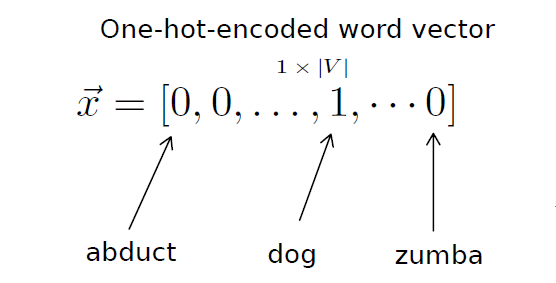
Have you heard about argument-based recommender systems?
Do you like to receive explained and argued recommendations?
🚨SPOILER ALERT🚨: my research is about it.
@RedDivulga @CrueUniversidad @UAM_Madrid @UCCUAM @EDoctorado_UAM
I open #HiloTesis 👇
Do you like to receive explained and argued recommendations?
🚨SPOILER ALERT🚨: my research is about it.
@RedDivulga @CrueUniversidad @UAM_Madrid @UCCUAM @EDoctorado_UAM
I open #HiloTesis 👇

In my doctoral dissertation I research on argument-based recommender systems, specifically, on the generation and explanation of personalized and interactive recommendations from arguments extracted from textual content in Spanish.
2/20
2/20
The main hypothesis is:
"The exploitation of argumentative information can lead to significant novelties and improvements in the user’s experience with recommender systems."
Sounds weird? Below I give you some context and detail my work in progress. Let's get to it!
3/20
"The exploitation of argumentative information can lead to significant novelties and improvements in the user’s experience with recommender systems."
Sounds weird? Below I give you some context and detail my work in progress. Let's get to it!
3/20
Today, everyone is exposed to vast amounts of information online. In this context, we are faced with a multitude of everyday situations in which to make decisions:
▪️ Which TV to buy?
▪️ Which new songs to listen to?
▪️ Which book to give as a gift?
4/20
▪️ Which TV to buy?
▪️ Which new songs to listen to?
▪️ Which book to give as a gift?
4/20

In these situations, the tasks of searching and filtering content become tedious and complicated.
That's when recommender systems come to the rescue.
But what is a recommender system? 🤔
5/20
That's when recommender systems come to the rescue.
But what is a recommender system? 🤔
5/20
Recommender systems (RS) are Artificial Intelligence-based computer agents that can help us in such tasks, filtering and suggesting those items (products, movies, books, etc.) that may be of interest to us, based on large collections of data.
6/20
6/20
In our day-to-day lives, we are exposed to RS in countless applications, such as Amazon, Spotify, Netflix, Booking, YouTube, etc.
Depending on the case, some recommendations we receive are based on the popularity of the items, but others have to do with our preferences.
7/20
Depending on the case, some recommendations we receive are based on the popularity of the items, but others have to do with our preferences.
7/20

In general, we express our preferences (tastes and interests) about items in an "explicit" manner:
▪️ Ratings / number of stars ⭐️
▪️ Thumbs up / down 👍👎
▪️ Buy button 🛒
8/20
▪️ Ratings / number of stars ⭐️
▪️ Thumbs up / down 👍👎
▪️ Buy button 🛒
8/20
And other times we do it in an "implicit" way:
▪️ Searches we perform on a web portal.
▪️ Time we spend reading a product description.
▪️ Number of times we listen to a song.
▪️ Types of series we watch.
9/20
▪️ Searches we perform on a web portal.
▪️ Time we spend reading a product description.
▪️ Number of times we listen to a song.
▪️ Types of series we watch.
9/20
The above information sources are the ones typically used by traditional RS:
▪️ Attending to our preferences (content-based RS).
▪️ Attending to the preferences of people related to us (collaborative filtering-based RS).
10/20
▪️ Attending to our preferences (content-based RS).
▪️ Attending to the preferences of people related to us (collaborative filtering-based RS).
10/20

However, there are other potentially useful sources of preferences for recommender systems, which are formed by user-generated textual content:
▪️ Product reviews.
▪️ Opinion blogs.
▪️ Posts on social networks.
▪️ Citizen proposals.
11/20
▪️ Product reviews.
▪️ Opinion blogs.
▪️ Posts on social networks.
▪️ Citizen proposals.
11/20

In fact, the scientific community has invested time and effort in researching methods of automatic extraction of user preferences in texts, especially trying to identify positive or negative feedback on aspects or characteristics of the items.
12/20
12/20

However, there are few studies that go further, trying to find not only what we think about something, but also the cause or reason for our opinions, with the aim that the recommendations are based not only on what is said, but also on why it is said.
13/20
13/20

The latter is a great CHALLENGE, which consists in the automatic extraction of argumentative information from textual content.
This task has already been explored and conceptualized in the field of Argument Mining (AM), a subfield of Natural Language Processing (NLP).
14/20
This task has already been explored and conceptualized in the field of Argument Mining (AM), a subfield of Natural Language Processing (NLP).
14/20

Therefore, in this thesis, we propose a novel approach called "argument-based recommender systems", which address various tasks related to automatic extraction and exploitation of arguments for recommendation and explanation purposes.
15/20
15/20
Thus:
1⃣ We investigate new recommendation methods that make use of argumentative information before, during and after item filtering.
Which leads us to one of our first contributions: classification of RS according to the use of arguments.
16/20
1⃣ We investigate new recommendation methods that make use of argumentative information before, during and after item filtering.
Which leads us to one of our first contributions: classification of RS according to the use of arguments.
16/20

2⃣ We investigate new argument mining methods and approaches for the identification of claims and premises, and relationships between them, with the goal of automatically extracting computable arguments, which can be used by a recommender system.
17/20
17/20
3⃣ We investigated the explanation of the recommendations given based on the arguments used by the RS, in order to increase the satisfaction, trust, persuasion and loyalty of the users with respect to the system.
18/20
18/20

And last but not least,
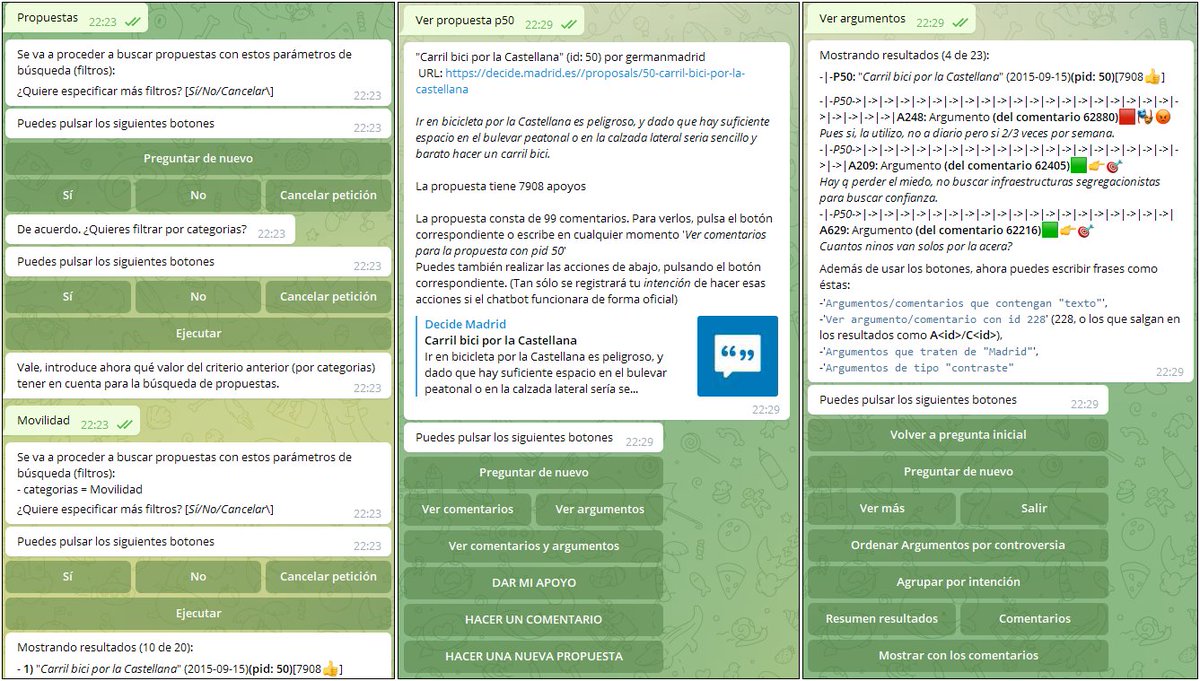
4⃣ We investigate the interaction of users with the recommender system (by means of a chatbot) to adjust and give feedback on the recommendations given.
The interaction in the chatbot is done by means of natural language.
19/20
4⃣ We investigate the interaction of users with the recommender system (by means of a chatbot) to adjust and give feedback on the recommendations given.
The interaction in the chatbot is done by means of natural language.
19/20
I hope you liked the #HiloTesis and that I was able to convey what my research is about 😃
If you are interested in learning more about it, you can visit our website: github.com/argrecsys
Finally, any questions or comments are welcome.
Thank you 👋
20/20
If you are interested in learning more about it, you can visit our website: github.com/argrecsys
Finally, any questions or comments are welcome.
Thank you 👋
20/20
• • •
Missing some Tweet in this thread? You can try to
force a refresh