
Tired of beam search and all the heuristics needed to make it work well in MT?
In our work accepted at #NAACL2022 (co-lead @tozefarinhas) we explore an alternative decoding method that leverages neural metrics to produce better translations!
arxiv.org/abs/2205.00978
1/14
In our work accepted at #NAACL2022 (co-lead @tozefarinhas) we explore an alternative decoding method that leverages neural metrics to produce better translations!
arxiv.org/abs/2205.00978
1/14

The most common method to obtain translations from a trained MT model is to approximately compute the *maximum-a-posteriori* (MAP) translation with algorithms like beam search
However many works have questioned the utility of likelihood as a proxy for translation quality.
2/14
However many works have questioned the utility of likelihood as a proxy for translation quality.
2/14

In parallel, significant progress has been made recently in improving methods for Quality Estimation (QE) and evaluation of translated sentences by using pretrained LMs, with metrics such BLEURT or COMET(-QE) achieving high correlations with human judgments of quality.
3/14
3/14
In this work, we leverage these advances and propose *quality-aware decoding*. The gist is to first extract candidate translations stochastically or deterministically from your model and *rank* them according to one or more QE and/or reference-based neural metrics.
4/14
4/14

We explore using beam search, vanilla and nucleus sampling for generating candidates and two core ranking methods: N-best list reranking for QE metrics and Minimum Bayes Risk (MBR) decoding for reference-based metrics. We explore variations of them and even combine both!
5/14
5/14


Crucial for this method to work is the use of good metrics for the ranking. We explore various QE (eg. COMET-QE and TransQuest) and reference-based metrics (eg. COMET and BLEURT), many of them top submissions to their respective WMT shared tasks!
6/14
6/14
We experimented with quality-aware decoding across two model sizes and four datasets, comparing to beam search (BS) baselines in multiple metrics. We explore the impact of the candidate generation method, the number of candidates and the ranking method/metrics used.
7/14
7/14
We found quality-aware decoding scales well with number of candidates, especially when these were generated with stochastic methods.
Using ancestral sampling underperforms the BS baseline, but we can mitigate this with biased sampling techniques such as nucleus sampling!
8/14
Using ancestral sampling underperforms the BS baseline, but we can mitigate this with biased sampling techniques such as nucleus sampling!
8/14

We also found that quality-aware decoding with neural-based metrics improves the quality of translations according to the same & other neural-based metrics!
9/14
9/14

However, this comes at cost in lexical metrics. To investigate if we aren't *overfitting* the neural metrics (reducing correlation with humans) we perform a human evaluation.
While there is an overfit, quality-aware decoding still outperforms BS in human quality!
10/14
While there is an overfit, quality-aware decoding still outperforms BS in human quality!
10/14
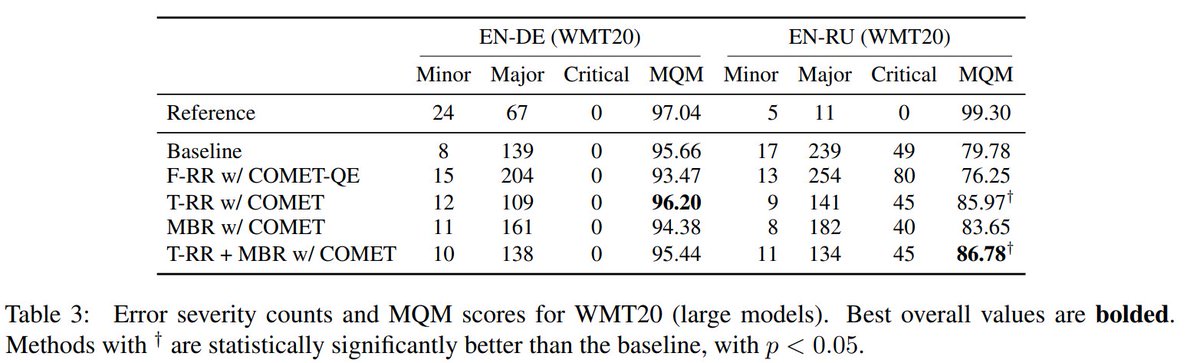

Our work is very similar to the concurrent work by @markuseful et al. (arxiv.org/abs/2111.09388) although we explore extensively the impact of metric and ranking procedures while they focus more on MBR with BLEURT, diving deeper into how translations differ from beam search
11/14
11/14
The overfitting problem identified was also something that was explored more in-depth concurrently by @chantalamrhein (arxiv.org/abs/2202.05148) using MBR with COMET.
12/14
12/14
All our code is available at github.com/deep-spin/qawa…
We made a simple python package that should allow you to run quality-aware decoding (both reranking and MBR) in a few lines!
13/14
We made a simple python package that should allow you to run quality-aware decoding (both reranking and MBR) in a few lines!
13/14

I would like to thank this super team (@tozefarinhas @RicardoRei7 @accezz @a_ogayo @gneubig @andre_t_martins) for all their help!
This was work done within the scope of @CMUPortugal's MAIA project.
14/14
This was work done within the scope of @CMUPortugal's MAIA project.
14/14
• • •
Missing some Tweet in this thread? You can try to
force a refresh



