
After extreme procrastination, I finally finished the blog post on "why we should use synthetic dataset in ML".
In other words, can we use all these amazing #dalle2 synthetic images to improve generalization.
vsehwag.github.io/blog/2022/4/sy…
In other words, can we use all these amazing #dalle2 synthetic images to improve generalization.
vsehwag.github.io/blog/2022/4/sy…

Training on synthetic+real data, tend to show an inflection point. As the quality of synthetic data improves, it will go from "degrading performance" -> "no benefit at all" -> "finally benefit in generalization". Diffusion models cross the inflection point on most datasets.
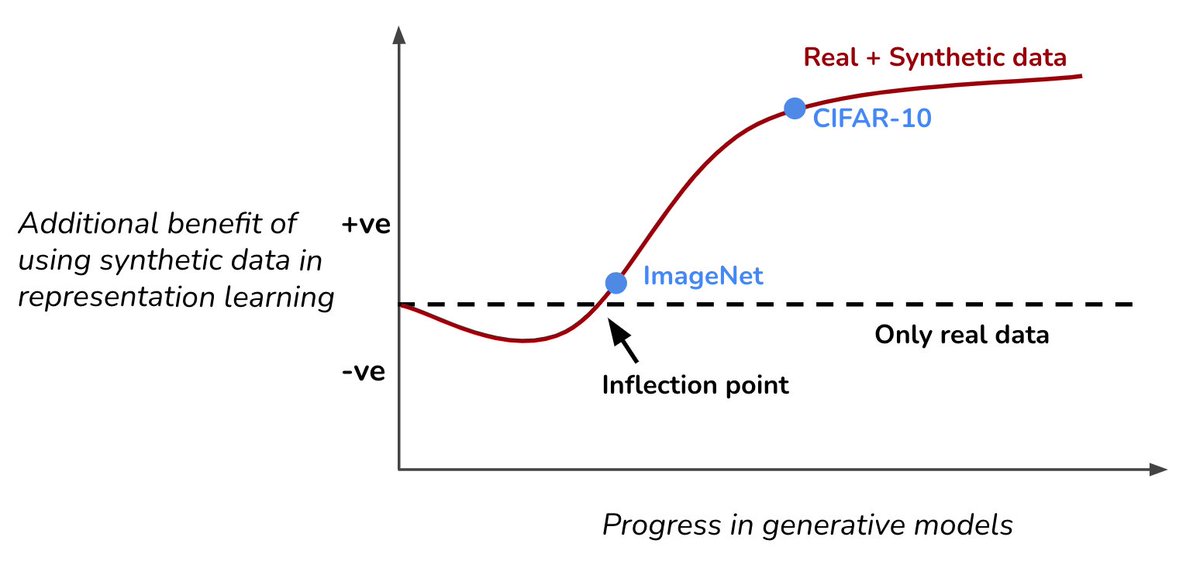
The benefit of synthetic data is even higher in adversarial/robust training, since it is known to be more data hungry.
On cifar10, using synthetic data leads to tremendous boost in robust accuracy. More details are in our upcoming paper at #ICLR2022
rb.gy/dlve4y
On cifar10, using synthetic data leads to tremendous boost in robust accuracy. More details are in our upcoming paper at #ICLR2022
rb.gy/dlve4y

We have barely scratched the surface of this research direction. Multiple questions 1) how to distill knowledge from diffusion models 2) adaptive sampling 3) sub-group level metrics have yet to be explored further. Check out the discussion section for further thoughts on each.
• • •
Missing some Tweet in this thread? You can try to
force a refresh


