
CS PhD student in the IRG at @UAM_Madrid | XAI, ML, RecSys, NLP, Argument Mining & Information Retrieval | Tweets in En & Es
 1⃣ Neural Re-ranking for Multi-stage Recommender Systems.
1⃣ Neural Re-ranking for Multi-stage Recommender Systems.
 In this case, I am using the Stable Diffusion v1-4 model.
In this case, I am using the Stable Diffusion v1-4 model. En mi tesis doctoral investigo sobre sistemas de recomendación basados en argumentos, específicamente, sobre la generación y explicación de recomendaciones personalizadas e interactivas a partir de argumentos extraídos de contenido textual en español.
En mi tesis doctoral investigo sobre sistemas de recomendación basados en argumentos, específicamente, sobre la generación y explicación de recomendaciones personalizadas e interactivas a partir de argumentos extraídos de contenido textual en español. In my doctoral dissertation I research on argument-based recommender systems, specifically, on the generation and explanation of personalized and interactive recommendations from arguments extracted from textual content in Spanish.
In my doctoral dissertation I research on argument-based recommender systems, specifically, on the generation and explanation of personalized and interactive recommendations from arguments extracted from textual content in Spanish. I recommend you to check it out and play with it.
I recommend you to check it out and play with it.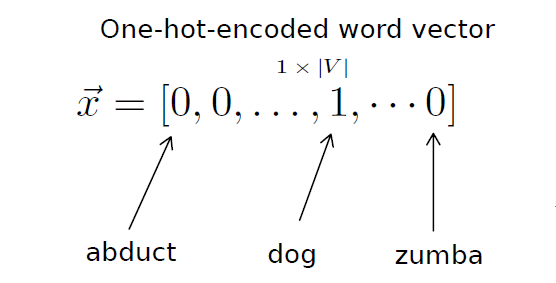
 To begin with, don't you find it strange that this technique is called Confusion Matrix and not Accuracy Matrix?
To begin with, don't you find it strange that this technique is called Confusion Matrix and not Accuracy Matrix? There are 2 very effective techniques to transform all the attributes of a dataset to the same scale, which are:
There are 2 very effective techniques to transform all the attributes of a dataset to the same scale, which are:

 K-Means:
K-Means: Some of the traditional clustering approaches are:
Some of the traditional clustering approaches are: