My sister @JMollick produced #TheDropout - the new Hulu series on Elizabeth Holmes. In addition to being entertaining, it also shows some drivers of success in entrepreneurship.
So: a 🧵 of research on Theranos, and what honest investors & founders can learn from the lies. 1/
So: a 🧵 of research on Theranos, and what honest investors & founders can learn from the lies. 1/
https://twitter.com/thedropouthulu/status/1499459593629421584
Much of the fraud was explained by "Symbolic Action." In a classic paper, Zott & Huy find that founders who skillfully use symbols do better, since folks view the symbols as indicators of real ability. They identify four categories of symbolic action, all exploited by Holmes 2/ 


The first category is showing personal capability, and the paper describes multiple ways of doing this: you can look the part of the entrepreneur; you can conspicuously show connections to top schools; or you can show that you are personally "all in." Elizabeth did all three. 3/



The 2nd category is showing that you are organized like a real professional organization. Common ways for entrepreneurs to indicate this are to have professional office spaces and the trappings of what people expect to see in a real firm. Elizabeth was very aware of this. 4/


The third category is to show symbols that your business can achieve its goals. The three classic ways to do this are to show off half-working prototypes, win industry awards, and show that you have received money from prestigious funders. 5/



Finally, we have a demonstration of key stakeholders, because if important people back your company, it must be good right? See the Theranos Board! (Of course, this didn’t convince real biotech VCs, who would have wanted to see stakeholders in the medical field.) 6/


And Holmes also was very good at pitching. This paper shows how she pitched Theranos using powerful techniques:
🖼Framing: Why the world needs improvement
💉Filling: Vivid images of how she would solve it
👥Connecting: Showing others trusted her
💪Committing: Showing dedication
7
🖼Framing: Why the world needs improvement
💉Filling: Vivid images of how she would solve it
👥Connecting: Showing others trusted her
💪Committing: Showing dedication
7



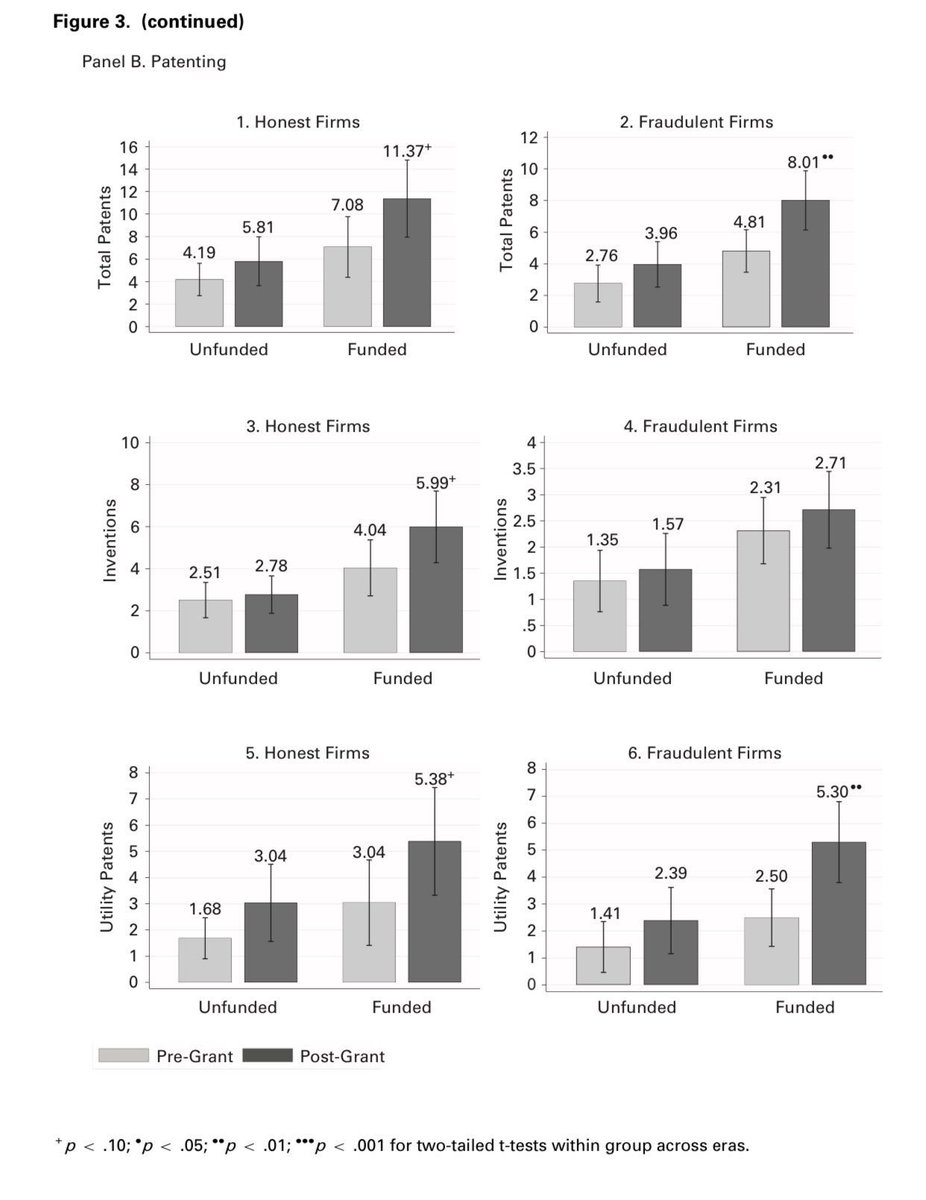
Unethical startups are more likely to raise 💰 but also tend to waste it, hurting overall innovation. By comparing 2 sets of books, this paper identifies Chinese startups that got grants via fraud. Frauds were less likely to hire quality people & to conduct significant innovation


• • •
Missing some Tweet in this thread? You can try to
force a refresh