем вопросы и загадки, который бы встретил гипотетический программист, впервые встретившийся с проблемой сортировки. Оставим его безымянным, чтоб было легче себя с ним ассоциировать.
Итак, вопрос номер раз: нужно ли отсортировать переданный массив (именно ЭТОТ массив), или лучше создать его копию, и сортировать уже её, не трогая и никак не модифицируя оригинал?
Давайте прикинем, на пальцах. В чём плюсы и минусы решения без создания копии?
Первое, и очевидное последствие: мы потеряем изначальный массив. Имел ли этот массив особую ценность? Зависит от конкретные ситуации. В основном, отсортированные данные хуже хаотичных не бывают.
Первое, и очевидное последствие: мы потеряем изначальный массив. Имел ли этот массив особую ценность? Зависит от конкретные ситуации. В основном, отсортированные данные хуже хаотичных не бывают.
Но всё же это побочный, или сторонний, эффект работы алгоритма. Их называют side effects.
Это очень важная штука, которую всегда нужно держать в голове. Лишний сторонний эффект отнесем к минусам.
Это очень важная штука, которую всегда нужно держать в голове. Лишний сторонний эффект отнесем к минусам.
Плюсы этой стратегии? Нам не придется выделять память под копию массива, что стоило бы O(n) в копилку Space Complexity. Итого O(1) памяти, in-place, красота.
К тому же массив не придется копировать в новое место, а значит экономится ещё O(n) Time Compexity.
К тому же массив не придется копировать в новое место, а значит экономится ещё O(n) Time Compexity.
С in-place решением разобрались. Теперь посмотрим на решение с созданием копии и работе с ней, out-of-place.
В чём плюсы и минусы этого решения? Диаметрально противоположные! Никаких сторонних эффектов, зато ожидаемые дополнительные O(n) памяти и времени.
Забегая наперёд, скажу, что лишние O(n) времени в вопросах сортировок никакой глобальной роли не играют, так как сама сортировка сожрёт намного больше. А вот O(n) памяти это серьезный аргумент избегать out-of-place алгоритмы, если возможно.
Никто же не любит приложения, которые жрут память гигабайтами, или выжирают всё, что доступно, и падают с ошибками? Правда ведь?

Вопрос номер два: как менять элементы массива местами?
Я бы опустил этот момент, но давайте для полноты картины напишем функцию, которая призвана эффективно переставлять два элемента по их индексам на место друг друга. Чтоб исключить появление белых пятен и недомолвок. Вот она:
Я бы опустил этот момент, но давайте для полноты картины напишем функцию, которая призвана эффективно переставлять два элемента по их индексам на место друг друга. Чтоб исключить появление белых пятен и недомолвок. Вот она:

Чуть больше контекста? Хорошо. Функция swap получает массив, и два индекса. Первым делам она сохраняет копию элемента по первому индексу (какое-то число) в отдельную переменную temp (от слова temporary, временный, очень частое сокращение, озадачивающее молодые умы).
fst это типичное сокращение для first, а snd — для second. Сокращением idx часто обозначают слово индекс, потому что мы очень не любим трать буквы впустую (особенно я, да) и писать слово index целиком.
Дальше она перезаписывает содержимое по первому индексу копией содержимого по второму индексу. В этот момент у нас появляется два одинаковых элемента, а оригинальное значение из ячейки с первым индексом утрачивается.
Благо мы сохранили его в переменную temp, и в конце записали в ячейку со вторым индексом.
Со свопом разобрались!
Со свопом разобрались!
Вопрос номер три, ключевой: как упорядочить массив нужным нам образом?
Хорошей идеей было бы начать со сравнения элементов между собой. Сравнивать-то можно, но что делать дальше? Менять их местами! Хорошо, что в этом нам теперь сам чёрт не товарищ...
Хорошей идеей было бы начать со сравнения элементов между собой. Сравнивать-то можно, но что делать дальше? Менять их местами! Хорошо, что в этом нам теперь сам чёрт не товарищ...
Упорядочивание с помощью сравнения и обмена местами звучит как что-то, что действительно может понизить уровень хаоса. Сразу возникает вопрос: “А какие именно элементы мы будем сравнивать?”.
Самый очевидный вариант — сравнивать элементы с соседними индексами. Логика элементарная: сравниваем таких соседей, если значение левого больше правого — меняем их местами.
Произвольный индекс массива назовём i. Следовательно, правый сосед будет иметь индекс i + 1. Теперь переварим последнюю мысль в маленький блок кода:
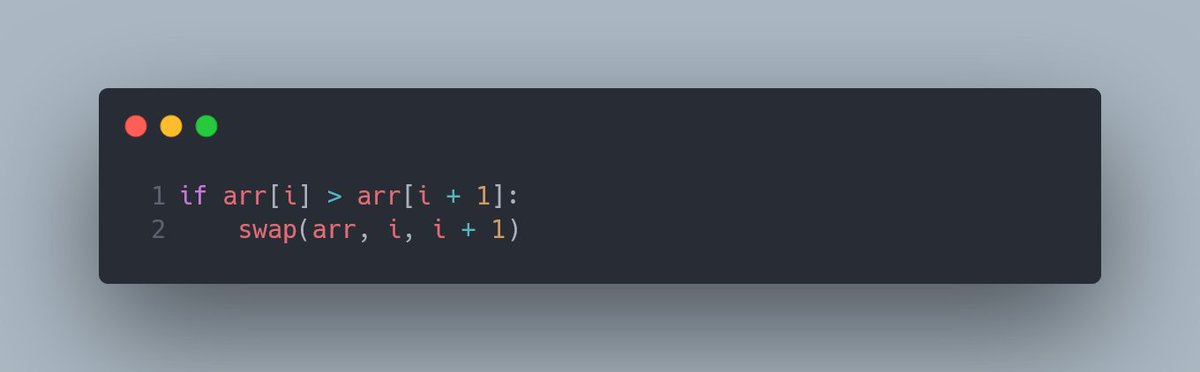
Этот код — замечательная отправная точка для сортировки массива от меньшего к большему.
Как бы его довести до ума? Для начала попробуем применить это действие на каждый индекс массива. Разумеется, кроме последнего, отсюда и n-1 — в противном случае наша программа натворила бы делов.

Будет ли наш массив после этого отсортирован? Нет, но станет чуть менее хаотичным! Попробуем посмотреть на каком-то простом примере:
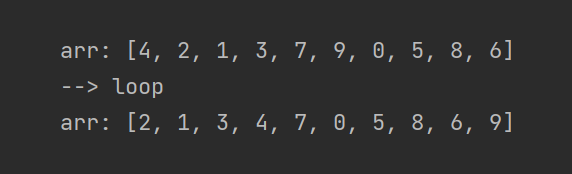
Что можно из него вынести? Во-первых, все элементы массива сместились. Почти все — в нужную сторону. Во-вторых, самый большой элемент массива занял своё законное место — девятка оказалась в самой правой ячейке!
Она поменялась местами с 0, потом с 5, потом с 8 и с 6, каждую итерацию “передвигаясь” или “всплывая” на своё законное место.
Прогоним наш код ещё несколько раз!
Прогоним наш код ещё несколько раз!
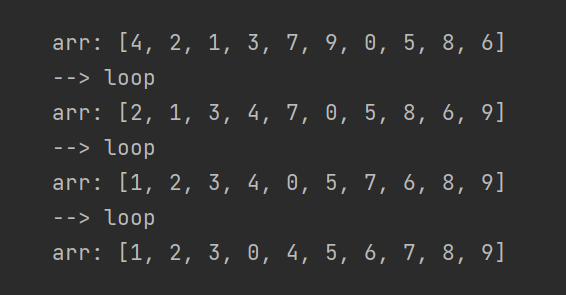
Ситуация явно улучшилась, за всего три прохода. Каждый виток гарантирует нам “всплывание” одного из элементов на его позицию — после первого витка на место встало число 9, после второго — число 8, а дальше по счастливой случайности — сразу четыре элемента.
Сколько витков этих свопов нам нужно, чтоб гарантированно отсортировать массив? Если каждый виток ставит на место минимум один элемент, то через n витков мы гарантированно получим отсортированный массив!
Даже через n-1, потому что для самого правого элемента и так останется только одна возможность размещения.
Взглянем на этот код:
Взглянем на этот код:

Великолепно! Мы только что собрали из ничего первый алгоритм сортировки!
Итерацию за итерацией большие числа “всплывают” наверх, а маленькие “тонут” вниз. Кто-то давно, до нашего рождения, увидел в этом аналогию с пузырьками. Поэтому такая сортировка называется пузырьковой, или же Bubble Sort.
Наша версия “пузырька” вышла максимально наивной — O(n^2) по времени и в худшем, и в лучшем случае. Звучит как план, надёжный, как швейцарские часы, но его можно улучшить!
Во-первых, мы знаем, что каждое выполнение внутреннего цикла гарантированно ставит на место один правый элемент. Значит, с каждым новым j можно сдвигать эту “границу передвигания” на единичку, что и происходит на строке 3. Зачем лезть туда, где точно ничего не произойдет?

Уже лучше, но всё ещё много дурной работы. Как бы нам добиться того, чтоб программа могла остановиться, как только массив будет отсортирован? Раньше срока, так сказать, если работа выполнена.
Как это распознать? Например, если массив отсортирован, то следующий внутренний цикл не сделает ни единого свопа! За это определённо стоит зацепиться.
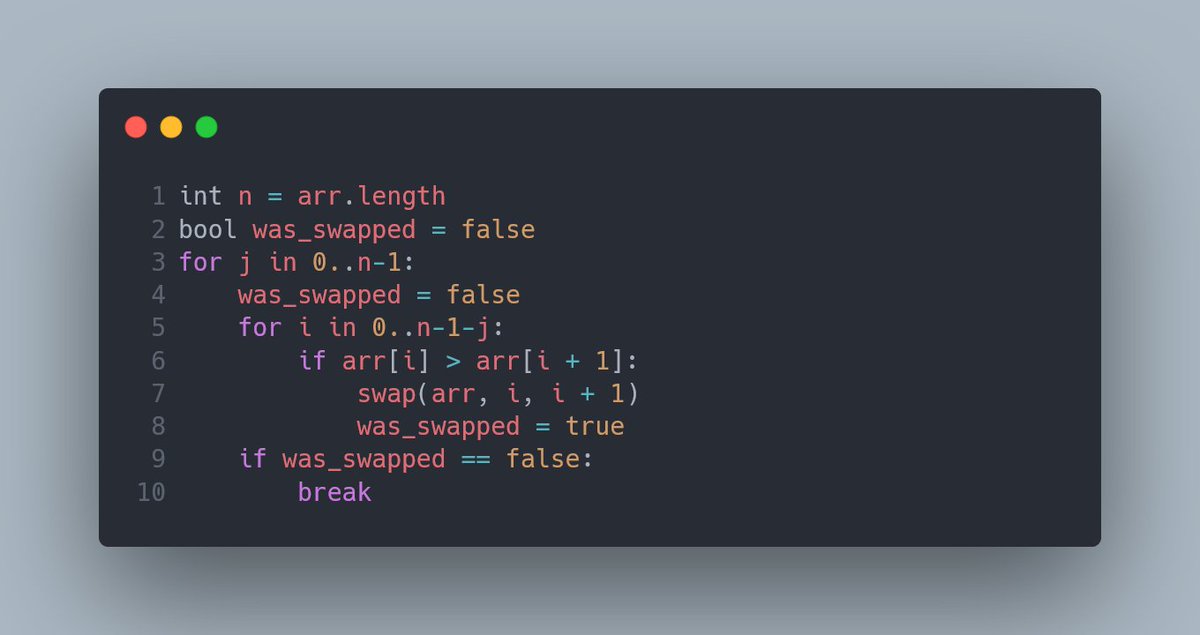
Что мы сделали? Ввели новую переменную, которая в начале каждого внешнего цикла устанавливается на false, и после каждого свопа меняется на true.
Если внутренний цикл не сделает ни одного свопа, переменная останется со значением false и прервет внешний цикл.
Чувствуете это? Это наш Best Case стал O(n)!
Чувствуете это? Это наш Best Case стал O(n)!
Программе с изначально отсортированным массивом потребуется лишь провести один проход внутреннего цикла, распознать отсутствие изменений и прервать внешний цикл.
Вот это уже смахивает на Bubble Sort, который и на собесе не стыдно нарисовать!
Облачим этот код в функцию и продолжим наш полёт фантазии:
Облачим этот код в функцию и продолжим наш полёт фантазии:
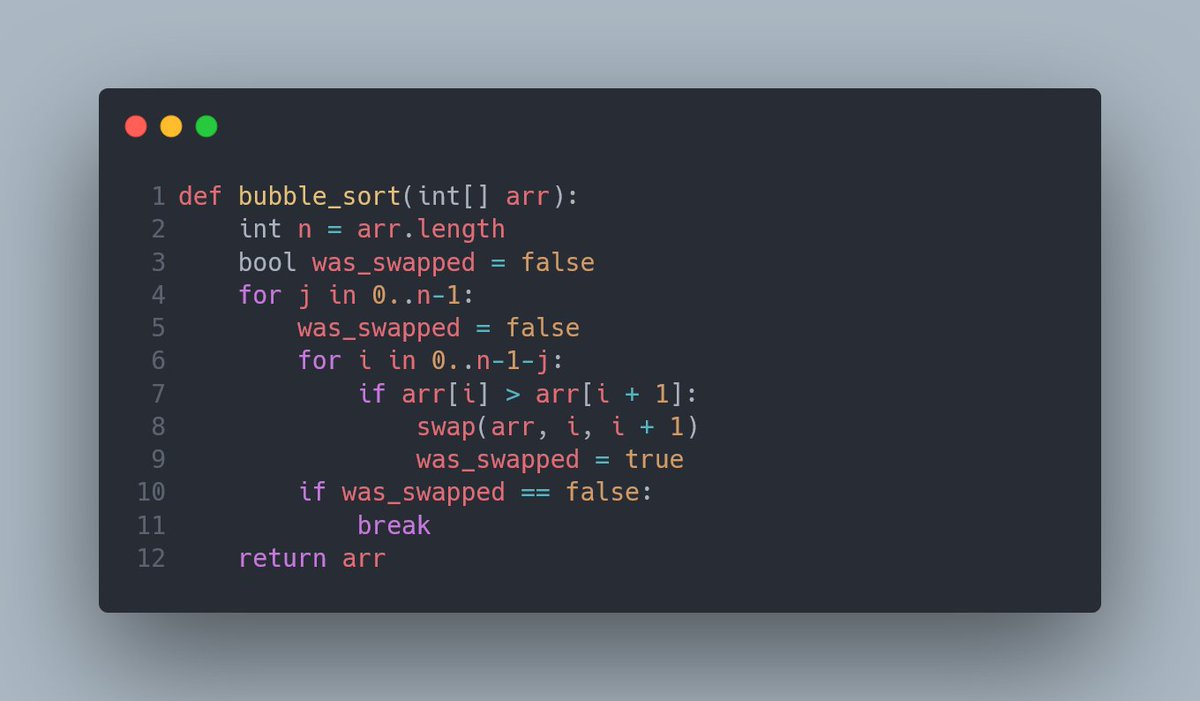
Для протокола:

Двигаемся дальше! Наш новый подопытный — сортировка выбором, она же Selection Sort!

Раннее мы увидели алгоритм, основанный на сравнении соседних элементов. Какой ещё способ можно выбрать для сортировки? Способ этот называется Selection Sort, он же “Сортировка Выбором”. И сейчас станет ясно, почему именно выбором, и что мы собираемся “выбирать”.
Начнём с небольшой воображаемой сцены.
Стоит мальчик (можете заменить на дедушку, бабушку, котика или герань, на свой вкус), а перед ним на столике хаотично лежат бумажки с разными числами. Ему нужно (по зловещей задумке автора) эти числа сложить в рядок, по возрастанию.
Стоит мальчик (можете заменить на дедушку, бабушку, котика или герань, на свой вкус), а перед ним на столике хаотично лежат бумажки с разными числами. Ему нужно (по зловещей задумке автора) эти числа сложить в рядок, по возрастанию.
Он находит из этого набора бумажек одну с самым маленьким числом, и откладывает его на соседний столик. Возвращается к хаосу из бумажек с числами, находит очередное наименьшее число, забирает его и кладет на второй столик, справа от предыдущего.
Так, шаг за шагом, мальчик выстроит стройную шеренгу из чисел. Несложно догадаться, что получившийся аналог массива будет отсортирован по возрастанию — слева лежит самое маленькое число, справа — самое большое.
Примерно так же работает "наивный" Selection Sort. Давайте попробуем изобразить его!
Во-первых, нам нужна функция для поиска минимума в массиве. Точнее, для поиска индекса наименьшего элемента. Например, такая:
Во-первых, нам нужна функция для поиска минимума в массиве. Точнее, для поиска индекса наименьшего элемента. Например, такая:
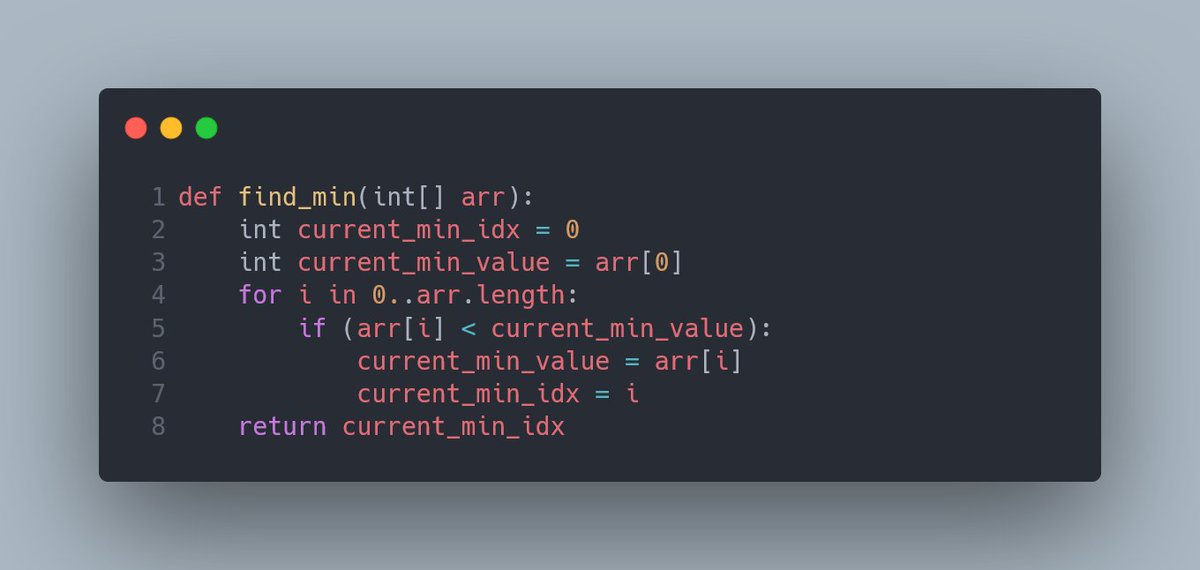
Можно было бы обойтись без current_min_value, но я всё-таки оставлю эту переменную, исключительно для наглядности.
Суть find_min() максимально проста: за отправную точку берём первый элемент массива, называем это текущим минимумом. Далее поочерёдно сравниваем элементы массива с текущим минимумом, обновляя его значение, если обнаруживается элемент с меньшим значением.
При этом мы принимаем за данность, что все ячейки массива arr заполнены числами, без пустых ячеек, и в массиве есть минимум один элемент. В противном случае find_min() станет ещё более уродливым.
Ещё нам нужна функция удаления элемента из массива. Исключительно красоты ради, максимально простая функция:

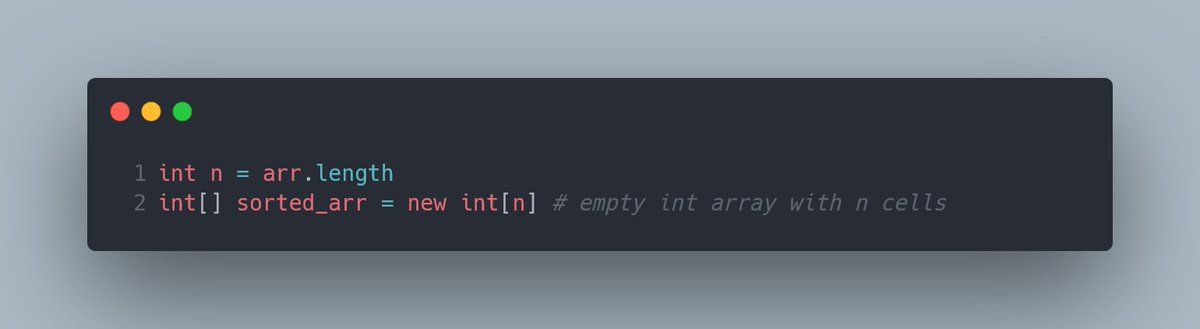
Итак, приготовления завершены, можно думать о самой сортировке. Оригинальный массив мы будем урезать шаг за шагом, а сам ответ будет выстраиваться во втором массиве. Значит, начать следует с создания пустого массива, с тем же размером, что и у оригинала.
А дальше мы засунем шаги из недавнего мысленного эксперимента в наш алгоритм!
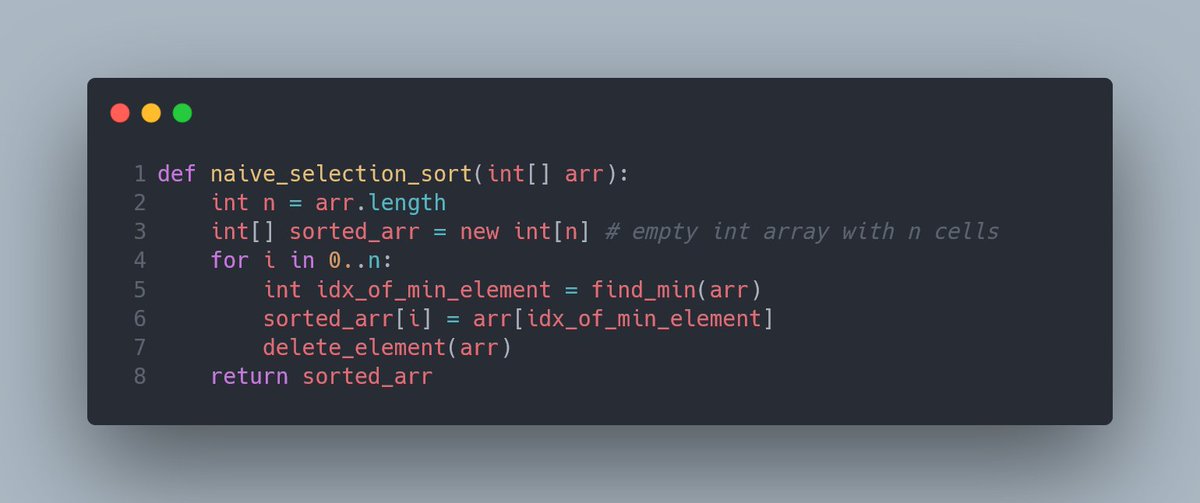
Какие к этому товарищу могут возникнуть замечания? Во-первых, он жрёт память аки чорт — из-за необходимости создать отдельный массив под результаты, получаем с порога O(n) по памяти прямо в кадык.
Во-вторых, код необходимо немного переделать, так как delete_element() создает пустоты в arr, о которые споткнется find_min().
В-третьих, по времени исполнения алгоритм не блещет — O(n^2) как в худшем, так и в лучшем случае.
Возникает резонный вопрос — что делать?
Великолепным лайфхаком в этой ситуации является “переиспользование” места в массиве под остальные нужды. Что значит “переиспользование”? Дед, ты экологом заделался?
Сейчас будет чуть-чуть замешательства, а дальше всё станет на свои места, обещаю!
Итак, вот код оптимального Selection Sort, который переиспользует массив arr, наращивая в нём же отсортированный массив:
Итак, вот код оптимального Selection Sort, который переиспользует массив arr, наращивая в нём же отсортированный массив:

Компактно, правда? Я добавил новую функцию, find_min_between(array, start_idx, end_idx). Работает точно так же, как наш старый знакомый find_min(array), только проходит не по всему массиву, а только по кусочку между start_idx и end_idx.
Думаю, что наш второй старый знакомый, swap(array, i, j), в представлении не нуждается.
Итак, теперь нужно объяснить, как, и главное, почему это работает. Для начала, возьмём массив arr с десятью числами:
Итак, теперь нужно объяснить, как, и главное, почему это работает. Для начала, возьмём массив arr с десятью числами:

Для затравки посмотрим на состояние arr после нескольких проходов цикла в selection_sort(), то есть первых, например, пяти итераций. Просто чтобы попытаться заметить, что же такого делает наш алгоритм. Итак, состояния:
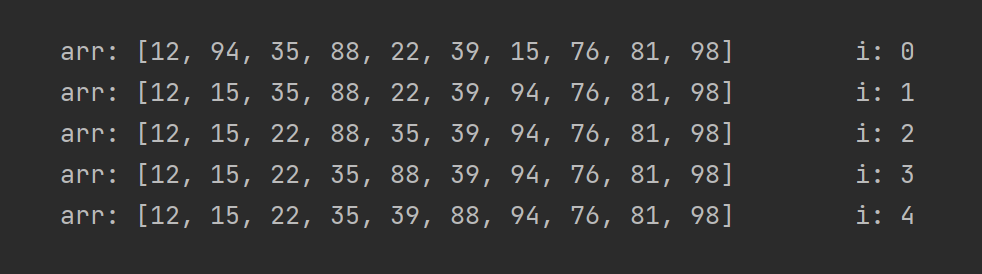
А теперь давайте разбираться. Для переиспользования левой части массива arr под сохранение отсортированного массива наш алгоритм использует “барьер” между отсортированной и неотсортированной частью.
“Барьер” этот находится ровнёхонько между соседними элементами по индексам i и (i + 1).
При i=1 в отсортированной части массива будет только один элемент. При i=2 их будет уже два. В каждой итерации наш алгоритм будет искать наименьшее значение в правой части (от i + 1 и до конца массива), и менять его местами с элементом по индексу i.
Сделаем весь процесс чуть более наглядным, добавив разделитель между элементами, по которым проходит граница между отсортированной и неотсортированной частями массива:
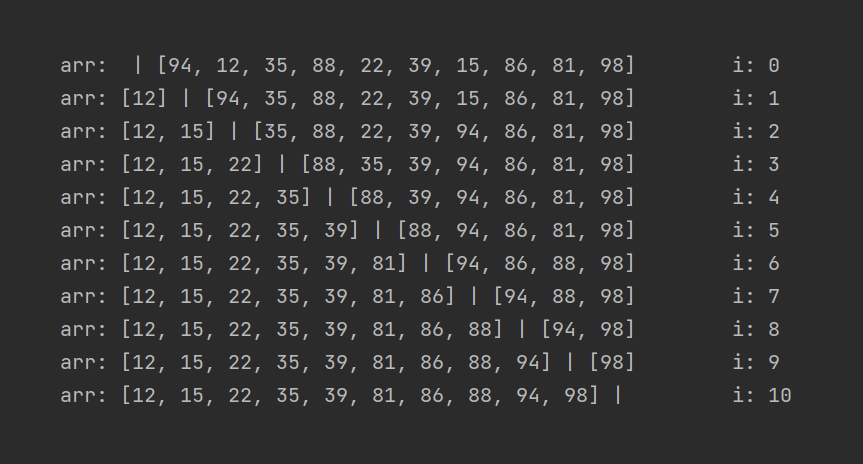
Уточню, что состояние arr показывается каждый раз в конце соответствующей итерации. Первая строчка после первой итерации (при i равным нулю), и дальше по списку.
Возможно, поставить самый большой элемент массива вна последнее место было не самой полезной идеей...
Надеюсь, что идея Selection Sort теперь кажется простой и естественной. Давайте взглянем на его характеристики. Во-первых, у этой реализации O(1) по памяти, за счёт использования левой части массива. Это хорошо.
Во-вторых, за счёт поиска минимально элемента (ест O(n) времени) в каждом цикле (n раз), мы получаем как Worst Case, так и Best Case O(n^2). Это не хорошо.
Выходит, что Bubble Sort всегда лучше Selection Sort по скорости, из-за Best Case O(n)? Тут, как в одном известном анекдоте, есть один нюанс. В конце треда мы поговорим про представленные алгоритмы и сравним те их аспекты, которые не учитываются в О-Нотации.
Для протокола:
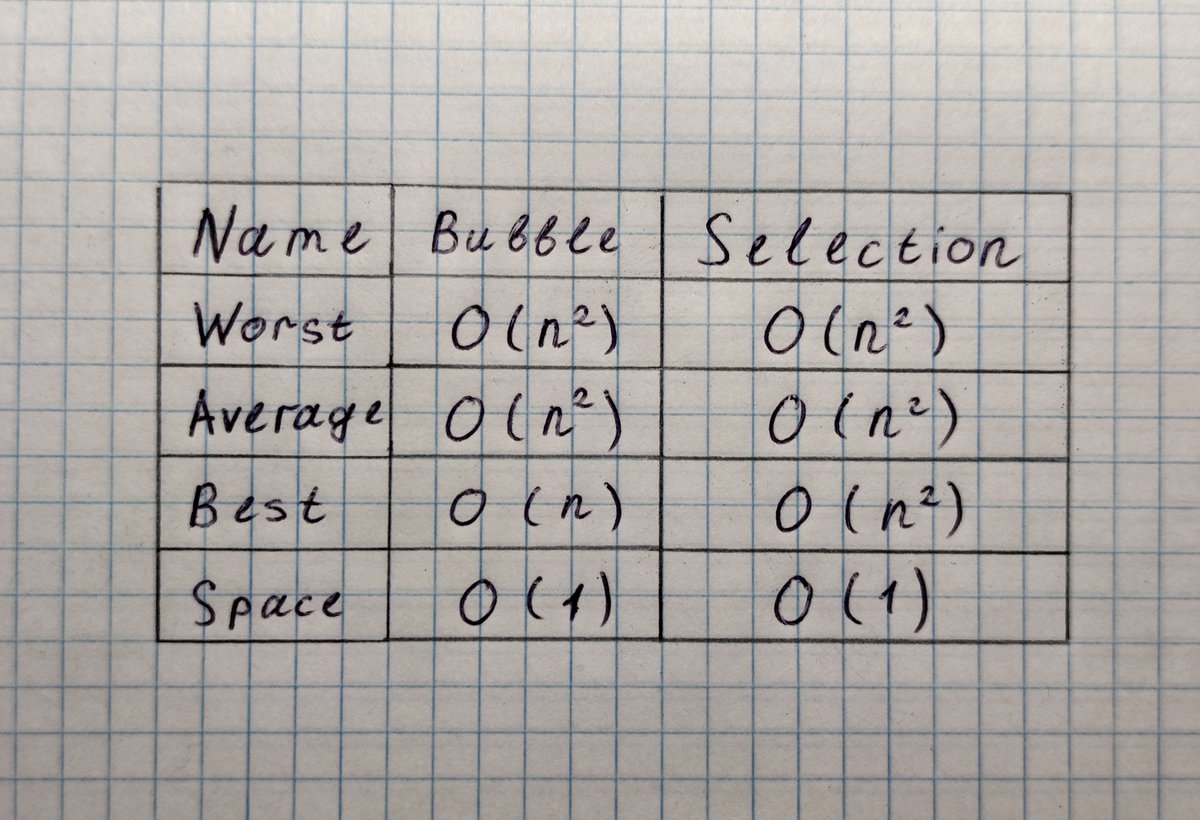
Последний герой на сегодня, Insertion Sort!

Insertion Sort, он же Сортировка Вставками. В отличие от предыдущих сортировок, тут мы обойдемся без хождений вокруг да около. Почему? Дед, халтуришь?
Дело в том, что эта сортировка очень похожа на предыдущий Selection Sort. Я даже за глаза его называю “Selection Sort наоборот”.
"Наоборот" не из-за другого направления сортировки, а из-за “обратности “самого принципа.
В Selection Sort мы искали наименьший элемент в правой части, присоединяли его на кончик левой и шли дальше. Самая дорогая операция — поиск наименьшего элемента.
В Selection Sort мы искали наименьший элемент в правой части, присоединяли его на кончик левой и шли дальше. Самая дорогая операция — поиск наименьшего элемента.
В Insertion Sort мы так же используем левую часть массива под отсортированную последовательность. Вот только логика немного другая: мы берём первый попавшийся элемент из правой части, и ищем, на какое место его вставить в левую.
Вставка в левую часть возможно оттого, что левая часть по своей конструкции всегда отсортирована. Значит, всё, что нужно сделать — найти подходящее место, сдвинуть всех правых соседей на одну позицию правее и вставить новый элемент на освободившееся место.
Как работает эта вставка? Немножко напоминает толкучку в общественном транспорте. Вошедший боксёр-тяжеловес в забитый трамвай, вероятно, спровоцирует движение всех мирно стоящих и уставших людей на пол шажочка от выхода.
Вот маленький пример этой вставки, только вместо трамвая у нас отсортированный массив.
В этом массиве содержится восемь чисел, а так же есть одно свободное место в конце. В массив мы хотим добавить число 5. Добавить, конечно, на правильное место. Выглядеть алгоритм будет так:
В этом массиве содержится восемь чисел, а так же есть одно свободное место в конце. В массив мы хотим добавить число 5. Добавить, конечно, на правильное место. Выглядеть алгоритм будет так:
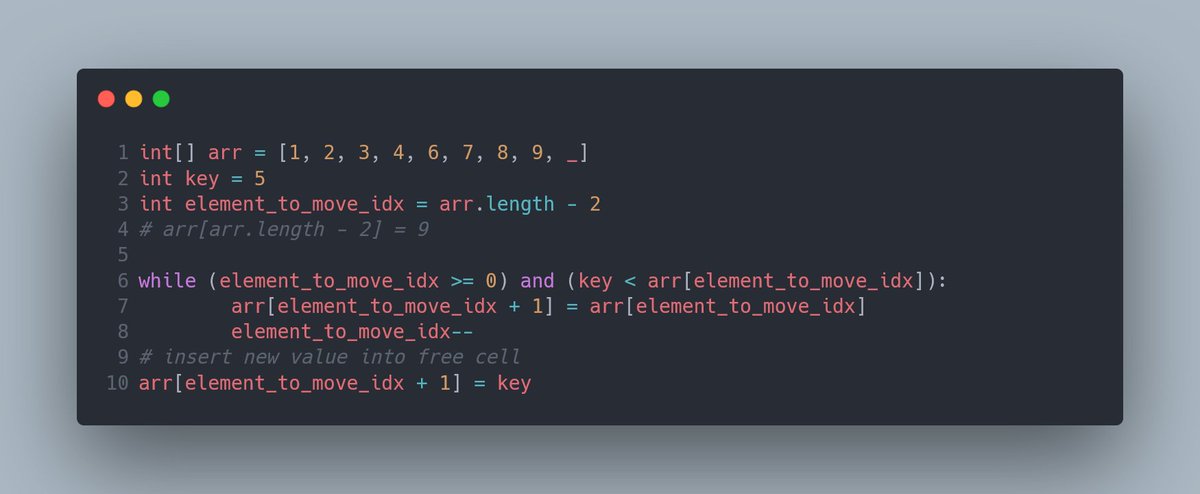
Как будет выглядеть передвигание чисел, которые больше пятерки? Начнётся оно вот так:

Обратите внимание на то, что справа от передвигаемого числа возникает его копия, а на следующей итерации оригинал перезаписывается.
И дойдёт сдвигание до такого вида:
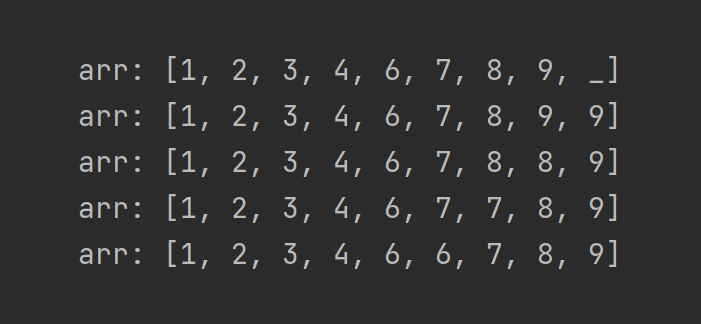
После чего, обнаружив четвёрку, цикл остановится, и запишет заветную пятёрку справа от четвёрки, на место “мусорной” шестёрки.

Предлагаю теперь взглянуть на код заветной сортировки вставками!
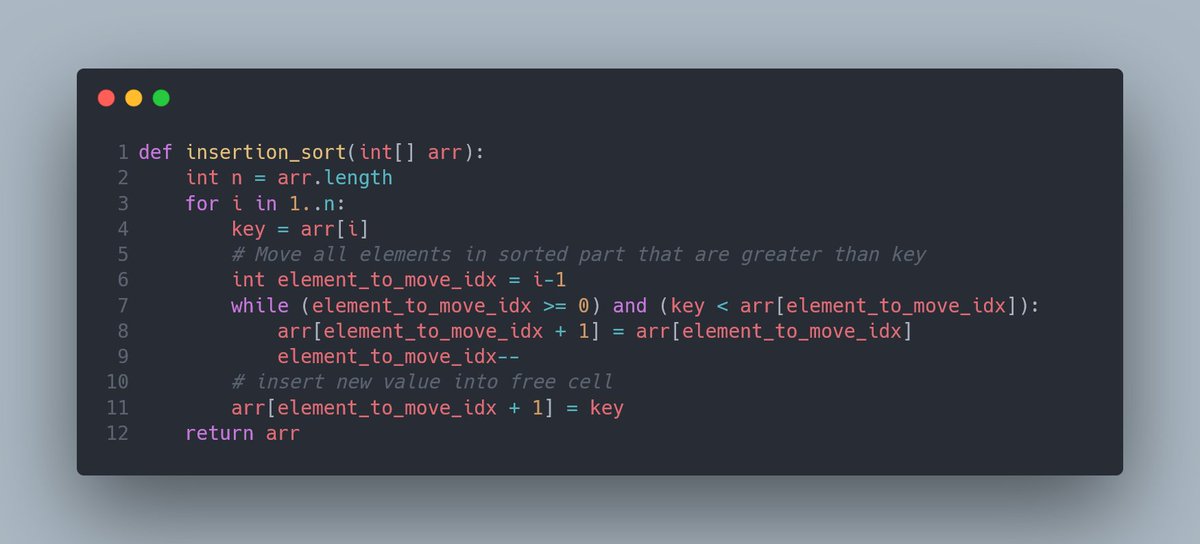
Помните пример из Selection Sort с барьером? Мне вот он понравился. Так как алгоритм похож, и принцип использования левой части массива под отсортированный массив, предлагаю не ходить вокруг да около и просто посмотреть на его работу:
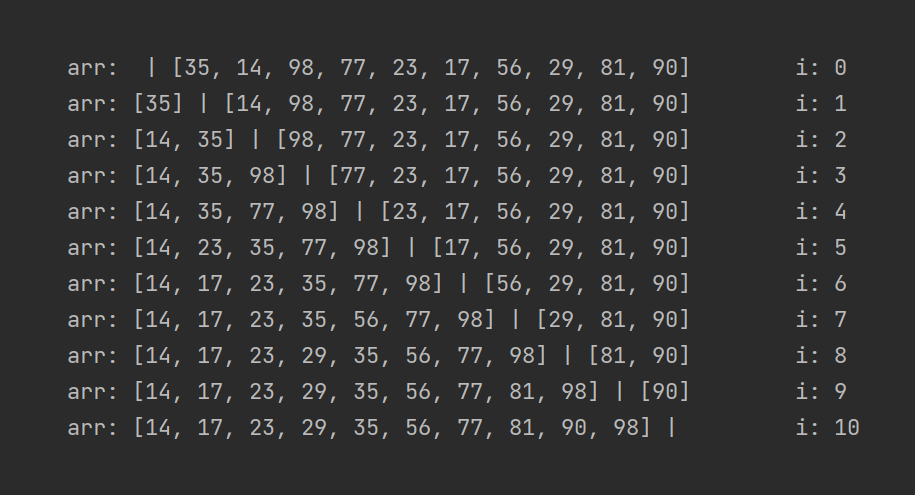
Вот тебе, бабушка, и Insertion Sort.
Нижняя граница производительности довольно привлекательна. Если массив уже отсортирован, то никакое сдвигание и не понадобится! Best Case этой сортировки составляет O(n).
Для протокола:

Мы разобрали Великую Троицу Сортировок, с которыми неизбежно сталкивается любой человек, изучающий алгоритмы. С чем я всех и поздравляю!
Теперь пришло время немножко поговорить о стабильности сортировок. Она же устойчивость, она же stability. Что это такое?
Если мы сортируем числа, то стабильность особой роли не играет. А вот если мы сортируем объекты, то очень даже. Например, у нас есть массив с записями о клиентах, и сортировать мы их будем по возрасту.
Возьмём для наглядности максимально простой вид записей, в формате [возраст : имя]
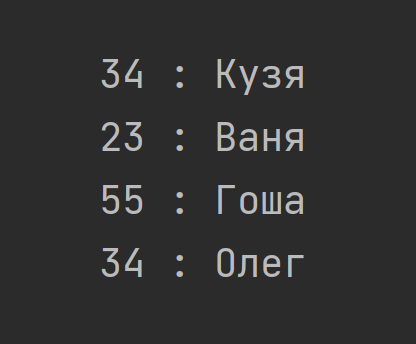
Стабильным называется алгоритм сортировки, который не меняет порядок элементов с одинаковыми ключами (возраст) относительно друг друга. В стабильном варианте после сортировки Кузя гарантированно будет раньше Олега, так как в оригинальных данных было так, а ключ одинаков.
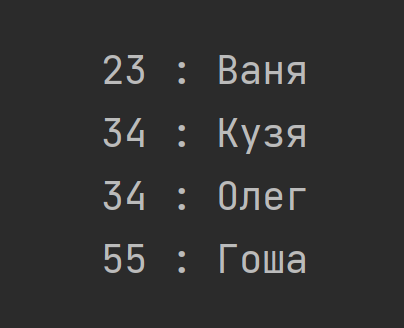
В нестабильном варианте допускается и второй сценарий:

Стабильность крайне важна, если мы планируем сортировать массив объектов по нескольким ключам. Например, сначала по возрасту, потом по размеру банковского счёта, и дальше по квадратным метрам жилплощади. Нестабильный алгоритм тут испортит нам всю малину.
Из нашей троицы стабильными являются Bubble Sort и Insertion Sort, а вот Selection Sort так и норовит перемешать элементы.
Докинем эту строчку в нашу табличку, чем приведем её в финальный вид:
Докинем эту строчку в нашу табличку, чем приведем её в финальный вид:
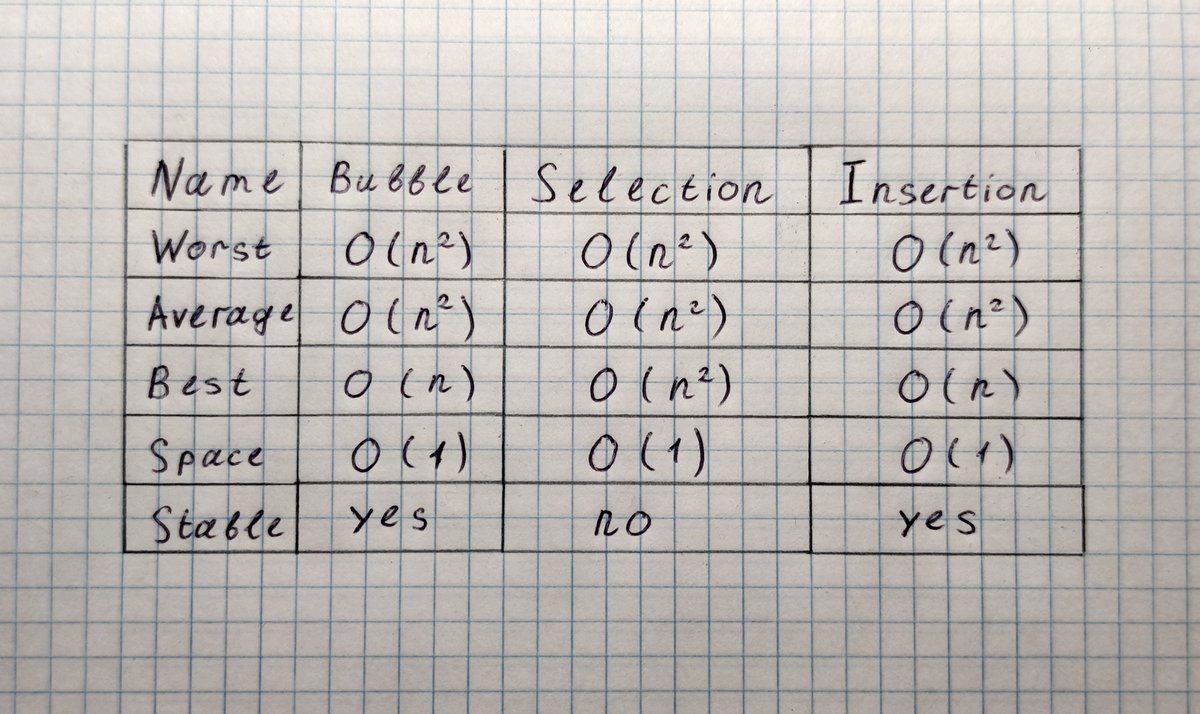
Помните, я обещал обсудить нюансы, выходящие за O-Нотацию и дополняющие её? Время перемывать косточки пришло!
Давайте посмотрим на массив, который почти идеально отсортирован. Одна беда — самый большой элемент в нём стоит на первом месте:
Давайте посмотрим на массив, который почти идеально отсортирован. Одна беда — самый большой элемент в нём стоит на первом месте:
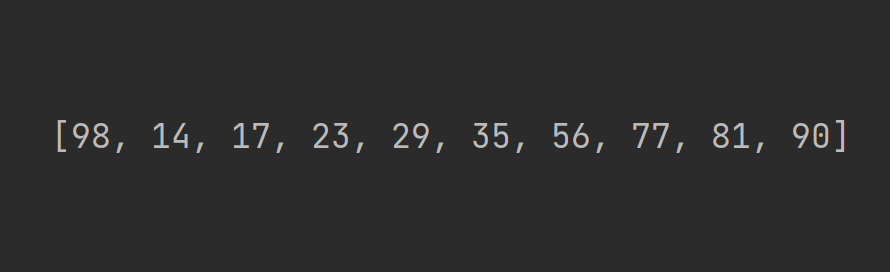
Как поведут себя наши алгоритмы сортировки?
Итак, Bubble Sort сработает великолепно — за n свопов массив будет готов к употреблению.
Insertion Sort тоже хорош в этом вопросе.
Итак, Bubble Sort сработает великолепно — за n свопов массив будет готов к употреблению.
Insertion Sort тоже хорош в этом вопросе.
А вот Selection Sort начнет чудить, и перелопатит со страшной расточительностью весь массив, получив O(n^2) по времени.
Проведите мысленный эксперимент, полезно для закрепления!
Проведите мысленный эксперимент, полезно для закрепления!
Если данные почти отсортированы, то Bubble Sort и Insertion Sort — наши лучшие друзья.
Теперь давайте подумаем про стоимость операций. В О-Нотации это опускается, но разные операции операциям рознь.
Прочесть ячейку массива — элементарно. Перезаписать ячейку массива — вроде бы тоже просто, да вот только многопоточность, обновление значений в кэше процессора, и многие другие факторы реального мира с нами не согласны.
Сойдемся сейчас на мысли, что на самом деле операция swap не так уж и проста, как кажется. Что у нас по количеству свопов?
Bubble Sort тут просто отбитый, свопает всё, свопает много, свопает, свопает, свопает. Количество операций записи, которые он выполняет, просто зашкаливает. Insertion Sort тоже не подарок — постоянное сдвигание вправо до добра не доведет.
А вот Selection Sort тут просто конфетка: всего n свопов в худшем случае! Очень экономный малый.
Итог: если поставлена задача экономить операции записи, то Selection Sort является рекордсменом!
Что до памяти, то наша троица в этом одинаково хороша. Все жрут O(1) памяти, то есть работают in-place.
Важно: алгоритмы сортировки можно улучшать. В основном эти улучшения касаются использования особых структур данных.
Маленький пример - Insertion Sort можно ускорить раза в два, а так же свести количество свопов к показателям Bubble Sort, если использовать не массив, а связный список.
А Selection Sort таки можно сделать стабильным.
А Selection Sort таки можно сделать стабильным.
О списках мы ещё поговорим в следующих тредах, так что пока не буду углубляться. Сейчас скажу только, что добавить элемент в середину такого списка — очень дешево, так как отпадает вся необходимость в сдвигании правых соседей по одному.
На этом наша долгая история про три базовые сортировки подходит к концу. Хотел сделать покороче, а вышло как всегда...
Код этих сортировок на разных языках программирования я приводить не буду, но всё можно найти по следующим ссылкам:
Bubble Sort: geeksforgeeks.org/bubble-sort/
Bubble Sort: geeksforgeeks.org/bubble-sort/
Selection Sort: geeksforgeeks.org/selection-sort/
Insertion Sort: geeksforgeeks.org/insertion-sort/
Визуализаций этих алгоритмов на ютубе пруд пруди. Из них всех я бы выделил вот это видео:
Также я люблю видосы с массивами с GeeksforGeeks, на страницах по ссылкам сверху. Отдельным мемом в этом вопросе являются Венгерские Танцы. Гуглится по запросу “sorting algorithms hungarian folk dance”. Там тонны хореографического фана!
На этом, мне кажется, тема простых сортировок исчерпана. В следующем треде по алгоритмам речь пойдёт про Merge Sort, а после него будет тред про Quick Sort. На этих алгоритмах я постараюсь залезть в материю поглубже.
Надеюсь, что получилось разобрать тему и никого не запутать. Как всегда, постараюсь ответить на все возникшие вопросы!
@threadreaderapp unroll
Этот тред доступен на моём гитхабе, в формате симпатичного pdf документа:
github.com/OratorX/twitte…
github.com/OratorX/twitte…
Гитхаб:
github.com/OratorX/twitte…
github.com/OratorX/twitte…
Тред в виде pdf-документа:
github.com/OratorX/twitte…
github.com/OratorX/twitte…
• • •
Missing some Tweet in this thread? You can try to
force a refresh