
With the release of #Imagen from @GoogleAI yesterday, here's a quick follow-up thread on the progress of compositionality in vision-language models.🧵 1/11 

A few weeks ago DALL-E 2 was unveiled. It exhibits both very impressive success cases and clear failure cases – especially when it comes to counting, relative position, and some forms of variable binding. Why?
https://twitter.com/raphaelmilliere/status/15146197213411450912/11
Under the hood, DALL-E 2 uses a frozen CLIP model to encode captions into embeddings. CLIP's contrastive training objective leads it to learn only the features of images people tend to describe online (e.g., common objects/relations and aesthetic style) 3/11
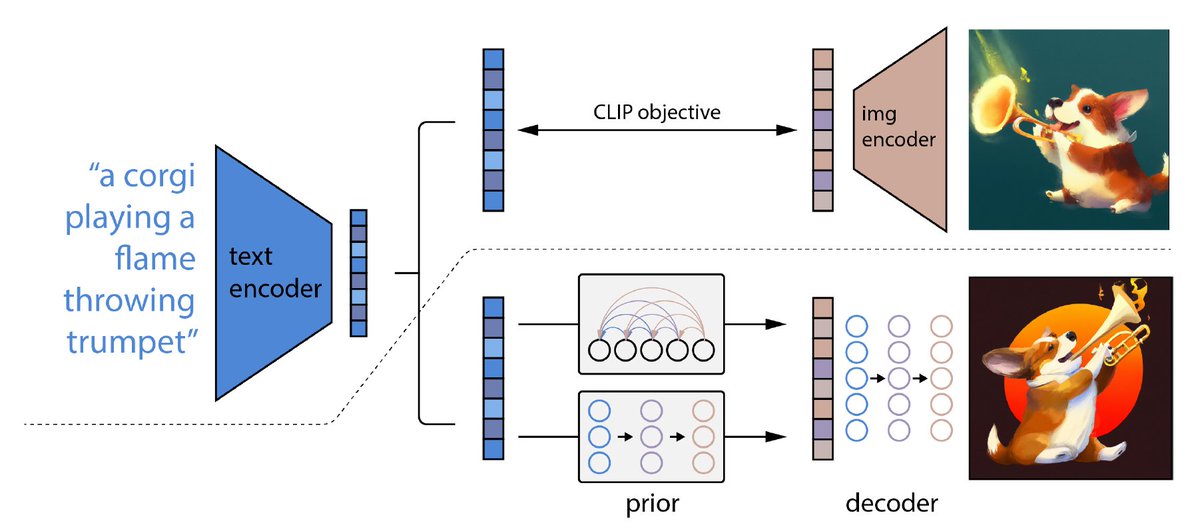
CLIP only needs to learn visual features sufficient to match an image with the correct caption. As a result, it's unlikely to preserve the kind of information that proves useful for things such as counting, relative spatial position, and variable binding. 4/11
When DALL-E 2 generates an image, it starts with the high-level features encoded in CLIP, the fills in the details with a diffusion model. This does not enable it to add the compositional features missing from the initial text encoding. 5/11

#Imagen is a different beast. The architecture is very simple: the caption is encoded in a frozen language model (T5-xxl) both much larger & trained on much more text than CLIP. A series of conditional diffusion models generate and upscale an image from the T5 text embedding. 6/

The Imagen paper showcases the importance of the text encoding model for image generation, which benefits from scaling. Imagen seems better than DALL-E 2 at visualizing text, counting, parsing relative position, and some forms of variable binding. 7/11



These are all non-cherry picked samples from the paper. While not perfect, they suggest that Imagen is better at parsing the compositional semantics of captions, even when it contains multiple objects and features. 8/11



There are still important limitations. The annotated plot below shows that humans judge Imagen to be slightly worse than DALL-E 2 when it comes to the complex compositional prompts proposed by @GaryMarcus et al. in the spirit of adversarial evaluation. 9/11

Unfortunately, the whole battery of tests (called DrawBench) only contains 200 prompts that are not systematically produced. I hope @GoogleAI will let researchers conduct more systematic evaluations in the future. Perhaps we need a BIG-Bench for vision-language models! 10/11
For further discussion on this topic, join the upcoming workshop on compositionality and AI I'm organizing with @GaryMarcus in June – free registration here: compositionalintelligence.github.io 11/11

• • •
Missing some Tweet in this thread? You can try to
force a refresh









