
Nearly a week since ~400 companies can not use any @Atlassian products like JIRA, Confluence. I've talked to several impacted teams and they are upset how poorly Atlassian is handling the biggest outage these teams experienced.
A thread on what Atlassian needs to fix and why:
A thread on what Atlassian needs to fix and why:

1. Outages happen, no matter how you try to avoid them. No one should be upset about this incident, nor search for who is to blame (apparently, a maintenance script)
What matters is what happens AFTER the incident is discovered.
What matters is what happens AFTER the incident is discovered.
https://twitter.com/Atlassian/status/1511870509973090304
2. Initially, Atlassian did just fine in notifying about something being wrong. They posted updates after the incident started.
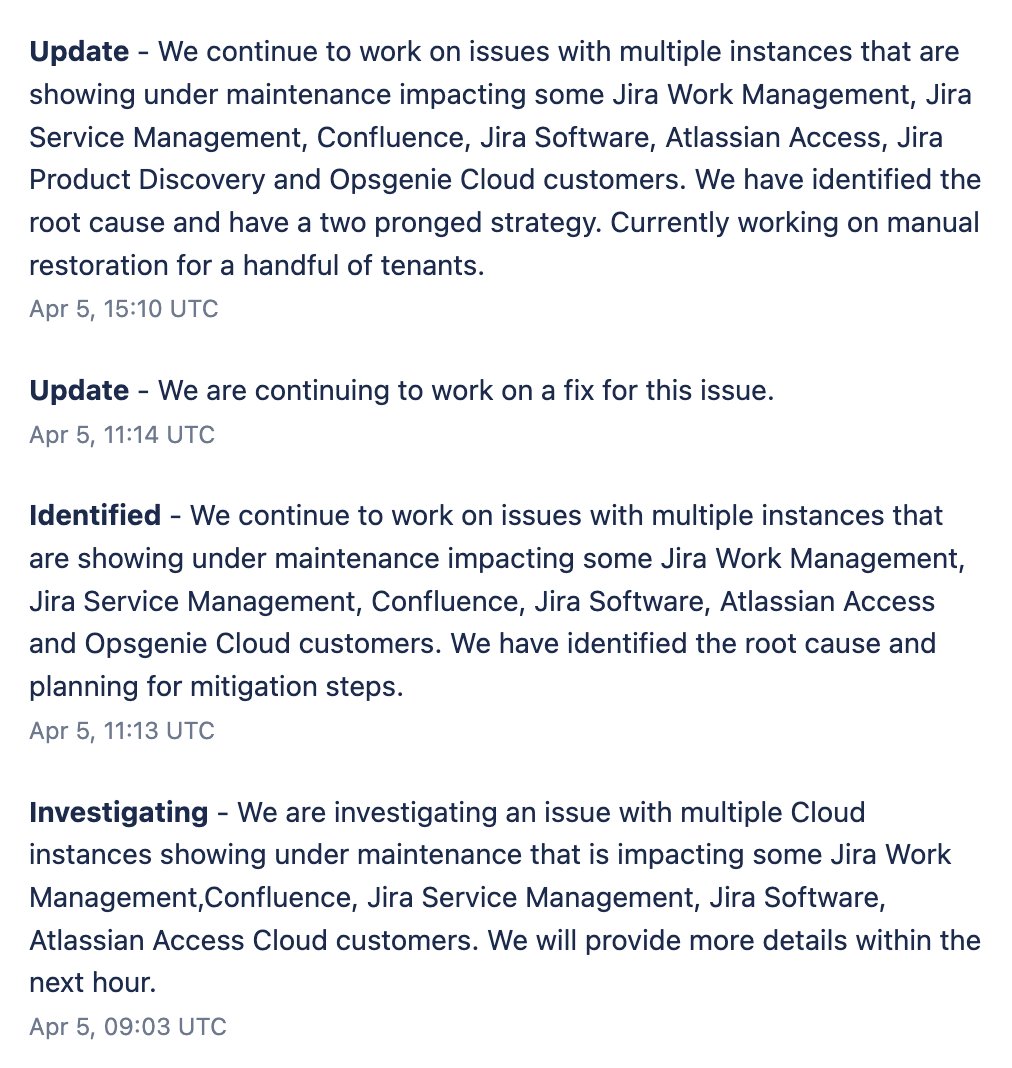
3. However, 6 hours later, the incident was still ongoing.
This was strange... because according to Atlassian's own protocol, they are able to restore data for services like JIRA in 6 hours: atlassian.com/trust/security…
This was strange... because according to Atlassian's own protocol, they are able to restore data for services like JIRA in 6 hours: atlassian.com/trust/security…

4. The cause of the outage is accidental data deletion. Happens. Should be easy for Atlassian to restore. Quote from them:
"Atlassian tests backups for restoration on a quarterly basis."
And yet, backups are not working as we speak.
atlassian.com/trust/security…
"Atlassian tests backups for restoration on a quarterly basis."
And yet, backups are not working as we speak.
atlassian.com/trust/security…
5. Ok, so Atlassian apparently has an outage where their recovery is not working. Not great, but happens.
What should you do in this case?
Tell customers what is happening.
Customers tell me there has been radio silence for 6 days for the most part. This is not ok.
What should you do in this case?
Tell customers what is happening.
Customers tell me there has been radio silence for 6 days for the most part. This is not ok.
6. Mission-critical customer infrastructure. Several customers impacted went all-in on Atlassian, including using @Opsgenie for their oncall alerting - it's like @pagerduty, but by Atlassian.
For them, OpsGenie is also down. Atlassian offers no workaround even for this.
For them, OpsGenie is also down. Atlassian offers no workaround even for this.
7. Finally, 6 days into the outage, some customers received communication.
It was an update on a ticket that told them...
"Wait more. A lot more."
That's it. No alternatives offered. Just "wait". After a week into the outage. As a paying customer.
It was an update on a ticket that told them...
"Wait more. A lot more."
That's it. No alternatives offered. Just "wait". After a week into the outage. As a paying customer.
https://twitter.com/kjartanmuller/status/1513462616030683138
8. To add salt to the wound, customers using onsite JIRA installations have no such issues (the outage is specific to Atlassian Cloud).
However, Atlassian discontinued Server products, claiming the Cloud is more reliable. These customers sure don't feel it is.
However, Atlassian discontinued Server products, claiming the Cloud is more reliable. These customers sure don't feel it is.

9. So what should have Atlassian done differently? A lot.
A) Communicate to the world about what is happening. The official Twitter account has not tweeted in 4 days (!!). In the middle of a massive Atlassian outage? This was the last tweet.
A) Communicate to the world about what is happening. The official Twitter account has not tweeted in 4 days (!!). In the middle of a massive Atlassian outage? This was the last tweet.
https://twitter.com/Atlassian/status/1511870512246374400
A) (Cont'd). No Atlassian exec has issued any statement.
When @Cloudflare has issues much smaller than this, @eastdakota communicates rapidly. Take what happened a few hours into the Okta breach, as they already had updates going out:
When @Cloudflare has issues much smaller than this, @eastdakota communicates rapidly. Take what happened a few hours into the Okta breach, as they already had updates going out:
https://twitter.com/eastdakota/status/1506158901078618118?s=20&t=-QpNP4oDTWi_Gdg5swMaoQ
B) Talk to your customers!
There are "only" ~400 companies impacted. Yet most of them are in the dark.
Give them updates!
Tell them the root cause so they don't ping me for it (yes, I've told several customers impacted the actual root cause I know from an employee).
There are "only" ~400 companies impacted. Yet most of them are in the dark.
Give them updates!
Tell them the root cause so they don't ping me for it (yes, I've told several customers impacted the actual root cause I know from an employee).
C) Offer alternatives to "wait for ~2 more weeks until you can use *any* Atlassian products"!
Some customers just want OpsGenie back. Some want certain Confluence docs. Give them options. Offer to bring back some services earlier.
Give them SOMETHING else than "wait".
Some customers just want OpsGenie back. Some want certain Confluence docs. Give them options. Offer to bring back some services earlier.
Give them SOMETHING else than "wait".
D) Start your public postmortem.
Remember when @gitlab lost customer data? I do. They livestreamed how they mitigated the outage and then posted a very detailed postmortem afterward: about.gitlab.com/blog/2017/02/1…
The result? People trusted @GitLab more.
Remember when @gitlab lost customer data? I do. They livestreamed how they mitigated the outage and then posted a very detailed postmortem afterward: about.gitlab.com/blog/2017/02/1…
The result? People trusted @GitLab more.
E) Acknowledge the incident & confirm taking responsibility. Explain why the "How Atlassian does Resilience" article does not apply, and why the restoration SLAs are broken. How will customers be compensated?
Why should future customers trust Atlassian if this is not addressed?
Why should future customers trust Atlassian if this is not addressed?
F) Call out the good work your engineering teams are doing.
People are working round the clock. Use your reach like the @Atlassian handle to share what is happening.
I hear people are working round the clock. From backchannels. Why not from @Atlassian?
People are working round the clock. Use your reach like the @Atlassian handle to share what is happening.
I hear people are working round the clock. From backchannels. Why not from @Atlassian?
G) Know what is on the line. This is not just about impacted customers. The eng community is watching how this outage is being handled. Decision-makers are taking notes. People are talking "it could have been us, do we have a plan B?"
Atlassian's reputation is on the line.
Atlassian's reputation is on the line.
But please, start with your customers. They deserve better. Talk with them. Communicate directly. Give them alternatives while they wait.
Do this without someone like me asking to do so.
#HugOps to engineers working overtime.
You can, and should do better, @Atlassian.
Do this without someone like me asking to do so.
#HugOps to engineers working overtime.
You can, and should do better, @Atlassian.
If you are impacted by the outage, you have no choice to wait weeks - unless Atlassian changes its approach.
You'll probably try out other vendors as you can't do anything else.
I can recommend @linear. They are offering help those caught in this:
You'll probably try out other vendors as you can't do anything else.
I can recommend @linear. They are offering help those caught in this:
https://twitter.com/karrisaarinen/status/1513574249121812482?s=20&t=-QpNP4oDTWi_Gdg5swMaoQ
*Finally*, 5 days after full silence and a day after I published the above tweet suggesting how to fix things, Atlassian is communicating more openly.
Thanks for the transparency as step 1, @Atlassian.
Thanks for the transparency as step 1, @Atlassian.
https://twitter.com/Atlassian/status/1513913041540333569?s=20&t=lI36vKYsQQ6bdm4S4XtckQ
Unfortunately, impacted customers are telling me @Atlassian is not doing what they are communicating publicly.
This is from a company who has been down since 5 April. Atlassian, why are you not talking with your own, paying customers? Why do you not give alternatives? Shame…
This is from a company who has been down since 5 April. Atlassian, why are you not talking with your own, paying customers? Why do you not give alternatives? Shame…

• • •
Missing some Tweet in this thread? You can try to
force a refresh


