🚧 Muros de pago y SEO 🚧
El País (diario español) implementará un muro de pago freemium en breve (fuente: vozpopuli.com/medios/pais-nu…)
Pero, ¿sabes cómo funciona un muro de pago de cara al SEO?
Te lo cuento en este hilo.
El País (diario español) implementará un muro de pago freemium en breve (fuente: vozpopuli.com/medios/pais-nu…)
Pero, ¿sabes cómo funciona un muro de pago de cara al SEO?
Te lo cuento en este hilo.
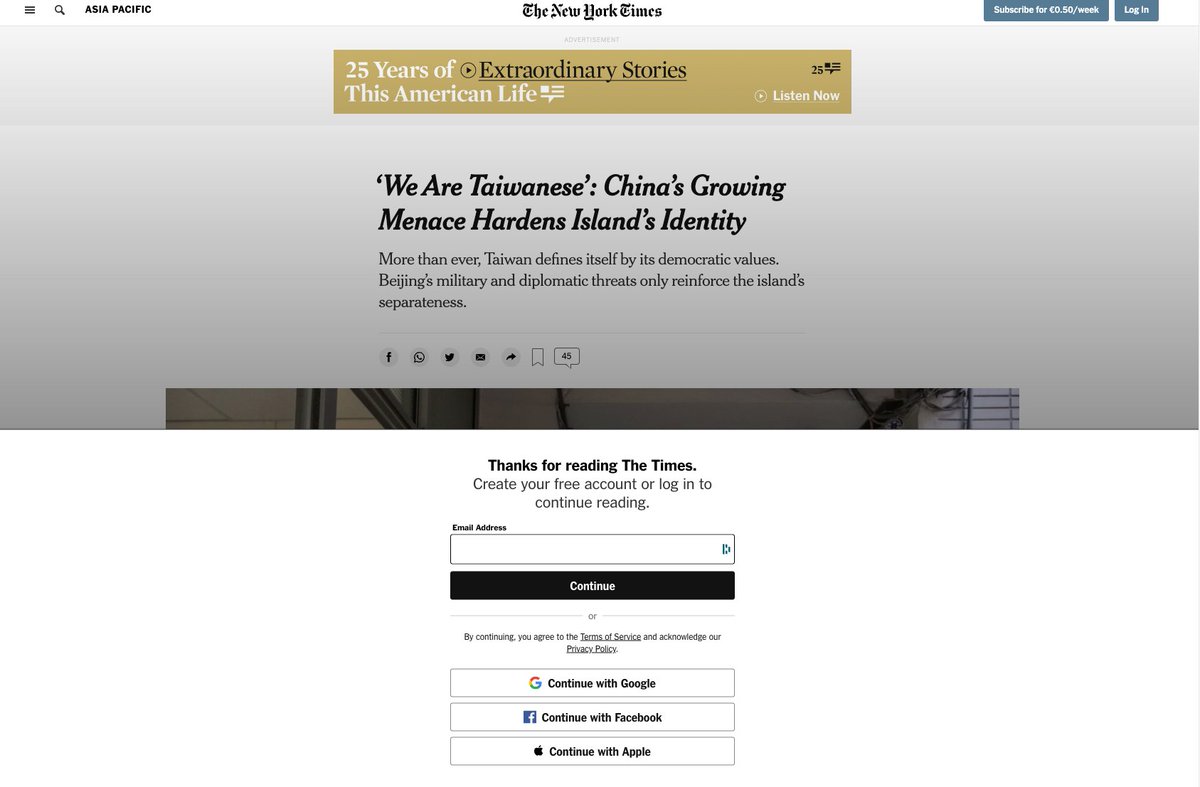
Si no lo sabes, un muro de pago es un mecanismo que te impide acceder a un contenido sin pagar.
Los diarios lo usan bastante para monetizar su audiencia. Para el New York Times, hablamos de más de 60% de sus ingresos (dato del 2017).
Los diarios lo usan bastante para monetizar su audiencia. Para el New York Times, hablamos de más de 60% de sus ingresos (dato del 2017).
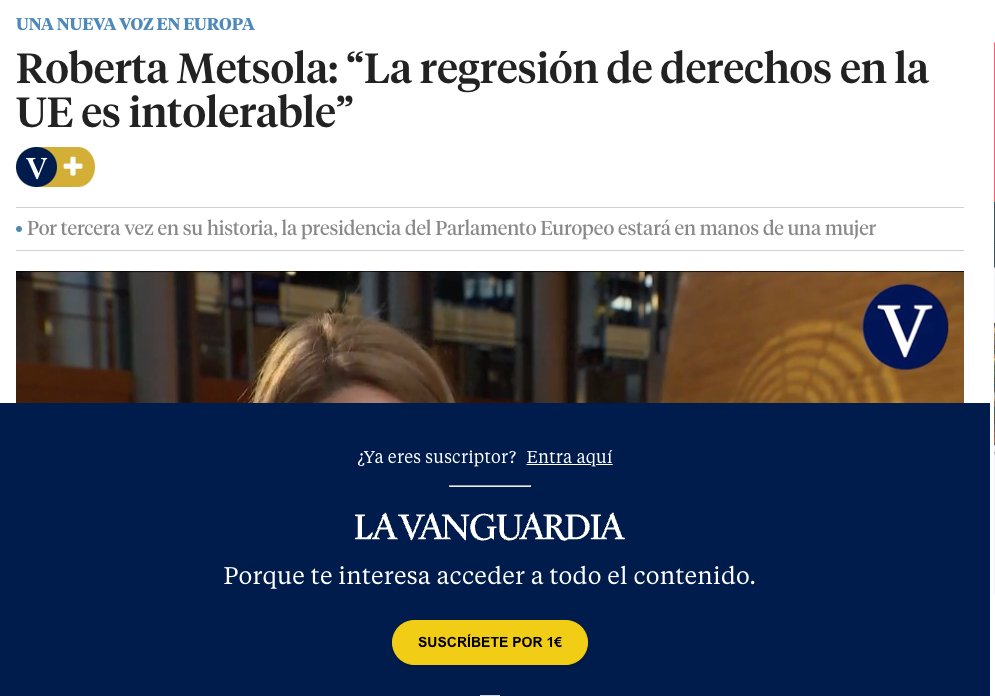
A Google no le gusta mucho los intersticiales que bloquean los contenidos.
Entonces, ¿cómo podemos posicionar un contenido bloqueado sin caer en SEO?
developers.google.com/search/blog/20…
Entonces, ¿cómo podemos posicionar un contenido bloqueado sin caer en SEO?
developers.google.com/search/blog/20…
Realmente, es bastante fácil y Google nos lo explica: developers.google.com/search/docs/ad…
Más allá del etiquetado clásico, tenemos que indicar qué parte de nuestro contenido se puede leer sin pagar.
Más allá del etiquetado clásico, tenemos que indicar qué parte de nuestro contenido se puede leer sin pagar.

En el diario francés Le Monde, existe una <div> con una class "paywall" donde incluyen todo el contenido de pago en sus artículos.
Ejemplo: lemonde.fr/planete/articl…
Fácil, ¿verdad?
Ejemplo: lemonde.fr/planete/articl…
Fácil, ¿verdad?

Para evitar que un usuario pueda consultar el artículo sin pagar igualmente :
1. Se suele impedir el uso del cache con el noarchive en la meta robots
2. Únicamente Googlebot (verificado) puede acceder al contenido completo
1. Se suele impedir el uso del cache con el noarchive en la meta robots
2. Únicamente Googlebot (verificado) puede acceder al contenido completo

Para comprobar el segundo punto, puedes acceder a un contenido bloqueado usando search.google.com/test/rich-resu… y verás que puedes ver todo.
Es une forma lícita de hacer cloaking realmente.
Es une forma lícita de hacer cloaking realmente.

Esa son las directrices oficiales. Ahora también puedes implementar algo ligeramente diferente.
En una implementación clásica, el contenido premium no estará en el código fuente si no eres Google.
En una implementación clásica, el contenido premium no estará en el código fuente si no eres Google.

En otros portales:
1. El contenido se carga completamente, como si fuese gratis
2. Mediante el valor de un cookie, una solicitud POST se hace, devolviendo una orden que muestra el muro de pago al usuario
Google lo ve como un contenido gratis.
1. El contenido se carga completamente, como si fuese gratis
2. Mediante el valor de un cookie, una solicitud POST se hace, devolviendo una orden que muestra el muro de pago al usuario
Google lo ve como un contenido gratis.

Esta implementación es menos estándar pero, desde mi perspectiva, funciona muy bien. Y no cambia nada para el usuario.
Eso sí, la implementación es más compleja pero supongo que hay un motivo :)
Eso sí, la implementación es más compleja pero supongo que hay un motivo :)
Para preguntas avanzadas sobre los muros de pago, creo que @ClaraSoteras y @mazariegos_seo te podrán ayudar más.
No te voy a engañar: en pocos proyectos he tenido que lidiar con este tema, así que tengo una visión muy teórica del tema :)
No te voy a engañar: en pocos proyectos he tenido que lidiar con este tema, así que tengo una visión muy teórica del tema :)
• • •
Missing some Tweet in this thread? You can try to
force a refresh