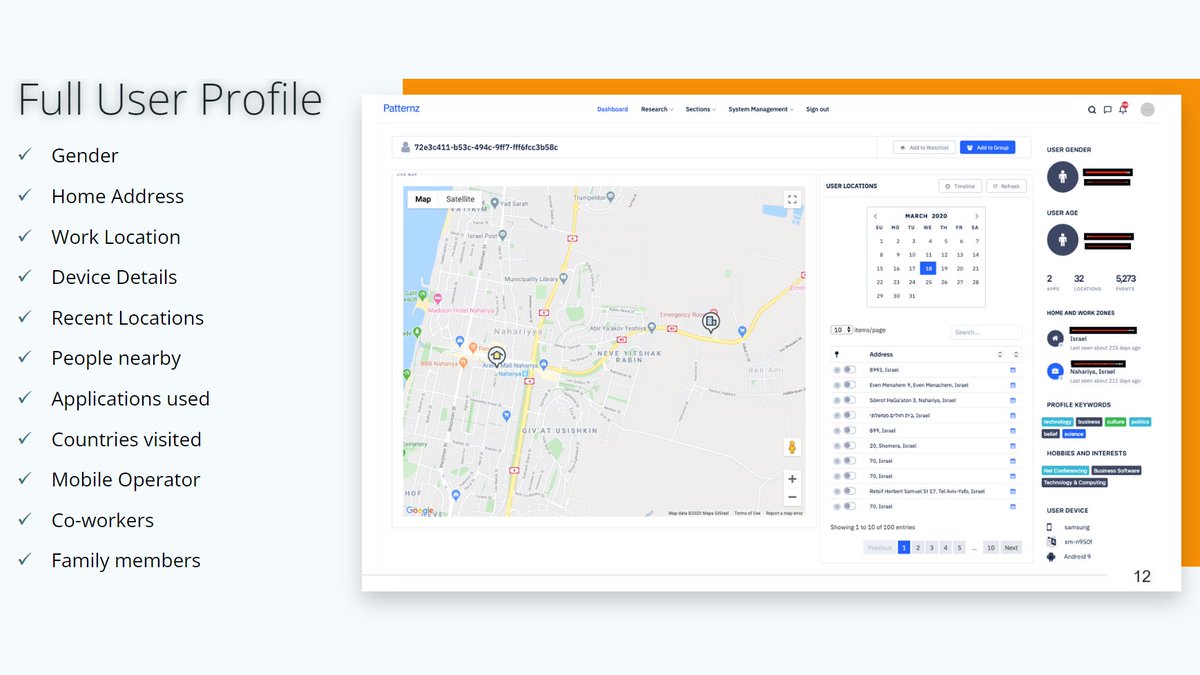
I want to share some more details about what we found in our investigation into gambling data that are highly relevant to GDPR enforcement and privacy regulation at large.
For example, this is how companies share personal data with each other during a bunch of 'cookie syncs'.
For example, this is how companies share personal data with each other during a bunch of 'cookie syncs'.

I guess rarely anyone has ever analyzed the data flows during only a few 'cookie syncs' at such a level of detail.
It's not about 'cookies' but about an ongoing exchange of personal identifiers that many data companies use to recognize, track and follow everyone across websites.
It's not about 'cookies' but about an ongoing exchange of personal identifiers that many data companies use to recognize, track and follow everyone across websites.
The chart shows data transmissions we observed during only a few visits to skycasino.com, which initiated requests to the adtech firm MediaMath, which shared the ID it uses to recognize a user with many other firms and initiated further personal data processing by them.

During a few visits to skycasino.com:
- MediaMath sent its personal ID for the user to 14 third-party firms, 3 third parties sent their own IDs to MediaMath
- In addition, MediaMath directly or indirectly initiated extensive personal data processing by 19 third parties
- MediaMath sent its personal ID for the user to 14 third-party firms, 3 third parties sent their own IDs to MediaMath
- In addition, MediaMath directly or indirectly initiated extensive personal data processing by 19 third parties

- All 19 third parties *received* their own company-specific ID they stored in a cookie in the user's browser before
- 16 third parties also *stored* their company-specific ID in the browser
- We observed 17 firms processing the *same* ID during a visit to another website, Unibet
- 16 third parties also *stored* their company-specific ID in the browser
- We observed 17 firms processing the *same* ID during a visit to another website, Unibet

- In addition, several third parties exchanged IDs directly with each other, e.g. we observed the identity surveillance firm ID5 receiving IDs from 4 companies and sending its own ID to 2 companies
- Some firms stored the MediaMath ID in a cookie associated with their own domain
- Some firms stored the MediaMath ID in a cookie associated with their own domain

- As a side effect, several companies learned that the user visited skycasino.com, because requests included that data in the HTTP referer.
Some of them may use this data for profiling.
Most of them gained the capability to better track+follow people across the web.
Some of them may use this data for profiling.
Most of them gained the capability to better track+follow people across the web.

All this personal data processing by MediaMath and the other companies occured because the skycasino.com website embedded third-party technology into its website.
As such, SkyBet/SBG directly or indirectly facilitates this personal data processing by third parties.
As such, SkyBet/SBG directly or indirectly facilitates this personal data processing by third parties.

As soon as these third parties exploit their increased capability to follow people on the web or their knowledge about the fact that a user visited a specific site for their own purposes, the site may even (co)facilitate personal data processing in a completely different context.
This happened during a few visits to a single website. It happens hundreds of times a day for everyone of us, and billions of times across the web.
One firm sharing a single ID with another may seem meaningless, but at scale it turns into a commercial mass surveillance system.
One firm sharing a single ID with another may seem meaningless, but at scale it turns into a commercial mass surveillance system.
The technical report contains a detailed analysis of the HTTP requests that were part of the data processing activities described above (p79).
The main report contains a summary of our findings on MediaMath's data processing (p47).
Both available here:
crackedlabs.org/en/gambling-da…
The main report contains a summary of our findings on MediaMath's data processing (p47).
Both available here:
crackedlabs.org/en/gambling-da…
Here's an example that shows how MediaMath sends its ID retrieved from the user's browser to Salesforce, who can then match it with its own ID retrieved from the browser.
Salesforce also *stores* its ID in the browser, which it can later retrieve during visits to other websites.
Salesforce also *stores* its ID in the browser, which it can later retrieve during visits to other websites.

Read about the core findings of our investigation in my other threads:
The technical report also contains a methodology section that describes how we observed and analyzed personal data flows in the web browser (p. 123ff).
https://twitter.com/WolfieChristl/status/1488120672610140161
https://twitter.com/WolfieChristl/status/1486670265283186689
The technical report also contains a methodology section that describes how we observed and analyzed personal data flows in the web browser (p. 123ff).

We examined network traffic recorded during a series of 37 visits to 3 websites operated by Sky Bet and 10 visits to websites operated by other companies.
- New Win10 laptop connected to the Internet at a person's home in the UK, Chrome browser
- New Win10 laptop connected to the Internet at a person's home in the UK, Chrome browser
- The person made manual website visits, no automation
- Network traffic was recorded with Chrome's developer tools and manually stored in HAR format after each visit
- I analyzed the resulting HAR/json files manually and with the help of grep, some custom Python code and Fiddler
- Network traffic was recorded with Chrome's developer tools and manually stored in HAR format after each visit
- I analyzed the resulting HAR/json files manually and with the help of grep, some custom Python code and Fiddler

I think, examining network traffic resulting from a series of website visits *over time* is a promising approach to investigate personal data flows, for EU authorities, for audit purposes, academic research - in addition to testing single visits or large-scale automated testing.
For example, I discovered how Google periodically replaces its 'IDE' identifier with a new version of the identifier across visits to websites operated by different companies.
Each time, you see 'response cookie' in a row, Google read the old identifier and stored a new version.
Each time, you see 'response cookie' in a row, Google read the old identifier and stored a new version.


Google processed eight versions of its 'IDE' identifier between Feb 25 and Mar 9, 2021. We missed one replacement because we didn't record every visit.
The user who made these website visits didn't have a Google account. Nevertheless, Google is able to track them across the web.
The user who made these website visits didn't have a Google account. Nevertheless, Google is able to track them across the web.
Websites that embed Google/DoubleClick (co)facilitate Google's capability to track people across the web, especially if they let Google *store* new versions of the IDE identifier in the browser so G can access them during visits to other sites.
See p 201 in the technical report.
See p 201 in the technical report.

Other companies use a simpler approach to track and follow people across the web.
For example, TransUnion's marketing data firm Signal always uses the same ID. Every visit to a site that embeds Signal made the company both receiving its ID from the browser and storing it again.
For example, TransUnion's marketing data firm Signal always uses the same ID. Every visit to a site that embeds Signal made the company both receiving its ID from the browser and storing it again.

We also observed Xandr, an adtech company and data broker previously owned by AT&T and now acquired by Microsoft, receiving the same personal ID from the user's browser and storing it again across every visit to websites operated by Sky Bet and by other companies in the same way.

Same with Adobe, who also received the same 'demdex' ID across different websites and stored it again, and with Iovation, another TransUnion company that is not in adtech but in identity verification and fraud detection and claims to track 7 billion 'consumer devices' globally.

We observed Iovation receiving the same identifier from the user's browser across visits to websites operated by several gambling companies, and storing it in the browser again.
Sky Bet facilitated the initial request to Iovation and thus the initial creation of the Iovation ID.
Sky Bet facilitated the initial request to Iovation and thus the initial creation of the Iovation ID.

As laid out in the technical report, companies like Iovation, Signal, Xandr, Adobe or Google who constantly receive personal IDs and store them back to the browser would not be able to track people across the web if websites like skycasino.com would not facilitate that.
I am not a lawyer, assessing legal issues is @RaviNa1k's job. In my personal opinion, our findings suggest the GDPR data controller Sky Bet is jointly responsible for personal data processing by those companies that relies on their capability to recognize people across the web.
While Iovation, Signal, Adobe, Xandr and Google both received and stored the same ID in the user's browser across visits to websites operated by Sky Bet and by others, FB, Microsoft and MediaMath 'only' always received the same ID. But, they could also exploit data across sites.

Of course, all that data processing actually shouldn't happen anymore, at least not in the EU/UK almost four years into the GDPR. Enforcement failed for many reasons, including massive pseudo compliance efforts by the industry and under-resourced, spineless or even captured DPAs.
Anyway, I think one reason for why enforcement is still failing is a lack of understanding and evidence of how very limited, ephemeral and distributed personal data processing across many actors can scale to a massive violation of rights and freedoms.
https://twitter.com/WolfieChristl/status/1488190741172178945
Correction, the third sentence in the Salesforce box at the top left should read "Received the same Salesforce ID during..." instead of "Received the same Neustar ID during". Thanks @Bleibpassiv!
Here's a corrected version of the infographic (v1.1)
Here's a corrected version of the infographic (v1.1)

Because some were asking about 'consent' et al:
This is how the 'consent' banner looked like when we did the tests. They didn't even use a TCF-based CMP for pseudo-compliance. No 'decline' button, instead "by scrolling, clicking or navigating our site, you consent"
Meaningless.
This is how the 'consent' banner looked like when we did the tests. They didn't even use a TCF-based CMP for pseudo-compliance. No 'decline' button, instead "by scrolling, clicking or navigating our site, you consent"
Meaningless.

• • •
Missing some Tweet in this thread? You can try to
force a refresh