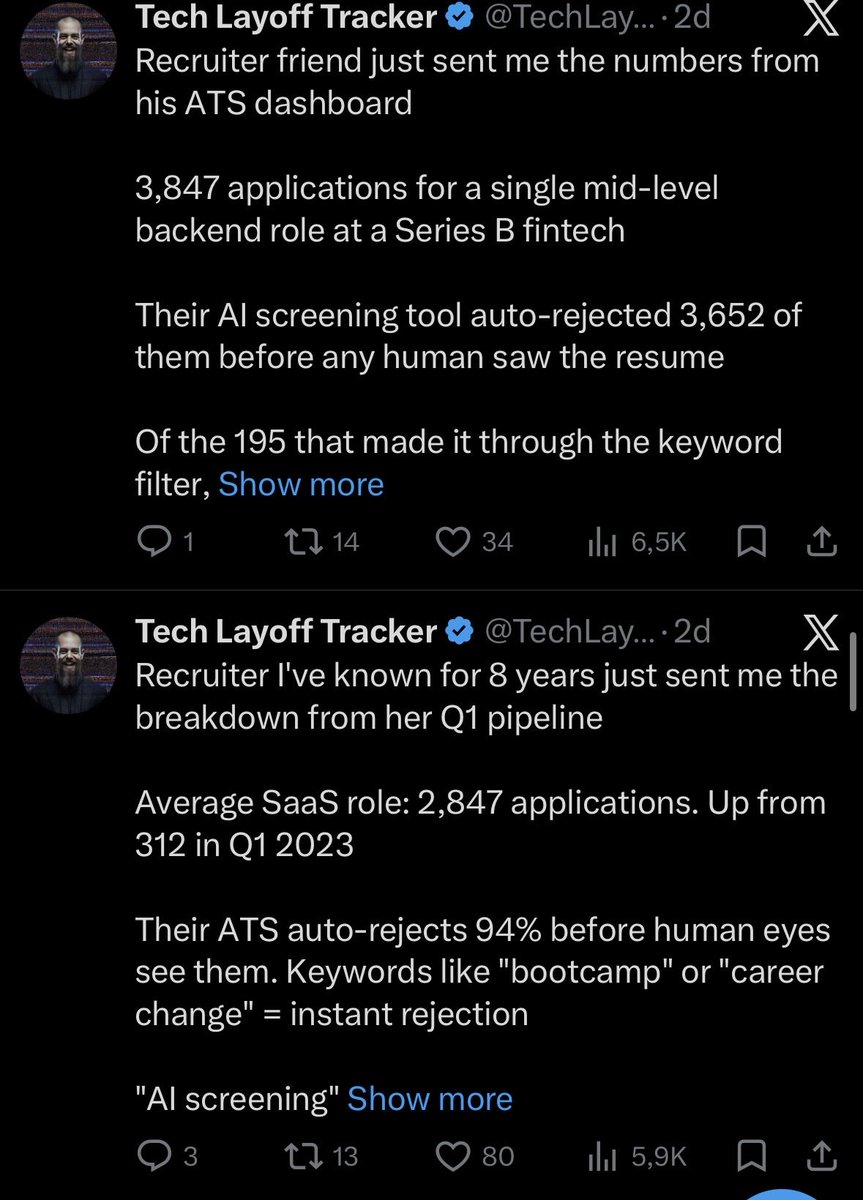
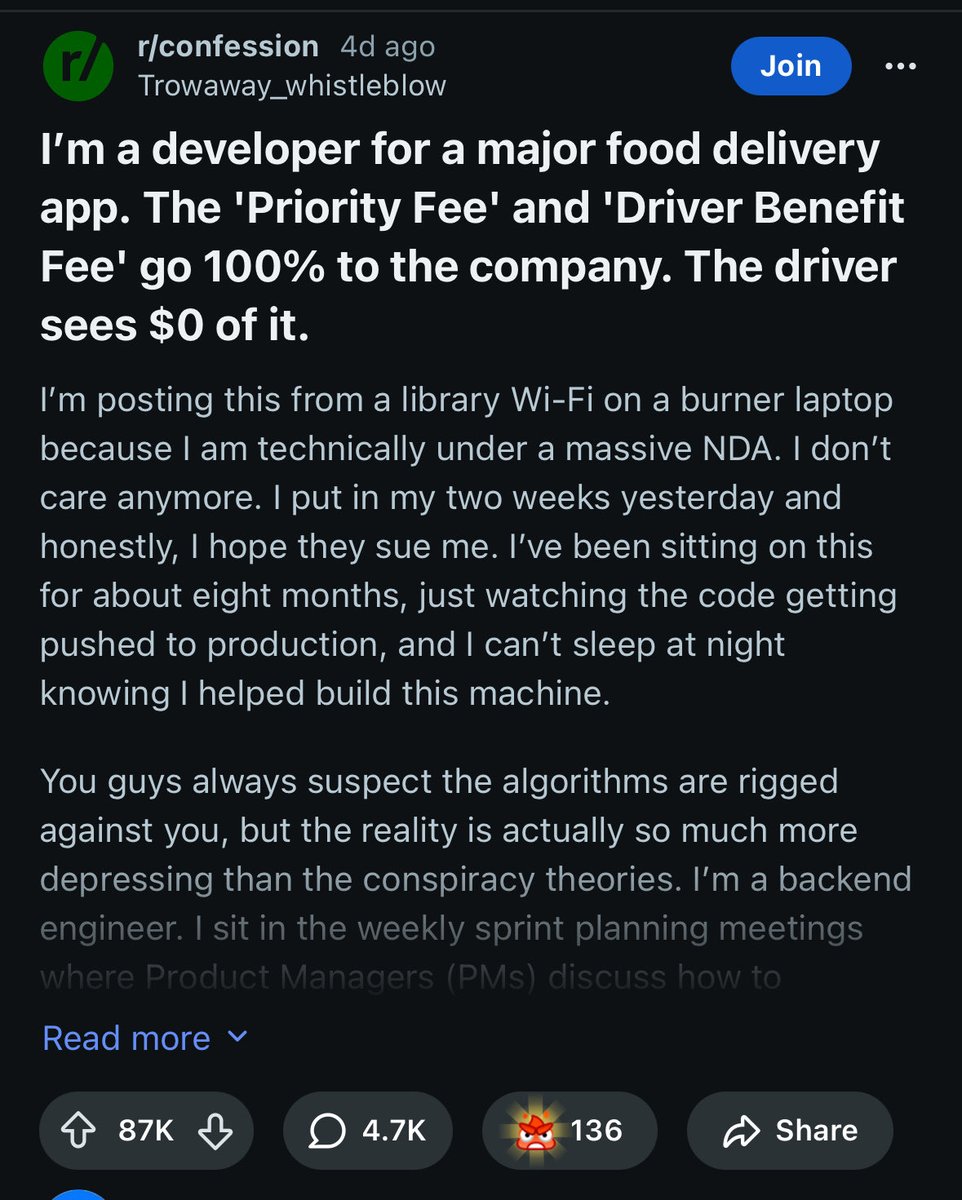
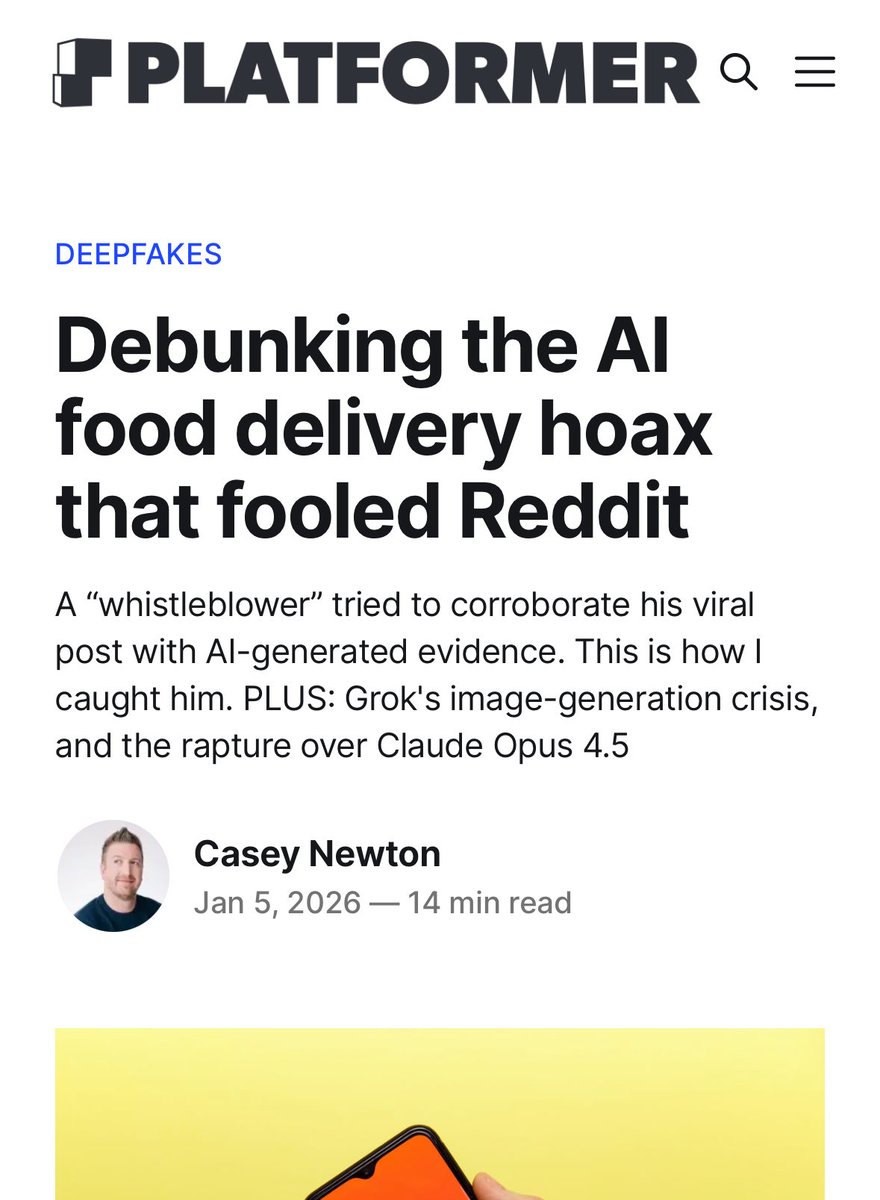
As it's been ~3 years, figured I'll answer "What caused the Uber Eats glitch that allowed ordering free food for a weekend in India?"
This was an outage on my watch. Given Quora is paywalled - can't post the answer w/o a sub - here's the story on idempotency & breaking changes:
This was an outage on my watch. Given Quora is paywalled - can't post the answer w/o a sub - here's the story on idempotency & breaking changes:
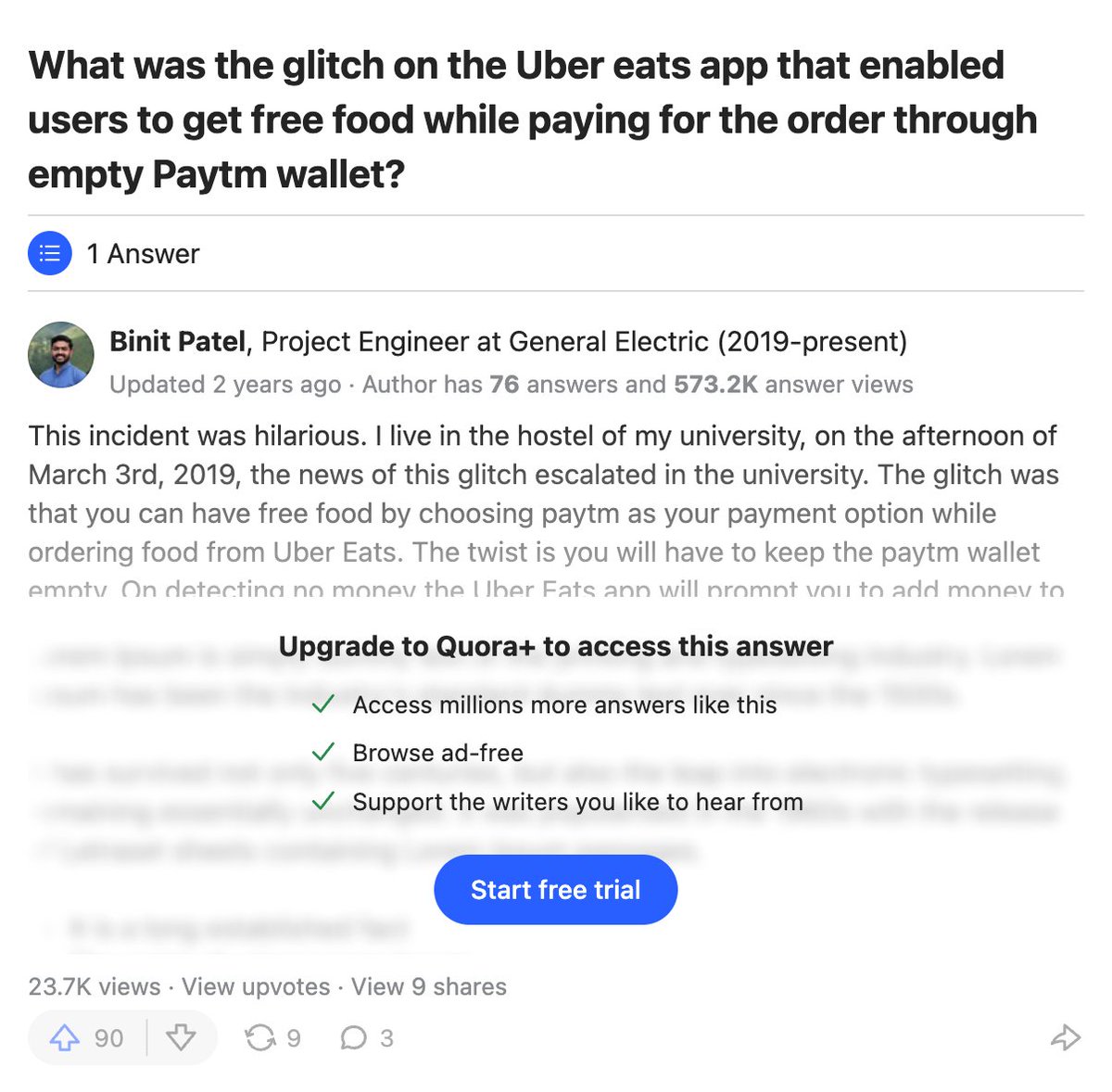
1. What happened? One morning someone in India tried to order food via UberEats in India, using Paytm as a payment method. But they didn't have enough balance.
Got an error message.
Ordered again.
The order went through!! Without having money for it.
News spread quick.
Got an error message.
Ordered again.
The order went through!! Without having money for it.
News spread quick.

2. This was a payments-related bug. The problem with these is how the bug was in the reconciliation flow. And Uber reconciled with Paytm maybe once a week.
How Uber discovered this: restaurants started going offline thanks to huge order quantities in very short times.
How Uber discovered this: restaurants started going offline thanks to huge order quantities in very short times.
3. After it was clear something was up, Uber shut down Paytm as a payment method and started the investigation.
My team owner the Paytm payment method at the time, so this was me and my team.
We naturally looked at what code changes we've made in the timeframe. None.
My team owner the Paytm payment method at the time, so this was me and my team.
We naturally looked at what code changes we've made in the timeframe. None.
4. So if we made zero changes on our end, what happened?
Turns out the Paytm team did a change late on a Friday that looked innocent enough.
It silently changed an API endpoint from behaving idempotent to non-idempotent.
Why does idempotency matter?
Turns out the Paytm team did a change late on a Friday that looked innocent enough.
It silently changed an API endpoint from behaving idempotent to non-idempotent.
Why does idempotency matter?
5. Idempotency means that you can safely repeat requests as you get the same response every time.
I remember the endpoint was charge-related.
Before, it always returned the same error when trying to charge a wallet without enough credits. With the change, not anymore:
I remember the endpoint was charge-related.
Before, it always returned the same error when trying to charge a wallet without enough credits. With the change, not anymore:
6. Before
1. "Try to charge wallet X without funds" -> Error1
2. "Try to charge wallet X without funds again" -> Error1
After
1. "Try to charge wallet X without funds" -> Error1
2. "Try to charge wallet X without funds again" -> A Brand New Error
1. "Try to charge wallet X without funds" -> Error1
2. "Try to charge wallet X without funds again" -> Error1
After
1. "Try to charge wallet X without funds" -> Error1
2. "Try to charge wallet X without funds again" -> A Brand New Error
7. Now this might look like a small change, but on Uber's side, the assumption was the endpoint was idempotent, so there was no testing on getting anything else back. The new error was unknown and not mapped to anything.
Long story short it was interpreted as "success".
Long story short it was interpreted as "success".
8. So Paytm returned an error never documented before without telling its partners. Some partners assumed idempotency changes are breaking API changes to be communicated: but they were not. Uber was one of these partners.
The result? Free food until discovered.
The result? Free food until discovered.
9. So who paid for the free food?
Restaurants got paid and customers abusing this functionality were never pursued.
The responsible party needed to foot the bill. But who was responsible?
Restaurants got paid and customers abusing this functionality were never pursued.
The responsible party needed to foot the bill. But who was responsible?
10. I can't share the settlement, so leaving a poll here to decide. Who do you think should have footed the cost for the bug?
The API provider changing their API to return a new error? The API consumer not parsing a new error introduced - but not communicated?
Who should pay?
The API provider changing their API to return a new error? The API consumer not parsing a new error introduced - but not communicated?
Who should pay?
Both parties were at fault here, which is why liability is tricky.
1. The API consumer should have coded more defensibly & not assume implicit API behaviors are deliberate.
2. The API provider should have communicated changes ahead of time, and not provide implicit idempotency.
1. The API consumer should have coded more defensibly & not assume implicit API behaviors are deliberate.
2. The API provider should have communicated changes ahead of time, and not provide implicit idempotency.
Being in the middle of this outage, a few things I learned:
- Don't assume "unknown" means "good". Assume the opposite.
- The worst outages make for the best stories later.
- College students can eat SO MUCH. They were responsible for the majority of food orders during outage!
- Don't assume "unknown" means "good". Assume the opposite.
- The worst outages make for the best stories later.
- College students can eat SO MUCH. They were responsible for the majority of food orders during outage!
Just to make things more gray, a correction. The new API behavior was not a clear-cut error if my memory correct:
1. "Try to charge wallet X without funds" -> Error1 (as before)
2. "Try to charge wallet X without funds again" -> A status that is not an error (also not success)
1. "Try to charge wallet X without funds" -> Error1 (as before)
2. "Try to charge wallet X without funds again" -> A status that is not an error (also not success)
Lots of questions on “why did Uber not handle HTTP error codes?”
Because there were none. This API at the time retuned only 200s where the body had a message to be parsed which indicated success / status message / error.
Status codes would have made this trivial to catch.
Because there were none. This API at the time retuned only 200s where the body had a message to be parsed which indicated success / status message / error.
Status codes would have made this trivial to catch.
“Did you have tests?”
Yes! As always the integration was unit tested with all possible API behaviours *at the time of building the integration*.
“Could have you not failed closed vs failing open?”
Of course we should have. It’s the morale of the story from consumer side.
Yes! As always the integration was unit tested with all possible API behaviours *at the time of building the integration*.
“Could have you not failed closed vs failing open?”
Of course we should have. It’s the morale of the story from consumer side.
Why would you *ever* fail open when there’s something unknown?
Growth! You prefer to provide a great experience even if the provider has issues. Reconcile later.
This was the case in 2015, when the integration code was written. By 2019, the mentality changed. The code: not yet.
Growth! You prefer to provide a great experience even if the provider has issues. Reconcile later.
This was the case in 2015, when the integration code was written. By 2019, the mentality changed. The code: not yet.
Lots of replies on the payments API design.
I don’t want to give Paytm a hard time: they were a lot better vs lots of other PSPs we worked with (my team owned ~15 PSP integrations). We integrated with *much* worse APIs & providers.
Paytm - unlike many - kept & keeps improving.
I don’t want to give Paytm a hard time: they were a lot better vs lots of other PSPs we worked with (my team owned ~15 PSP integrations). We integrated with *much* worse APIs & providers.
Paytm - unlike many - kept & keeps improving.
Ah, and Willem led writing the postmortem on our side (Uber). Here are takeaways we had (from memory):
One thing I *really* appreciated at Uber was how every outage was treated as a learning opportunity. It was a blameless culture and boy, did we learn.
One thing I *really* appreciated at Uber was how every outage was treated as a learning opportunity. It was a blameless culture and boy, did we learn.
https://twitter.com/wspruijt/status/1503316486798168068?s=20&t=PxgmLuwKcqTzHBlyOrxxAg
Lots of people saying Uber should have just interpreted the unknown message as “unsuccessful”. Not quite.
Here’s a story from a startup that did just that… double and triple charging their customers.
Alerting on never-before-seen responses is key over just assuming yay or nay.
Here’s a story from a startup that did just that… double and triple charging their customers.
Alerting on never-before-seen responses is key over just assuming yay or nay.

• • •
Missing some Tweet in this thread? You can try to
force a refresh