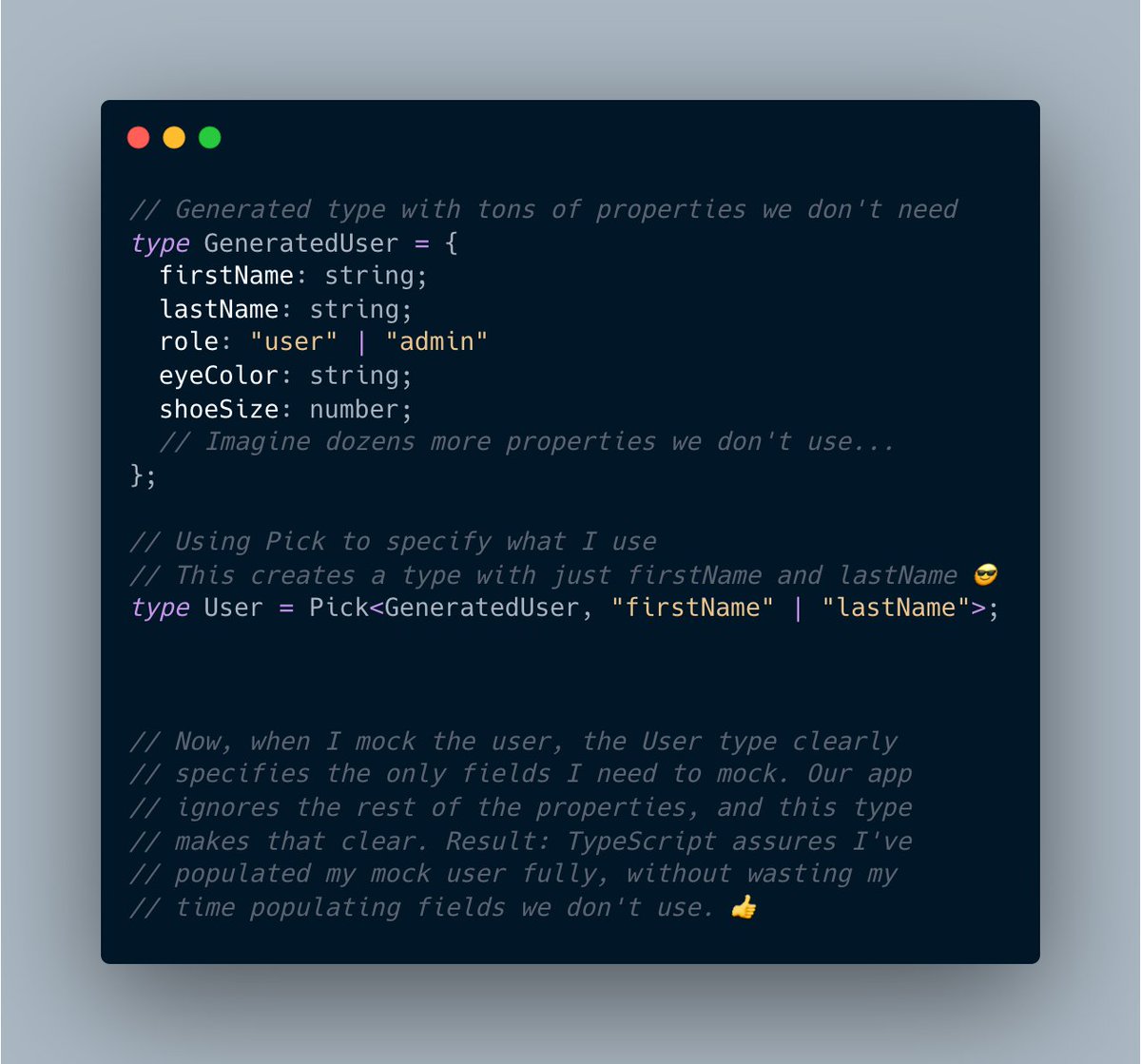
Habit: When declaring REST API response types via #TypeScript, I only declare properties for the fields we use.
Benefits:
1. The type is simpler.
2. The type contains no noise. All properties are relevant.
3. The type is handy for mocks. It declares only the properties we use.👍
Benefits:
1. The type is simpler.
2. The type contains no noise. All properties are relevant.
3. The type is handy for mocks. It declares only the properties we use.👍

This tip applies to GraphQL too. I don't want to work with a generated response type that contains 100 optional properties if we only use 5. So when in GraphQL, I create a type for each unique query.
To clarify, generated types are great. 👍 I just don't want to use them directly because they often contain properties I don't need or use.
So, I use TypeScript's Pick or Omit utility functions to derive my own more narrow types.
Example:
So, I use TypeScript's Pick or Omit utility functions to derive my own more narrow types.
Example:
• • •
Missing some Tweet in this thread? You can try to
force a refresh