
Czego możemy dowiedzieć się o polskich domenach z listy HSTS Preload? Wątek 🧵👇
1/19
1/19

Co to jest HSTS? To mechanizm, za pomocą którego strona WWW może powiedzieć przeglądarce internetowej: "komunikuj się ze mną wyłącznie za pomocą szyfrowanego protokołu HTTPS". Podnosi to bezpieczeństwo korzystania z sieci. Więcej w Wikipedii: pl.wikipedia.org/wiki/HTTP_Stri…
2/19
2/19
Ryzyko jest istotnie zredukowane, ale nie znika. Przy pierwszym połączeniu ze stroną przeglądarka nie wie jeszcze, że HTTPS jest obowiązkowy. Pierwsze wejście na stronę z użyciem HTTP nadal naraża użytkownika na ryzyko podsłuchu i modyfikacji przesyłanych danych.
3/19
3/19

Aby zapobiec takiej sytuacji, domeny internetowe można dodać do spisu HSTS Preload. Jest to lista domen, z którymi przeglądarki *zawsze* będą łączyć się za pomocą bezpiecznego protokołu HTTPS, nawet przy pierwszym połączeniu. Stary protokół HTTP będzie wykluczony.
4/19
4/19
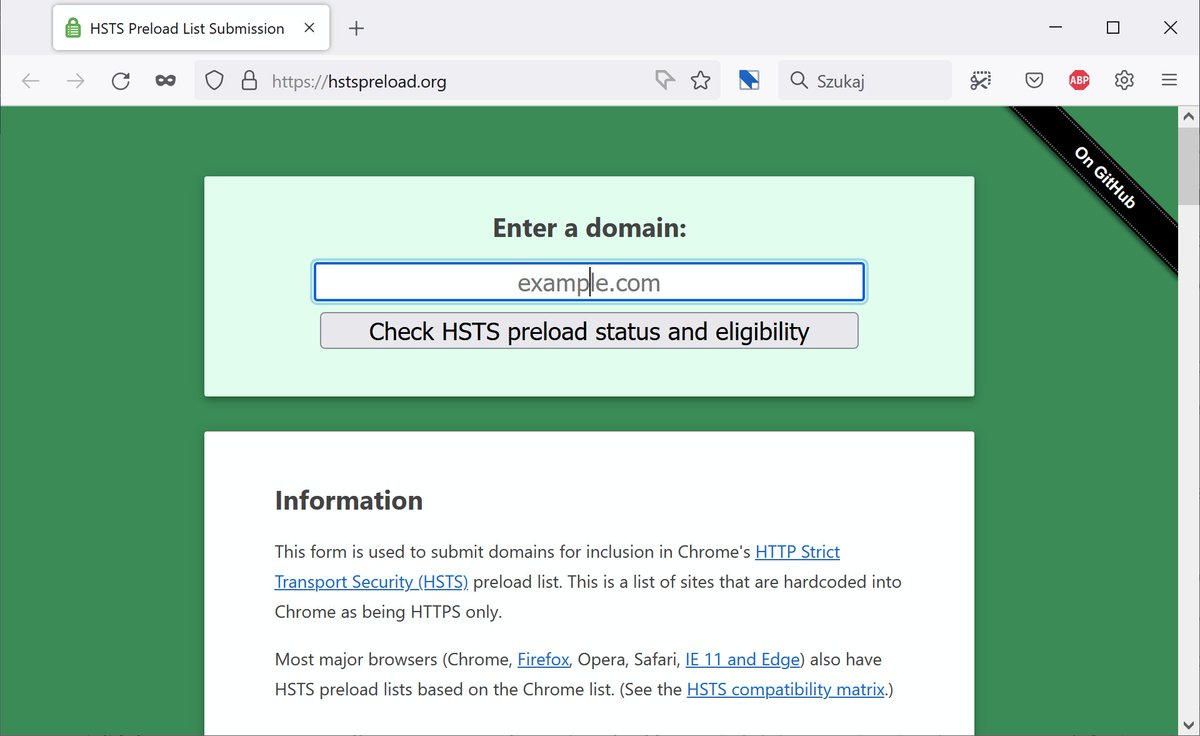
Aktualną listę domen dopisanych do HSTS Preload możesz obejrzeć tutaj: source.chromium.org/chromium/chrom…
5/19
5/19
Jeśli chcesz sprawdzić, czy jakaś domena jest na liście HSTS Preload w twoim Chrome, otwórz adres chrome://net-internals/#hsts i wpisz nazwę w sekcji "Query HSTS/PKP domain"
6/19
6/19


Na liście znajduje się 166285 nazw domenowych, z czego 1235 w obrębie polskiej domeny najwyższego poziomu ".PL". To właśnie tym domenom poświęcona jest niniejsza analiza.
8/19
8/19

Czego dowiadujemy się o długości nazw domenowych?
Niektóre nazwy są bardzo krótkie, na przykład:
9h[.]pl
wk[.]pl
er[.]pl
py[.]pl
dm[.]pl
(wszystkie po 5 znaków)
9/19
Niektóre nazwy są bardzo krótkie, na przykład:
9h[.]pl
wk[.]pl
er[.]pl
py[.]pl
dm[.]pl
(wszystkie po 5 znaków)
9/19

Niektóre nazwy są bardzo długie, na przykład:
interpretacjawynikowbadan.info.pl (rekordowe 33 znaki)
10/19
interpretacjawynikowbadan.info.pl (rekordowe 33 znaki)
10/19

Rozkład długości nazw domenowych w analizowanym zbiorze wygląda następująco:
11/19
11/19

Pokażmy jeszcze raz rozkład długości nazw domenowych, ale z logarytmiczną skalą Y - to potwierdza powagę i fachowość niniejszej analizy.
12/19
12/19

Spośród polskich domen dokładnie 1094 zawiera jedną kropkę, zaś 141 zawiera dwie kropki (przykłady - patrz powyżej). Trzy kropki są wykluczone, dowolna większa wartość również.
13/19
13/19

1077 domen nie zawiera żadnej kreski. 142 domeny zawierają jedną kreskę, 14 domen zawiera dwie kreski, zaś dwie domeny zawierają trzy kreski. Są to:
auto-motor-i-sport.pl
odzyskiwanie-danych-z-dysku.pl
14/19
auto-motor-i-sport.pl
odzyskiwanie-danych-z-dysku.pl
14/19

Najpopularniejsze literki w polskich nazwach domenowych to oczywiście "p" oraz "l". Jeśli jednak zignorujemy część ".pl", będą to "a", "e" oraz "o" - każda ma ponad 1000 wystąpień.
15/19
15/19

Najmniej popularne literki to "q", "ł", "ś", "ą" - wszystkie poniżej dziesięciu wystąpień. Trzeba jednak pamiętać, że nie było ani jednego wystąpienia liter "ę", "ż", "ź", "ć" oraz "ń".
16/19
16/19

Tylko pięć spośród polskich domen z listy HSTS używa IDN czyli formatu międzynarodowych nazw domenowych. Więcej informacji
pl.wikipedia.org/wiki/Internati…
Są to:
spełnijmazania.pl
śląskieradio.pl
ścisłowcy.pl
matuła.pl
łukasik.pl
17/19
pl.wikipedia.org/wiki/Internati…
Są to:
spełnijmazania.pl
śląskieradio.pl
ścisłowcy.pl
matuła.pl
łukasik.pl
17/19

Spośród cyferek miejsca medalowe zajmują dwójka, czwórka i jedynka.
18/19
18/19

To już wszystko, czego mogliście dowiedzieć się o polskich nazwach domenowych z listy HSTS Preload. Dziękuję za udział w moim TED Talk!
19/19
19/19
• • •
Missing some Tweet in this thread? You can try to
force a refresh





