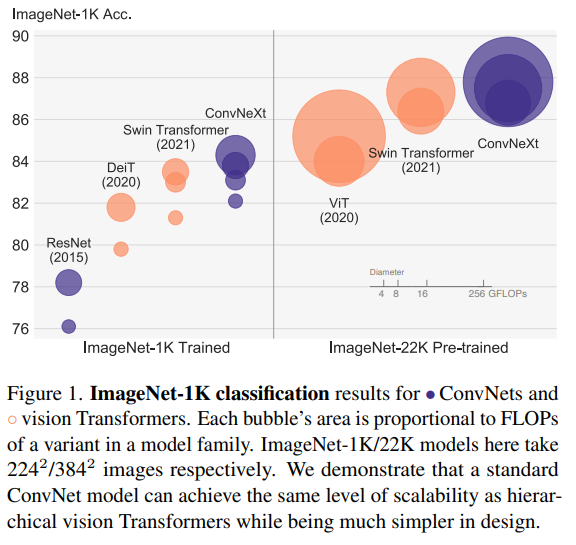
My position/vision/proposal paper is finally available:
"A Path Towards Autonomous Machine Intelligence"
It is available on OpenReview.net (not arXiv for now) so that people can post reviews, comments, and critiques:
openreview.net/forum?id=BZ5a1…
1/N
"A Path Towards Autonomous Machine Intelligence"
It is available on OpenReview.net (not arXiv for now) so that people can post reviews, comments, and critiques:
openreview.net/forum?id=BZ5a1…
1/N

The paper distills much of my thinking of the last 5 or 10 years about promising directions in AI.
It is basically what I'm planning to work on, and what I'm hoping to inspire others to work on, over the next decade.
2/N
It is basically what I'm planning to work on, and what I'm hoping to inspire others to work on, over the next decade.
2/N
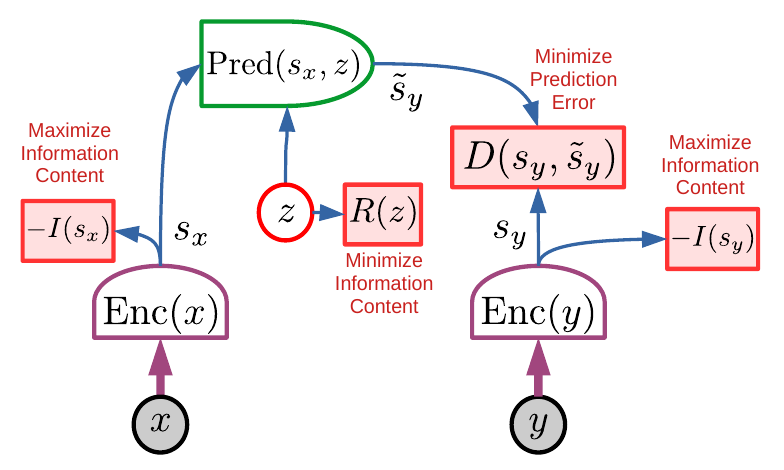
Most people don't talk publicly about their research plans.
But I'm going beyond the spirit of Open Research by publishing ideas *before* the corresponding research is completed.
3/N
But I'm going beyond the spirit of Open Research by publishing ideas *before* the corresponding research is completed.
3/N

Topics addressed:
- An integrated, DL-based, modular, cognitive architecture.
- Using a world model and intrinsic cost for planning.
- Joint-Embedding Predictive Architecture (JEPA) as an architecture for world models that can handle uncertainty.
4/N
- An integrated, DL-based, modular, cognitive architecture.
- Using a world model and intrinsic cost for planning.
- Joint-Embedding Predictive Architecture (JEPA) as an architecture for world models that can handle uncertainty.
4/N
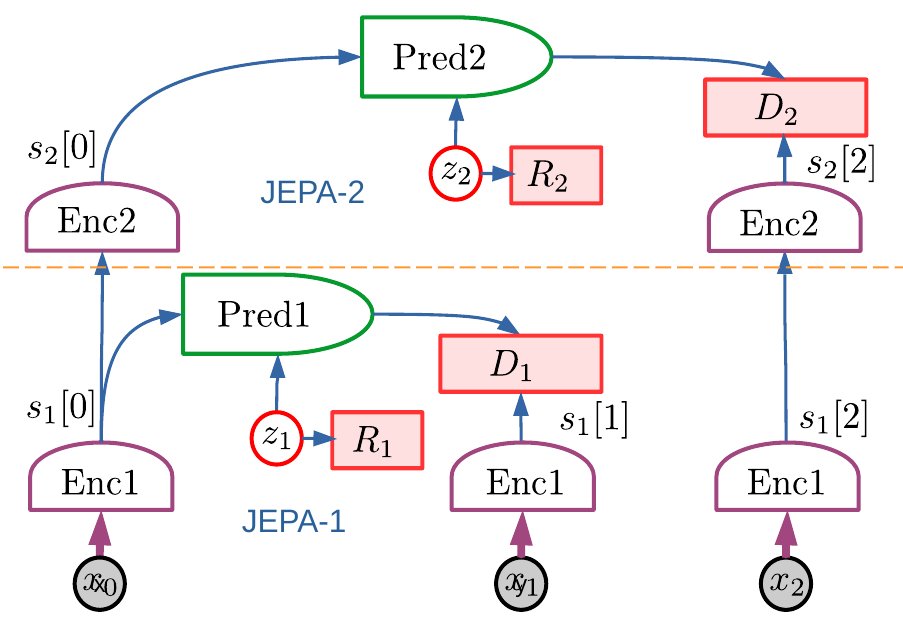
- Training JEPAs using non-contrastive Self-Supervised Learning.
- Hierarchical JEPA for prediction at multiple time scales.
- H-JEPAs can be used for hierarchical planning in which higher levels set objectives for lower levels.
- Hierarchical JEPA for prediction at multiple time scales.
- H-JEPAs can be used for hierarchical planning in which higher levels set objectives for lower levels.
- A configurable world model that can be tailored to the task at hand.
6/N
6/N
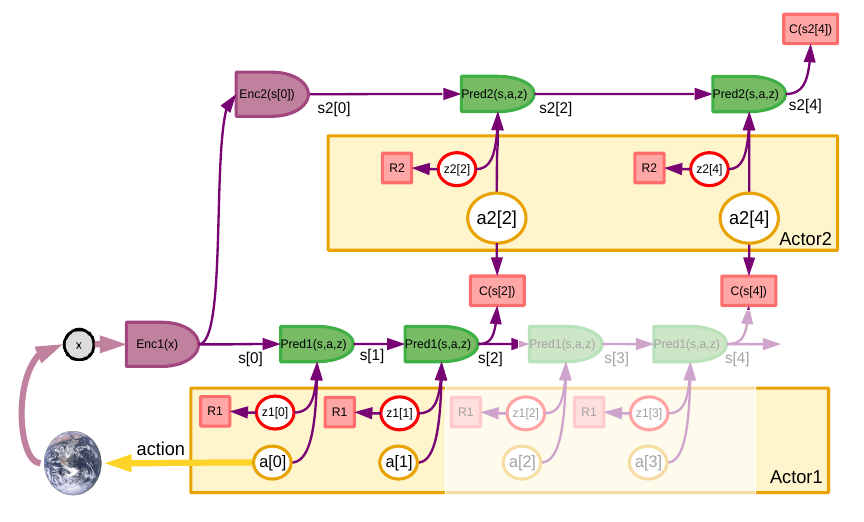
I express some of my opinions on the best path forward towards AI:
- scaling is necessary but not sufficient
- reward is not enough. Learning world models by observation-based SSL and the use of (differentiable) intrinsic objectives are required for sample-efficient learning.
7/N
- scaling is necessary but not sufficient
- reward is not enough. Learning world models by observation-based SSL and the use of (differentiable) intrinsic objectives are required for sample-efficient learning.
7/N
- reasoning and planning comes down to inference: finding a sequence of actions and latent variables that minimize a (differentiable) objective. This is an answer to the question of making reasoning compatible with gradient-based learning.
8/N
8/N
- In that setting, explicit mechanisms for symbol manipulation are probably unnecessary
9/N
9/N
Many of the ideas in this proposal are not new and not mine.
But I've tried to integrate them into coherent architecture.
I probably missed a lot of relevant references and would appreciate any literature pointer.
10/N
But I've tried to integrate them into coherent architecture.
I probably missed a lot of relevant references and would appreciate any literature pointer.
10/N
I have communicated about the content of this paper over the last few months:
- Blog post: ai.facebook.com/blog/yann-lecu…
- Talk hosted by Baidu:
11/N
- Blog post: ai.facebook.com/blog/yann-lecu…
- Talk hosted by Baidu:
11/N
- MIT Tech Review article by Melissa Heikkilä: technologyreview.com/2022/06/24/105…
- Fireside chat with Melissa Heikkilä at VivaTech: app.vivatechnology.com/session/b60b78…
12/N
- Fireside chat with Melissa Heikkilä at VivaTech: app.vivatechnology.com/session/b60b78…
12/N
- An FB post with the basic points of the paper: facebook.com/yann.lecun/pos…
13/N, N=13.
13/N, N=13.
• • •
Missing some Tweet in this thread? You can try to
force a refresh