
 The idea of Flux Control is simple yet elegant:
The idea of Flux Control is simple yet elegant: We're bringing you the core support for Latent Consistency Models (both T2I & I2I are supported) 🔥
We're bringing you the core support for Latent Consistency Models (both T2I & I2I are supported) 🔥
 We are releasing a total of 4 small SDXL ControlNet checkpoints today - 2 for Canny and 2 for Depth 💣
We are releasing a total of 4 small SDXL ControlNet checkpoints today - 2 for Canny and 2 for Depth 💣

 SDXL 1.0 comes with permissive licensing. Additional pipelines for SDXL 🚀
SDXL 1.0 comes with permissive licensing. Additional pipelines for SDXL 🚀
 First, we have another cool pipeline, namely UniDiffuser, capable of performing **SIX different tasks** 🤯
First, we have another cool pipeline, namely UniDiffuser, capable of performing **SIX different tasks** 🤯 Custom Diffusion only fine-tunes the cross-attention layers of the UNet and also supports blending textual inversion for seamless learning on consumer hardware.
Custom Diffusion only fine-tunes the cross-attention layers of the UNet and also supports blending textual inversion for seamless learning on consumer hardware.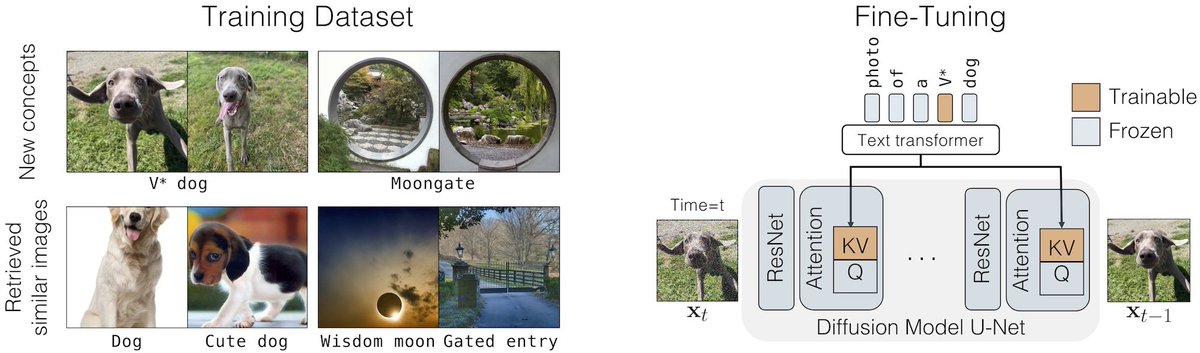


 With the default arguments of the pipeline, the result doesn't seem that coherent w.r.t edit instructions (verified across many different seeds and number of inference steps):
With the default arguments of the pipeline, the result doesn't seem that coherent w.r.t edit instructions (verified across many different seeds and number of inference steps): 
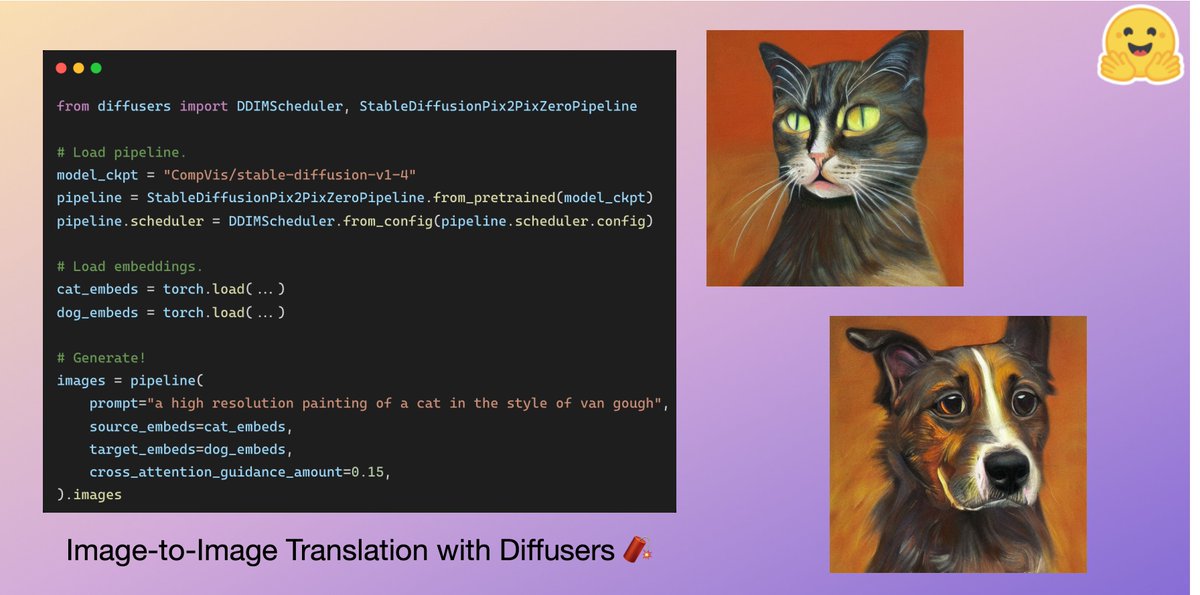 The pipeline has two options:
The pipeline has two options:
 Once you have the fine-tuned weights in Keras, you use the tool (which is just a Space) to export a `StableDiffusionPipeline` and push it to the 🤗 Hub.
Once you have the fine-tuned weights in Keras, you use the tool (which is just a Space) to export a `StableDiffusionPipeline` and push it to the 🤗 Hub.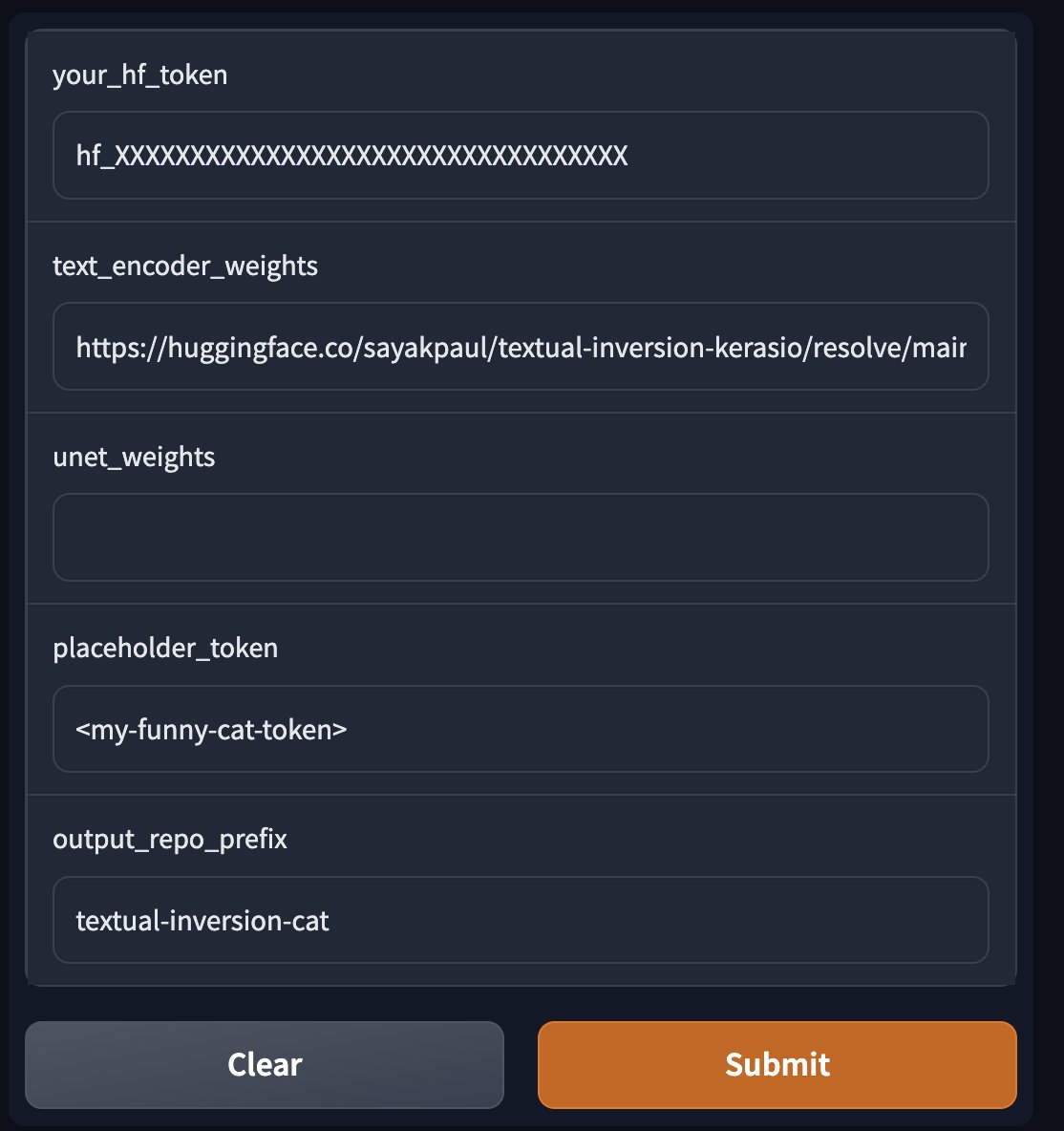

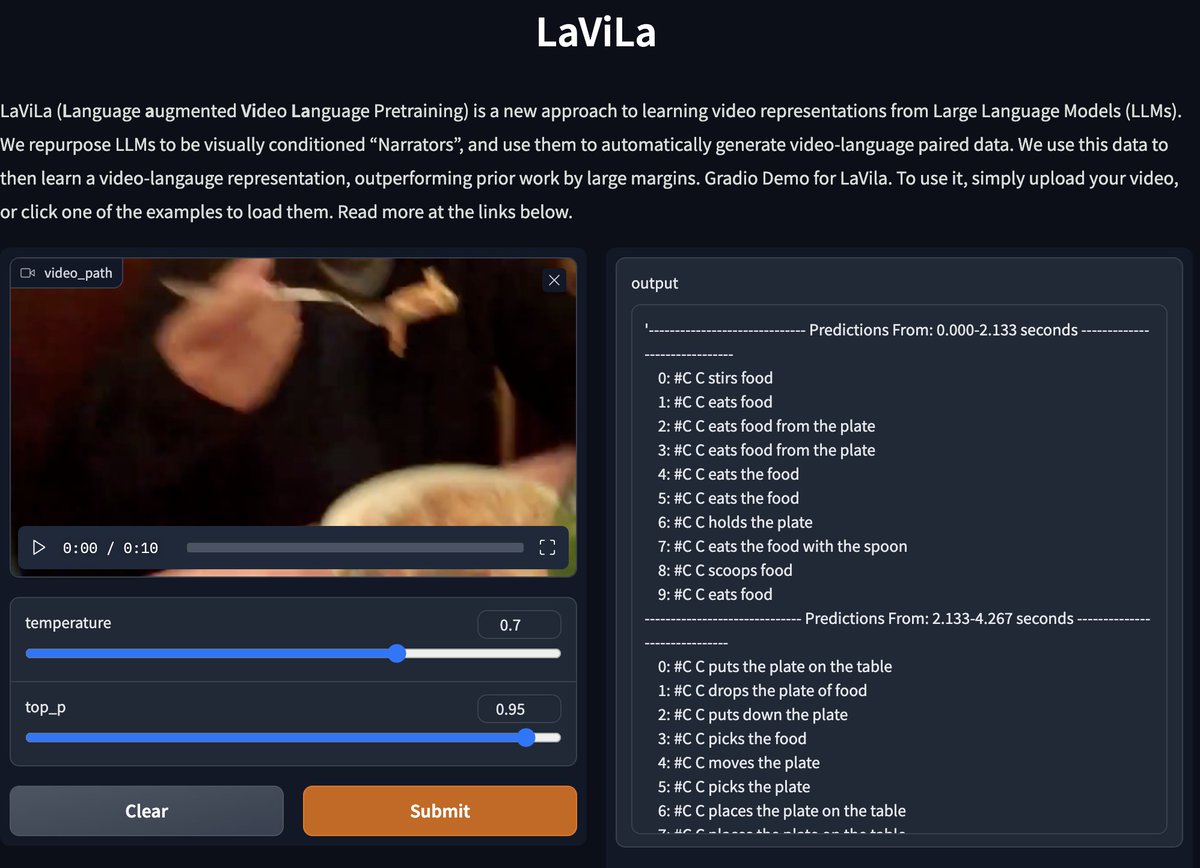 There's a LOT in the store.
There's a LOT in the store. We have a separate task page on segmentation to help you navigate across all the compatible datasets and models we have on the 🤗 Hub:
We have a separate task page on segmentation to help you navigate across all the compatible datasets and models we have on the 🤗 Hub:
 The above results are with the smallest SegFormer variant and small-scale high-res dataset. Results improve with longer training and a slightly bigger variant.
The above results are with the smallest SegFormer variant and small-scale high-res dataset. Results improve with longer training and a slightly bigger variant. We implemented everything in a TFX pipeline and delegated its execution to Vertex AI on GCP.
We implemented everything in a TFX pipeline and delegated its execution to Vertex AI on GCP.
 * Model documentation: huggingface.co/docs/transform…
* Model documentation: huggingface.co/docs/transform…
