Update Modellrechnungen: Ausblick auf die nächsten 4-8 Wochen
Thread/Blog-Artikel: dirkpaessler.blog/2022/01/25/mod…
1/x
Thread/Blog-Artikel: dirkpaessler.blog/2022/01/25/mod…
1/x

Die letzte und diese Woche sind für das Modellieren der nächsten Wochen entscheidend wichtig. Dabei gibt es 3 Probleme:
2/x
2/x

Hinweis für Modellagnostilker: Was folgt sind Modell-Szenarien, die so kommen könnten, aber nicht müssen. Hier wird versucht mit Mathematik und Datenanalyse ein mehr-als-Raten-Blick in die Zukunft zu entwickeln.
3/x
3/x
Wer mit diesen sehr unterschiedlichen und unsicheren Szenarien für die Zukunft nicht gut zurecht kommt, der sucht sich bitte etwas anderes zu lesen.
4/x
4/x
Die folgende Modellbetrachtung basiert auf mehreren Arbeitsschritten: Zuerst brauchen wir mehrere modellierten Inzidenz/Fallzahlen-Verläufe. Dann müssen wir unsere Berechnung der Belastung der Kliniken kalibrieren mit den bisher verfügbaren Daten.
5/x
5/x
Daraus ergeben sich dann verschiedene Modellierungen für die Belastung der Kliniken und Intensivstationen.
6/x
6/x
Weiterer Verlauf der Fallzahlen
7/x
7/x

Nun kommt noch BA.1 Welle hinzu und Verlauf der Inzidenz sähe irgendwie so aus oder so ähnlich (Bitte immer im Hinterkopf halten: Wir können schon in dieser Woche die Fallzahlen nicht mehr richtig zählen, die hier gezeigten Inzidenzen wird das RKI so niemals melden):
8/x
8/x

Die obere Grafik ist Darstellung auf der Log-Skala, damit man den Ablauf der Wellen besser sehen kann. Die untere Darstellung zeigt die Gesamtinzidenz und wie sich diese aus den Varianten zusammensetzt. Damit haben für die weiteren Überlegungen unser “zentrales Szenario”.
9/x
9/x
10/x

11/x

12/x

13/x
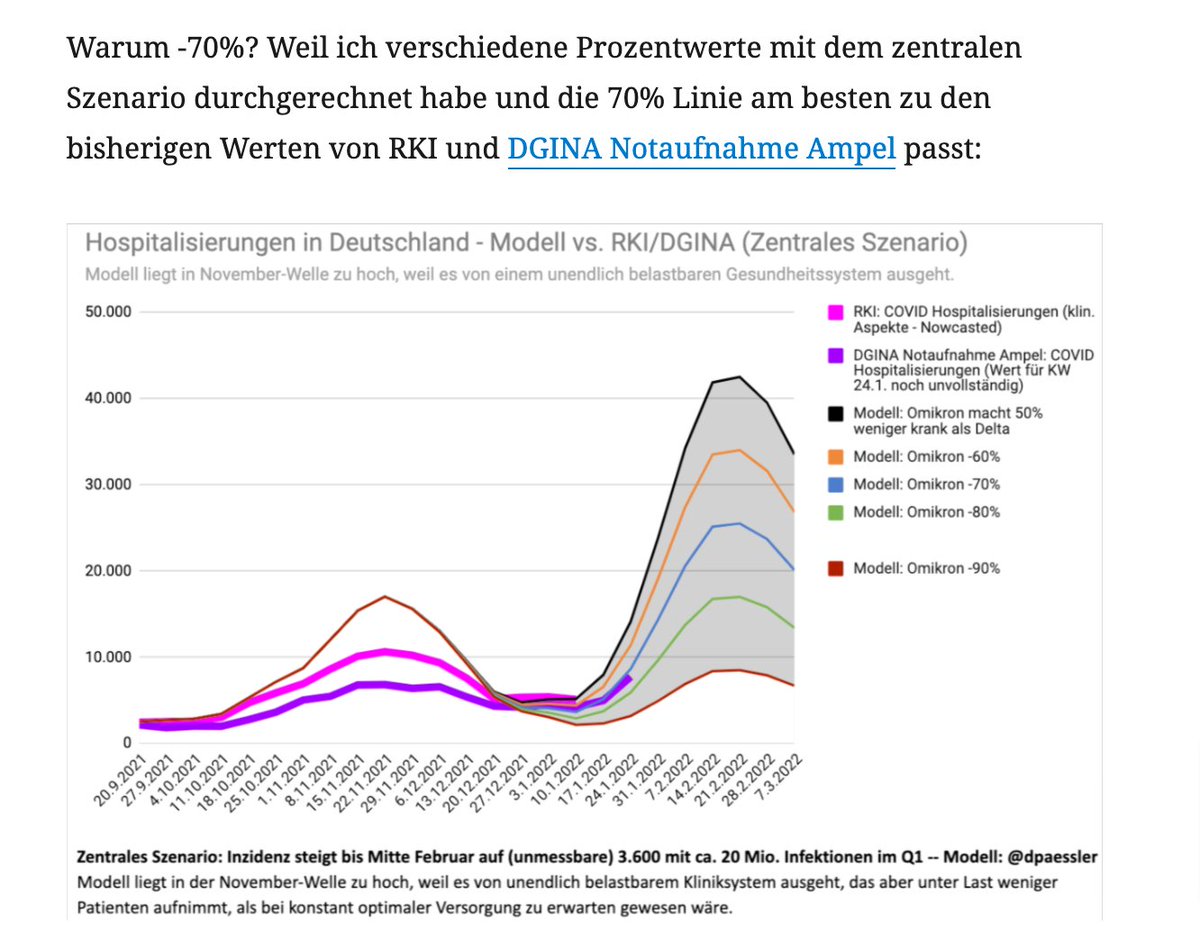
Hier habe ich die Hospitalisierungsdaten vom RKI und von meinem Modell nochmals nach Alter aufgeschlüsselt und da sieht man, dass das Modell sehr nah an den Kurven des RKI liegt – außer in den Wellen mit Überlastung des Gesundheitssystems (Q1/2021 und Q4/2021):
14/x
14/x

15/x

16/x

17/x

Hier der Link zum Blogartikel mit funktionierenden Links: dirkpaessler.blog/2022/01/25/mod…
Wer sich mit Rückblicken auf meine Modellrechnungen beschäftigen möchte, kann hier mal reinschauen:
https://twitter.com/dpaessler/status/1480830868201558018
• • •
Missing some Tweet in this thread? You can try to
force a refresh