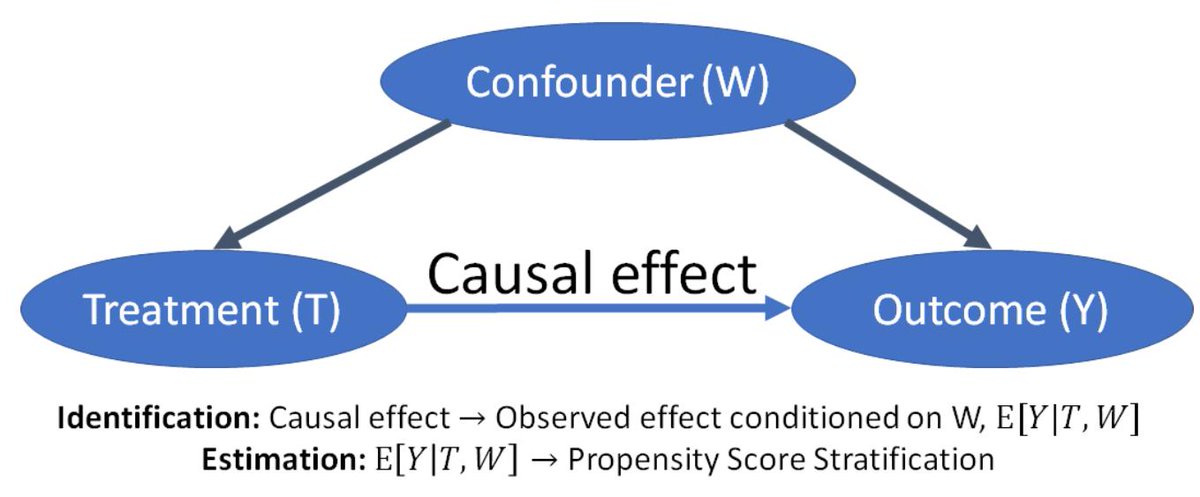
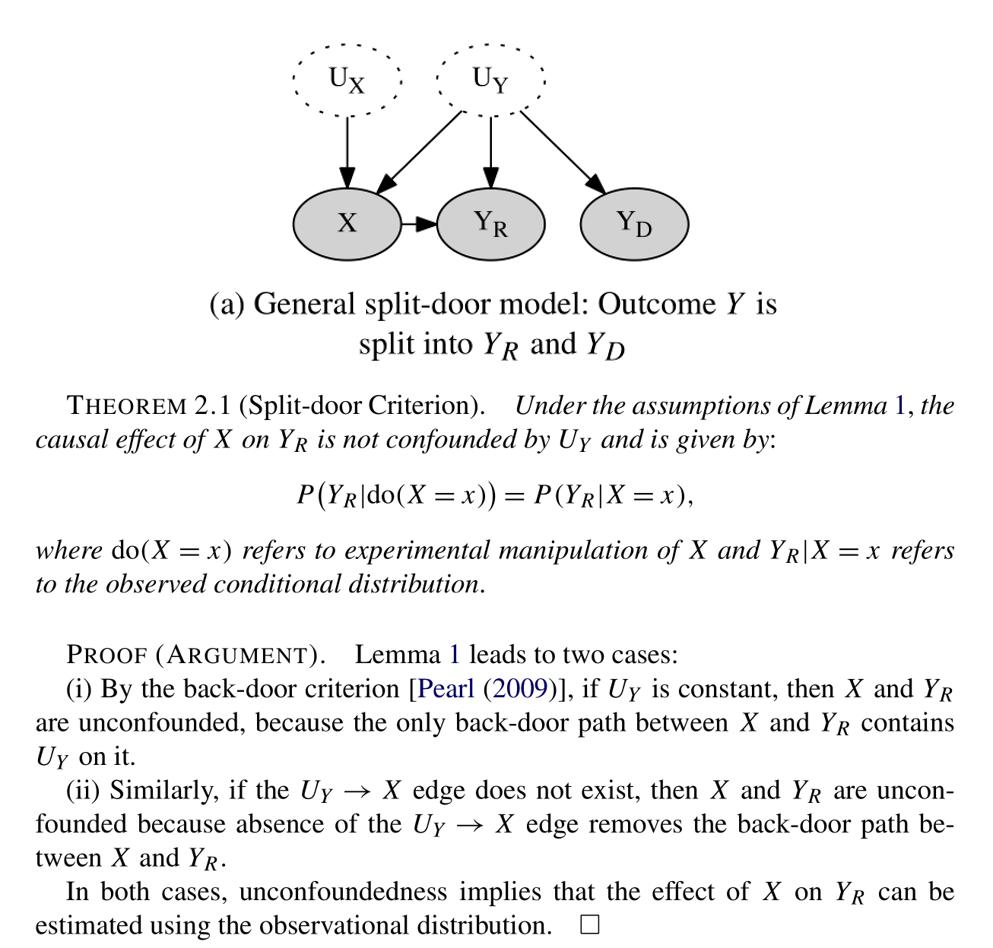
There is a lot of excitement about causal machine learning, but in what ways exactly can causality help with ML tasks?
In my work, I've seen four: enforcing domain knowledge, invariant regularizers, "counterfactual" augmentation & better framing for fairness & explanation. 🧵👇🏻
In my work, I've seen four: enforcing domain knowledge, invariant regularizers, "counterfactual" augmentation & better framing for fairness & explanation. 🧵👇🏻
1)Enforcing domain knowledge: ML models can learn spurious correlations. Can we avoid this by using causal knowledge from experts?
Rather than causal graphs, eliciting info on key relationships is a practical way. See #icml2022 paper on how to enforce them arxiv.org/abs/2111.12490
Rather than causal graphs, eliciting info on key relationships is a practical way. See #icml2022 paper on how to enforce them arxiv.org/abs/2111.12490
2) Invariant regularizers: For out-of-distribution generalization, another way is to add regularization constraints.
Causality can help us find the correct constraint for any dataset. Also easy to show that no single constraint can work everywhere. Algo: arxiv.org/abs/2206.07837
Causality can help us find the correct constraint for any dataset. Also easy to show that no single constraint can work everywhere. Algo: arxiv.org/abs/2206.07837
3) Data augmentation: Causal models can also help generate better augmentations: the trick is to identify and vary only the spurious features, thus breaking the correlational patterns.
This work shows that such samples are optimal for OOD generalization: arxiv.org/abs/2006.07500
This work shows that such samples are optimal for OOD generalization: arxiv.org/abs/2006.07500
And to create such augmentations, we extend the GAN architecture to support a causal graph and provide an algorithm to construct counterfactuals for any image. Here's an example for the CelebA dataset. Paper: arxiv.org/abs/2009.08270 

4)Fairness: Reasoning using causal graphs helps reveal the blind spots in current work.
E.g., majority of fairness literature ignores missing data and selection bias (e.g., training on those who got the loan). Such models will provably fail when deployed. arxiv.org/abs/2012.11448
E.g., majority of fairness literature ignores missing data and selection bias (e.g., training on those who got the loan). Such models will provably fail when deployed. arxiv.org/abs/2012.11448
Bonus: Enhancing privacy. It turns out that predictions from causal models are more differentially private than associational models (need less noise for the same epsilon), and as a result are robust to membership inference attacks. arxiv.org/abs/1909.12732
Joint work with @divyat09 @DashSaloni @emrek @jivatneet @ng_goel @shrutitople and Vineeth Balasubramanian.
If you are #icml2022 and would like to chat on these topics, please DM.
If you are #icml2022 and would like to chat on these topics, please DM.
@divyat09 @DashSaloni @emrek @jivatneet @ng_goel @shrutitople Overall, using causality does not always mean that we need to switch to a graphical model. Instead, it can already improve existing practices around regularization, augmentation and responsible AI.
Curious to hear what other applications people have seen?
Curious to hear what other applications people have seen?
• • •
Missing some Tweet in this thread? You can try to
force a refresh