A scientific paper from Google gives some interesting insights into how Google today probably divides search queries into different thematic areas. Here is my summary of the paper in this thread.🧵 #seo #semanticsearch #google
The document"Improving semantic topic clustering for search queries with word co-occurrence and bipartite graph co-clustering"presents two methods that Google uses to contextually classify search queries.So-called lift scores play a central role in word co-occurrence clustering.
"Wi" in the formula stands for all terms that are closely related to the root of the word, such as misspellings, plural, singular or synonyms.
"a" can be any user interaction such as searching for a specific search term or visiting a specific page.
"a" can be any user interaction such as searching for a specific search term or visiting a specific page.
For example,if the lift score is 5,the probability that "Wi"will be searched is 5 times higher than that of "Wi"being searched in general. So the terms can then be assigned to specific entities such as Mercedes and/or the topical context class"Car" when searching for spare parts.
The context class and/or entity can then continue to be assigned terms that often occur as co-occurrences with the search terms. This is a quick way to create a cloud of terms for a specific topic. The level of the lift score determines the affinity to the topic:
🗣️"We use lift score to rank the words by importance and then threshold it to obtain a set of words highly associated with the context."
This method can be used in particular when "Wi" is already known, e.g. in search terms for brands or categories that are already known.
This method can be used in particular when "Wi" is already known, e.g. in search terms for brands or categories that are already known.
If "Wi" cannot be clearly defined because the search terms for the same topic are too different, Google could use a second method - "weighted bigraph clustering".
This method is based on two assumptions:
This method is based on two assumptions:
▶Users with the same intention formulate their search queries differently. However, search engines return the same search results.
▶Conversely, URLs similar to a search query are displayed on the first search results.
▶Conversely, URLs similar to a search query are displayed on the first search results.
With this method, the search terms are compared with the top-ranking URLs and query / URL pairs are formed, the relationship of which is also weighted according to the click rates of the users and impressions.
So similarities can also be created between search terms that do not have the same root and form semantic clusters from them.
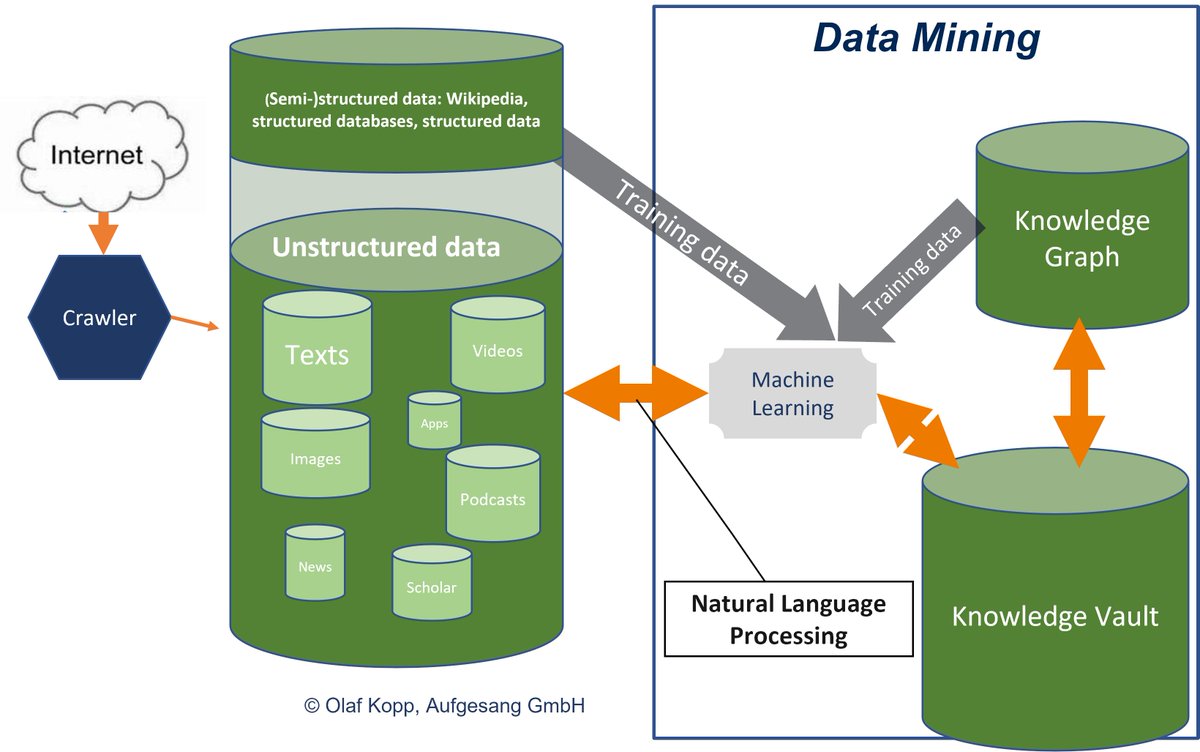
More insights into search query processing around interpretation of search queries in terms of meaning and search intent in my guide: kopp-online-marketing.com/search-query-p…


Here the formula according to the lift score: 

• • •
Missing some Tweet in this thread? You can try to
force a refresh