1/
Miten indeksiin sijoittava selvännäkijä määrittäisi sijoitusasteensa?
Selvännäkijällä on kyky nähdä tulevaisuuteen 10 vuoden periodille kaksi parametria: Sharpe ratio ja volatiliteetti, ei muuta. Näillä tiedoilla voidaan valita tuoton maksimoiva sijoitusaste.
#sijoittaminen
Miten indeksiin sijoittava selvännäkijä määrittäisi sijoitusasteensa?
Selvännäkijällä on kyky nähdä tulevaisuuteen 10 vuoden periodille kaksi parametria: Sharpe ratio ja volatiliteetti, ei muuta. Näillä tiedoilla voidaan valita tuoton maksimoiva sijoitusaste.
#sijoittaminen
2/
@hkeskiva ketju käteisen optioarvosta innosti tutkimaan mikä voisi olla sijoitusaseen optimi pitkällä aikavälillä.
Yritänkin myös tässä ketjussani tutkia CAPEn kykyä ennustaa optimaalinen sijoitusaste.
@hkeskiva ketju käteisen optioarvosta innosti tutkimaan mikä voisi olla sijoitusaseen optimi pitkällä aikavälillä.
Yritänkin myös tässä ketjussani tutkia CAPEn kykyä ennustaa optimaalinen sijoitusaste.
https://twitter.com/hkeskiva/status/1484806544063614977?s=21
3/
Lähtökohtani on Kelly-kriteerin hyödyntäminen.
Kelly-kriteerin mukaan geometrisella keskituotolla on maksimi ns. Full Kelly -sijoitusasteella, jonka jälkeen lisäriski johtaa pienevään tuotto-odotukseen.
Sijoitusasteen kasvattamisella on siis vähenevä rajahyöty.
Lähtökohtani on Kelly-kriteerin hyödyntäminen.
Kelly-kriteerin mukaan geometrisella keskituotolla on maksimi ns. Full Kelly -sijoitusasteella, jonka jälkeen lisäriski johtaa pienevään tuotto-odotukseen.
Sijoitusasteen kasvattamisella on siis vähenevä rajahyöty.
4/
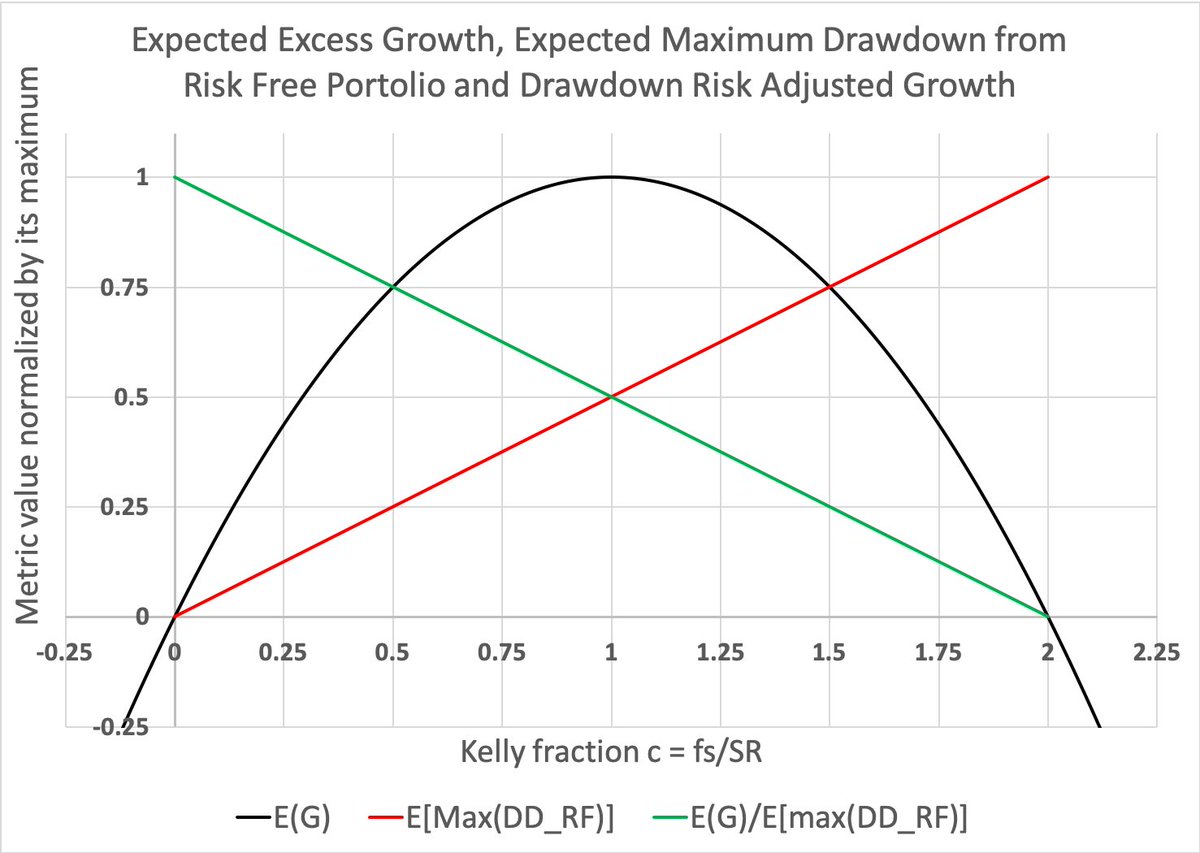
Maksimi CAGR tuottavalla Full Kelly -sijoitusasteella Kelly fraktio c = 1.
Puolikkaalla Kelly fraktiolla c=0.5 saavutetaan 75% maksimituotosta, mutta vain 50% volatiliteetista.
c=2 sijoitusasteella tiputaan riskittömän koron tuotto-odotukseen ja siitä edelleen miinukselle.
Maksimi CAGR tuottavalla Full Kelly -sijoitusasteella Kelly fraktio c = 1.
Puolikkaalla Kelly fraktiolla c=0.5 saavutetaan 75% maksimituotosta, mutta vain 50% volatiliteetista.
c=2 sijoitusasteella tiputaan riskittömän koron tuotto-odotukseen ja siitä edelleen miinukselle.

5/
Tuoton lisäksi sijoitusaste vaikuttaa riskiin.
Kelly fraktio yksinään määrittää sijoitushetken portfolion arvoon kohdistuvan maksimiarvonlaskuriskin (max-drawdown nykyarvosta) odotusarvon, joka on c/2 eli Full Kellyllä 50%.
Tarkemmin aiheesta: sijoitustieto.fi/sijoituskeskus…
Tuoton lisäksi sijoitusaste vaikuttaa riskiin.
Kelly fraktio yksinään määrittää sijoitushetken portfolion arvoon kohdistuvan maksimiarvonlaskuriskin (max-drawdown nykyarvosta) odotusarvon, joka on c/2 eli Full Kellyllä 50%.
Tarkemmin aiheesta: sijoitustieto.fi/sijoituskeskus…
6/
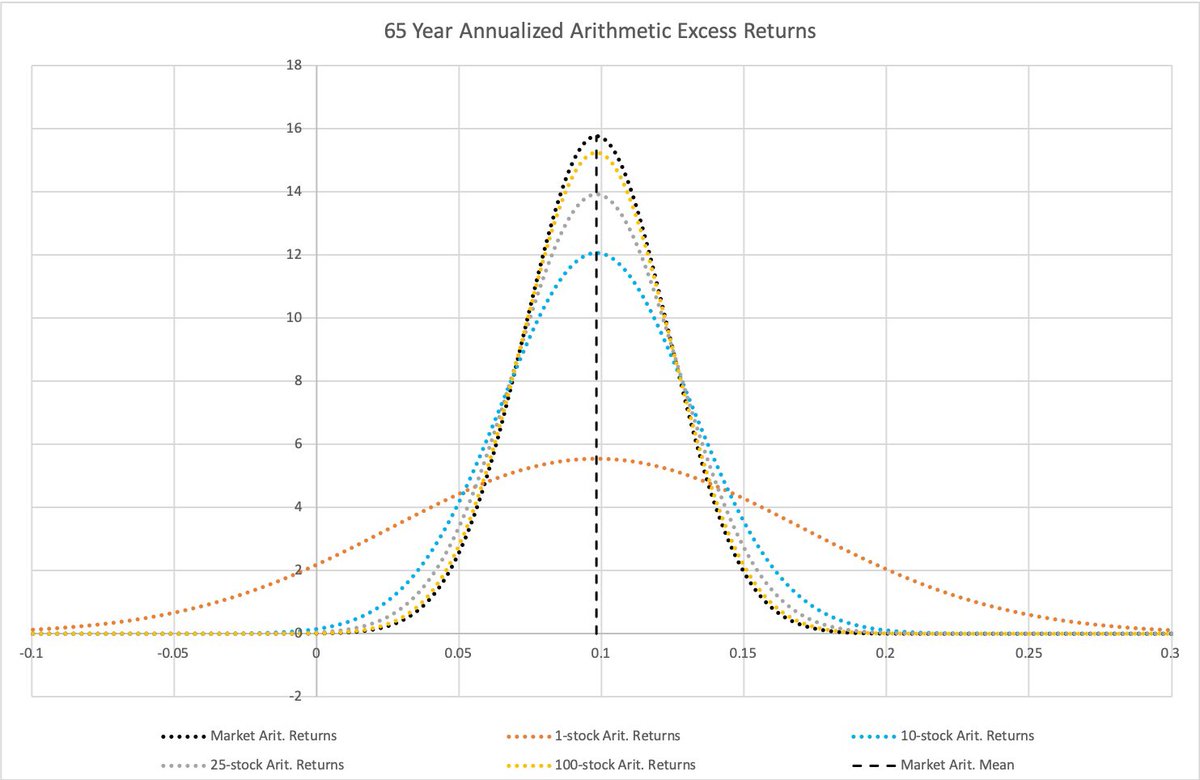
Tarkastellaan (French data) U.S. kuukausituottoja Jul/1926 – Jun-2021.
Kuvasta näemme maksimi-CAGRia janoavan selvännäkijän sijoitusasteen ajan funktiona. Vaihteluväli on hurja: Min: -1.83 (Oct-1964), Max: 14.36 (Jun-1949).
Optimisijoitusasteen määrittää Sharpe/Vola.
Tarkastellaan (French data) U.S. kuukausituottoja Jul/1926 – Jun-2021.
Kuvasta näemme maksimi-CAGRia janoavan selvännäkijän sijoitusasteen ajan funktiona. Vaihteluväli on hurja: Min: -1.83 (Oct-1964), Max: 14.36 (Jun-1949).
Optimisijoitusasteen määrittää Sharpe/Vola.

7/
Sijoitusaste seuraa Sharpen muotoa.
Sharpe seuraa aritmeettista riskittömän koron ylittävää keskituottoa, joka vaihtelee kovasti.
Volatiliteetin muutokset näyttävät rauhallisemmilta.
Tuotto-odotuksen ennustaminen näyttää oleelliselta sijoitusasteen valinnalle.
Sijoitusaste seuraa Sharpen muotoa.
Sharpe seuraa aritmeettista riskittömän koron ylittävää keskituottoa, joka vaihtelee kovasti.
Volatiliteetin muutokset näyttävät rauhallisemmilta.
Tuotto-odotuksen ennustaminen näyttää oleelliselta sijoitusasteen valinnalle.
8/
Kuten odotettua, optimisijoitusaste selvästi kasvaa aritmeettisen riskilisän (risk premium eli excess returnin keskiarvo) funktiona. Mutta muoto ei ole nätti suora vaan jokseenkin erikoinen viuhka.
Kuten odotettua, optimisijoitusaste selvästi kasvaa aritmeettisen riskilisän (risk premium eli excess returnin keskiarvo) funktiona. Mutta muoto ei ole nätti suora vaan jokseenkin erikoinen viuhka.

9/
Mistä moinen muoto?
CAGRn maksimoivaan sijoitusasteeseen vaikuttaa vain Sharpe ja vola. Sharpe itsessään koostuu mean excess returnista ja volasta, jolloin meille jää vain yksi selitys: Volatiliteetti.
Mistä moinen muoto?
CAGRn maksimoivaan sijoitusasteeseen vaikuttaa vain Sharpe ja vola. Sharpe itsessään koostuu mean excess returnista ja volasta, jolloin meille jää vain yksi selitys: Volatiliteetti.

10/
Entäpä saavutettavissa oleva maksimi-CAGR eli CAGR-kapasiteetti?
Sama juttu: tuotto-odotus on oleellinen, mutta huipputuotoille ei ole asiaa, ellei volatiliteetti ole hallinnassa eli riittävän alhainen (alle mediaanin).
Entäpä saavutettavissa oleva maksimi-CAGR eli CAGR-kapasiteetti?
Sama juttu: tuotto-odotus on oleellinen, mutta huipputuotoille ei ole asiaa, ellei volatiliteetti ole hallinnassa eli riittävän alhainen (alle mediaanin).

11/
Voimme myös katsoa CAGR-kapasiteettia volatiliteetin funktiona.
Värit edustavat nyt mean excess returnin neljänneksiä.
Kuva kertoo, että tuotto-odotuksen on oltava parhaassa neljänneksessä, jotta supertuotot ovat mahdollisia. Edelleen suuri vola tappaa CAGR-kapasiteetin.
Voimme myös katsoa CAGR-kapasiteettia volatiliteetin funktiona.
Värit edustavat nyt mean excess returnin neljänneksiä.
Kuva kertoo, että tuotto-odotuksen on oltava parhaassa neljänneksessä, jotta supertuotot ovat mahdollisia. Edelleen suuri vola tappaa CAGR-kapasiteetin.

12/
Päivän päätteeksi parametrien kuningas on kuitenkin Sharpe ratio.
Sharpe ratio yksinään määrittää geometrisen risk premiumin kapasiteetin (riskittömän koron päälle kertyvän maksimituoton) ja yhdessä riskittömän koron kanssa CAGR-kapasiteetin.
Päivän päätteeksi parametrien kuningas on kuitenkin Sharpe ratio.
Sharpe ratio yksinään määrittää geometrisen risk premiumin kapasiteetin (riskittömän koron päälle kertyvän maksimituoton) ja yhdessä riskittömän koron kanssa CAGR-kapasiteetin.

13/
Miltä maksimi-CAGR ja Full Kellyn drawdownit ovat näyttäneet historiassa?
CAGR on suuri, mutta ei yllä teoreettiseen arvoonsa, koska vipu rebalansoidaan liian harvoin (kuukausittain). 25 periodilla menetetään koko oma pääoma. Drawdownit järkyttänevät jopa selvännäkijää.
Miltä maksimi-CAGR ja Full Kellyn drawdownit ovat näyttäneet historiassa?
CAGR on suuri, mutta ei yllä teoreettiseen arvoonsa, koska vipu rebalansoidaan liian harvoin (kuukausittain). 25 periodilla menetetään koko oma pääoma. Drawdownit järkyttänevät jopa selvännäkijää.

14/
Puolittamalla maksimivipu päästään jo siedettävämmän näköisiin lukemiin.
Drawdownit ovat edelleen suuria, mutta odotetusti keskimäärin noin puolet maksimivivun vastaavista.
Kuukausittainen rabalansointi on riittävä ja realisoitunut CAGR on samaa luokkaa Full Kellyn kanssa.
Puolittamalla maksimivipu päästään jo siedettävämmän näköisiin lukemiin.
Drawdownit ovat edelleen suuria, mutta odotetusti keskimäärin noin puolet maksimivivun vastaavista.
Kuukausittainen rabalansointi on riittävä ja realisoitunut CAGR on samaa luokkaa Full Kellyn kanssa.

15/
0.265 Kellyllä päästään keskimäärin 100% osakeallokaatioon. Voimme siis verrata dynaamista selvännäkijän allokaatiota staattiseen 100% allokaatioon.
GAGR on suurempi ja erityisesti maksimi drawdownit ovat pienempiä. Mean(CAGR)/mean(maxDD) on noin 2.5-kertainen.
0.265 Kellyllä päästään keskimäärin 100% osakeallokaatioon. Voimme siis verrata dynaamista selvännäkijän allokaatiota staattiseen 100% allokaatioon.
GAGR on suurempi ja erityisesti maksimi drawdownit ovat pienempiä. Mean(CAGR)/mean(maxDD) on noin 2.5-kertainen.

16/
10 vuoden periodiin ja kahteen parametriin rajoitettu selvännäkijä siis odotetusti hakkaa staattisen allokaation sekä CAGRlla mitattuna, että riskikorjattuna.
Me kuolevaiset emme näe tulevaisuutta, jolloin olemme pakotettuja ennusteisiin ja peli vaikeutuu kertaheitolla.
10 vuoden periodiin ja kahteen parametriin rajoitettu selvännäkijä siis odotetusti hakkaa staattisen allokaation sekä CAGRlla mitattuna, että riskikorjattuna.
Me kuolevaiset emme näe tulevaisuutta, jolloin olemme pakotettuja ennusteisiin ja peli vaikeutuu kertaheitolla.
17/
CAPE tunnetusti ennustaa pitkän aikavälin tuottoja, joten kokeillaan sitä.
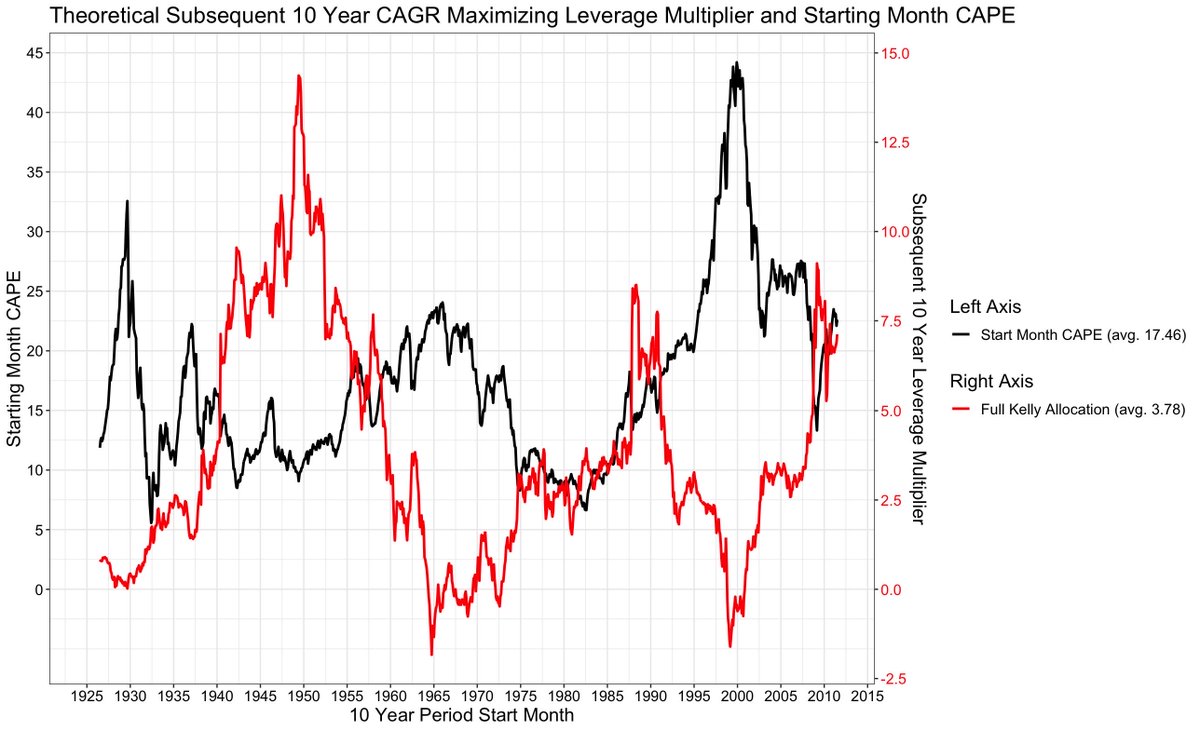
Katsotaan ensin silmällä. CAPElla ja optimaalisella seuraavan 10 vuoden sijoitusasteella näyttäisi olevan negatiivinen korrelaatio.
CAPE tunnetusti ennustaa pitkän aikavälin tuottoja, joten kokeillaan sitä.
Katsotaan ensin silmällä. CAPElla ja optimaalisella seuraavan 10 vuoden sijoitusasteella näyttäisi olevan negatiivinen korrelaatio.
18/
Mutta se sama viuhkamainen muoto on näkyvillä myös CAPEn ennustamassa sijoitusasteessa.
Suurella CAPElla on selkeästi vaadittu pieni allokaatio, mutta pienellä CAPElla volatiliteetti nousee taas ratkaisevaksi tekijäksi ja CAPE yksin ei anna selkeää vastausta.
Mutta se sama viuhkamainen muoto on näkyvillä myös CAPEn ennustamassa sijoitusasteessa.
Suurella CAPElla on selkeästi vaadittu pieni allokaatio, mutta pienellä CAPElla volatiliteetti nousee taas ratkaisevaksi tekijäksi ja CAPE yksin ei anna selkeää vastausta.

19/
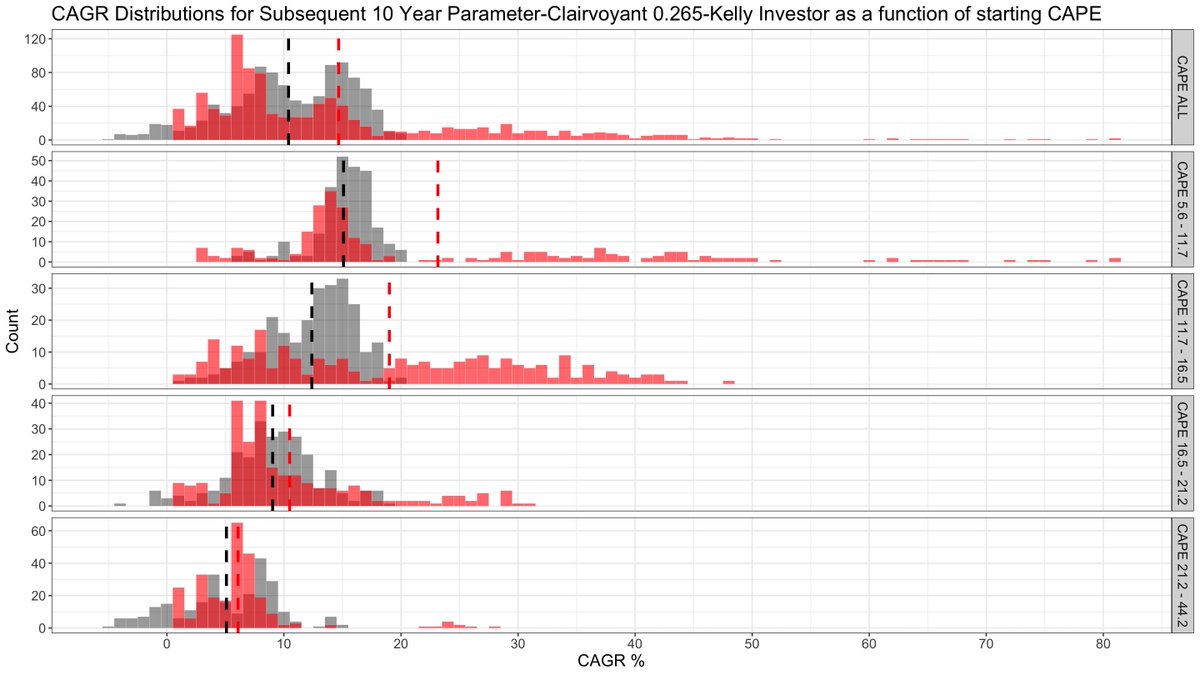
Tarkastellaan sijoitusasteen jakaumia CAPE-neljänneksittäin 0.265-Kelly allokaatiolla (keskimäärin 100% allokaatio).
Allokaatio on keskiarvona 1.4 kun CAPE on alle mediaaninsa ja laskee alle 0.5 kun CAPE on kalleimmillaan. Halvalla CAPElla on ikävän paljon hajontaa.
Tarkastellaan sijoitusasteen jakaumia CAPE-neljänneksittäin 0.265-Kelly allokaatiolla (keskimäärin 100% allokaatio).
Allokaatio on keskiarvona 1.4 kun CAPE on alle mediaaninsa ja laskee alle 0.5 kun CAPE on kalleimmillaan. Halvalla CAPElla on ikävän paljon hajontaa.

20/
CAGR (punainen dynaaminen 0.265-Kelly, musta/harmaa staattinen strategia) etu syntyy CAPEn ollessa alle mediaaninsa.
Etu kuitenkin näyttää syntyvän pitkälti harvinaisemmista supertuotoista, jotka ovat CAPE-neljänneksen sisällä onnistuneesti ajoitetun vivun tuottamia.
CAGR (punainen dynaaminen 0.265-Kelly, musta/harmaa staattinen strategia) etu syntyy CAPEn ollessa alle mediaaninsa.
Etu kuitenkin näyttää syntyvän pitkälti harvinaisemmista supertuotoista, jotka ovat CAPE-neljänneksen sisällä onnistuneesti ajoitetun vivun tuottamia.
21/
Dynaaminen selvännäkijä välttää kalliille CAPElle tyypilliset suuret drawdownit tehokkaasti.
Pieni allokaatio kalliin CAPEn aikana auttaa. Selvännäkijä pystyykin pitämään drawdown-riskinsä hyvin vakiona CAPEsta riippumatta.
Dynaaminen selvännäkijä välttää kalliille CAPElle tyypilliset suuret drawdownit tehokkaasti.
Pieni allokaatio kalliin CAPEn aikana auttaa. Selvännäkijä pystyykin pitämään drawdown-riskinsä hyvin vakiona CAPEsta riippumatta.

22/
Yhteenvetona:
Sharpe määrittää riskikorjatun tuoton, mutta myös CAGR kapasiteetin.
Volalla on suuri rooli optimaalisen sijoitusasteen kannalta.
CAPE ennustaa optimaalista sijoitusastetta, mutta sen ennustusvoima yksinään vaikuttaa heikolta halvassa markkinassa.
/END
Yhteenvetona:
Sharpe määrittää riskikorjatun tuoton, mutta myös CAGR kapasiteetin.
Volalla on suuri rooli optimaalisen sijoitusasteen kannalta.
CAPE ennustaa optimaalista sijoitusastetta, mutta sen ennustusvoima yksinään vaikuttaa heikolta halvassa markkinassa.
/END
• • •
Missing some Tweet in this thread? You can try to
force a refresh