What do the Vision Transformers learn? How do they encode anything useful for image recognition? In our latest work, we reimplement a number of works done in this area & investigate various ViT model families (DeiT, DINO, original, etc.).
Done w/ @ariG23498
1/
Done w/ @ariG23498
1/
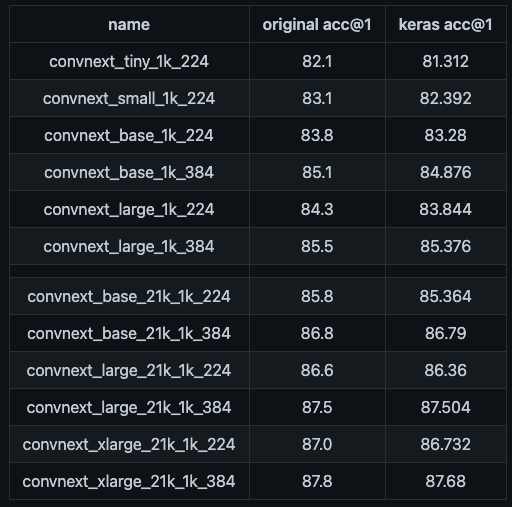
We also reimplemented different models in #Keras. These were first populated w/ pre-trained parameters & were then evaluated to ensure correctness.
Code, models, a tutorial, interactive demos (w/ @huggingface Spaces), visuals:
github.com/sayakpaul/prob…
2/
Code, models, a tutorial, interactive demos (w/ @huggingface Spaces), visuals:
github.com/sayakpaul/prob…
2/
We’ve used the following methods for our analysis:
* Attention rollout
* Classic heatmap of the attention weights
* Mean attention distance
* Viz of the positional embeddings & linear projections
We hope our work turns out to be a useful resource for those studying ViTs.
3/
* Attention rollout
* Classic heatmap of the attention weights
* Mean attention distance
* Viz of the positional embeddings & linear projections
We hope our work turns out to be a useful resource for those studying ViTs.
3/




We’ve also built a @huggingface organization around our experiments. The organization holds the Keras pre-trained models & spaces where you can try the visualization on your own images.
huggingface.co/probing-vits
Contributions are welcomed :)
4/
huggingface.co/probing-vits
Contributions are welcomed :)
4/
We thank @fchollet for his helpful guidance on the tutorial. We thank @jarvislabsai & @GoogleDevExpert for providing us with credit support that allowed the experiments.
Thanks to @ritwik_raha for helping us with this amazing visual.
5/
Thanks to @ritwik_raha for helping us with this amazing visual.
5/
• • •
Missing some Tweet in this thread? You can try to
force a refresh