
Professor at NYU & Executive Chairman at AMI Labs.
Ex-Chief AI Scientist at Meta.
Researcher in AI, Machine Learning, Robotics, etc.
ACM Turing Award Laureate.
 Errors accumulate.
Errors accumulate. The paper distills much of my thinking of the last 5 or 10 years about promising directions in AI.
The paper distills much of my thinking of the last 5 or 10 years about promising directions in AI. 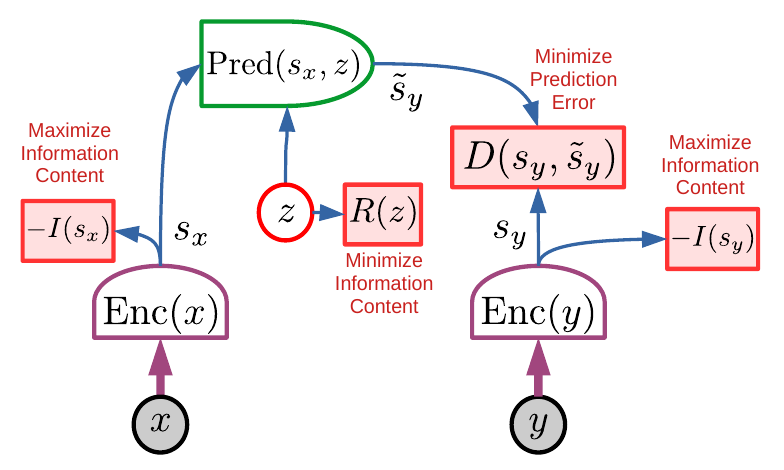
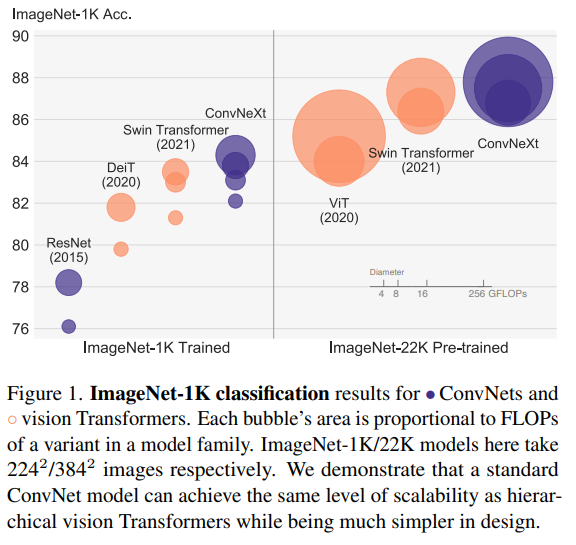 Some of the helpful tricks make complete sense: larger kernels, layer norm, fat layer inside residual blocks, one stage of non-linearity per residual block, separate downsampling layers....
Some of the helpful tricks make complete sense: larger kernels, layer norm, fat layer inside residual blocks, one stage of non-linearity per residual block, separate downsampling layers....


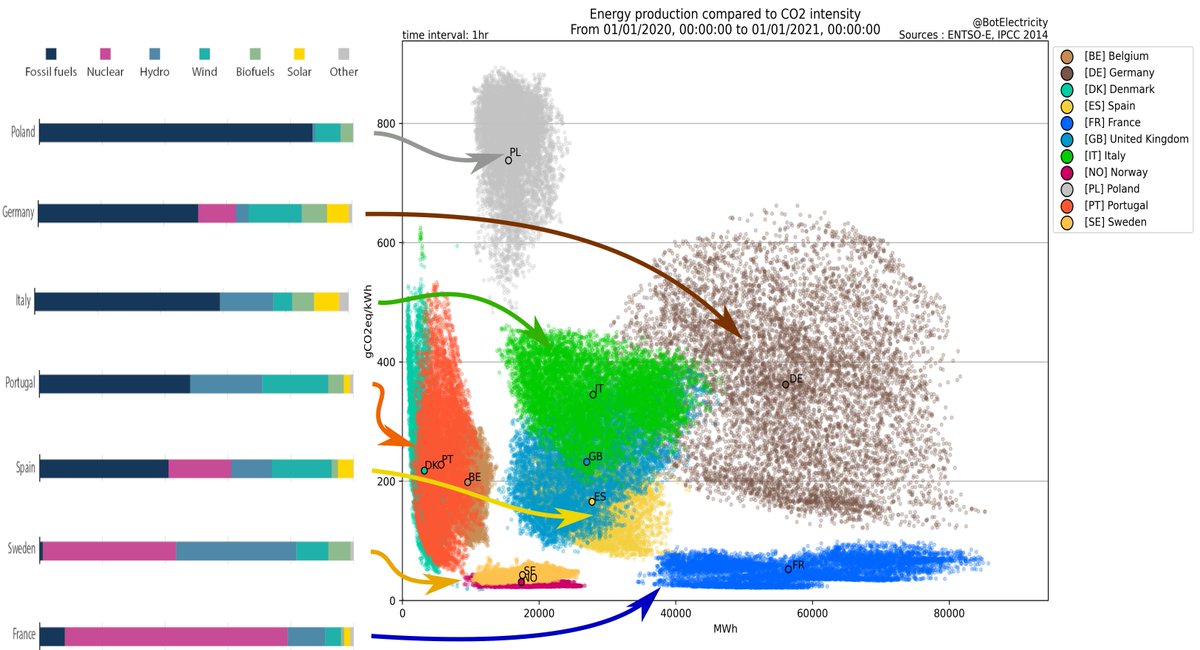 France: low overall CO2 emissions, low variance on emissions, relying essentially on nuclear energy with a bit of hydro [reminder: nuclear produce essentially no CO2].
France: low overall CO2 emissions, low variance on emissions, relying essentially on nuclear energy with a bit of hydro [reminder: nuclear produce essentially no CO2].