
☕️ O quê é OOP?
Sei que vocês estão cansados de ver artigos e threads do tipo, mas vamos nesta 🧵 de 15 passos tentar dissecar algumas características primordiais de OOP através de uma simulação de OOP em, isso mesmo, Bash script.
OOP em Bash, a thread 👇
Sei que vocês estão cansados de ver artigos e threads do tipo, mas vamos nesta 🧵 de 15 passos tentar dissecar algumas características primordiais de OOP através de uma simulação de OOP em, isso mesmo, Bash script.
OOP em Bash, a thread 👇
Se você não tem hábito em Bash script, não há problema.
Os conceitos aqui explicados não exigem conhecimento avançado de Bash, a ideia é apenas tentar entender e simular OOP.
Os conceitos aqui explicados não exigem conhecimento avançado de Bash, a ideia é apenas tentar entender e simular OOP.
Para implementar OOP, precisamos obedecer algumas regras elementares:
* ter uma forma de representar o estado do objeto
* permitir execução dinâmica de ações no objeto
Claro que há mais coisas envolvidas, mas estas 2 são primordiais para se ter um mínimo de OOP.
* ter uma forma de representar o estado do objeto
* permitir execução dinâmica de ações no objeto
Claro que há mais coisas envolvidas, mas estas 2 são primordiais para se ter um mínimo de OOP.
Com Bash, conseguimos cumprir estas 2 regras? Vamos tentar demonstrar aos poucos, começando pela primeira.
Criamos então uma estrutura (função, pois não existem classes em Bash) que irá representar o template de um objeto
Criamos então uma estrutura (função, pois não existem classes em Bash) que irá representar o template de um objeto

Okay. Agora, vamos ver como seria a uma potencial utilização desta função para criarmos objetos.
Basicamente é passar argumentos para a função.
"$1": tipo do objeto
"$2": referência para o objeto
demais args: key-pair que deve representar o estado inicial do objeto
Basicamente é passar argumentos para a função.
"$1": tipo do objeto
"$2": referência para o objeto
demais args: key-pair que deve representar o estado inicial do objeto

Para fazer este truque funcionar, a função Object deve iterar por todos os args e criar o estado do objeto.
Mas onde fica tal estado, uma vez que Bash não é OOP?
Podemos deixar no estado global do script (credo, eu sei), onde cada atributo precede com a referência do objeto
Mas onde fica tal estado, uma vez que Bash não é OOP?
Podemos deixar no estado global do script (credo, eu sei), onde cada atributo precede com a referência do objeto


Okay, resolvemos a primeira regra, garantindo que o objeto tem um estado único e acessível (mas infelizmente global devido à característica léxica da linguagem).
E quanto à segunda regra, a ~execução dinâmica de ações no objeto~, ou comportamento?
Algo assim hipoteticamente:
E quanto à segunda regra, a ~execução dinâmica de ações no objeto~, ou comportamento?
Algo assim hipoteticamente:

Mas "chamar uma função" em um objeto não é possível, pois Bash não tem ~escopo léxico~, que é uma característica importante para que tenhamos o despacho dinâmico de mensagens em tempo de execução.
Entretanto podemos recorrer a outro truque.
Entretanto podemos recorrer a outro truque.
Dá pra guardar a função em uma variável associada ao objeto, e *posteriormente* passar a referência desse mesmo objeto para a função, que será então executada.
Começamos por definir, na criação do objeto, um argumento a mais que representará o comportamento.
Começamos por definir, na criação do objeto, um argumento a mais que representará o comportamento.

Então, definir a função em si que recebe a referência do objeto como primeiro argumento

Para então, modificar Object que agora também precisa saber fazer parse do argumento "fn_xxxx" que representa uma função do objeto, e guardar a referência da função em um atributo global de account (por isto o kind)

Com isto, podemos começar a criar objetos e chamar a função display neles.
Super YAY, mas dá pra melhorar isto.
Super YAY, mas dá pra melhorar isto.

Indo além, dá pra criar outra função chamada "Account", que será um wrapper para criação de objetos do tipo Account, assim dá pra agrupar todas as funções relacionadas à account dentro desta mesma estrutura.
Tá parecendo uma classe em OOP, não? :P
Tá parecendo uma classe em OOP, não? :P

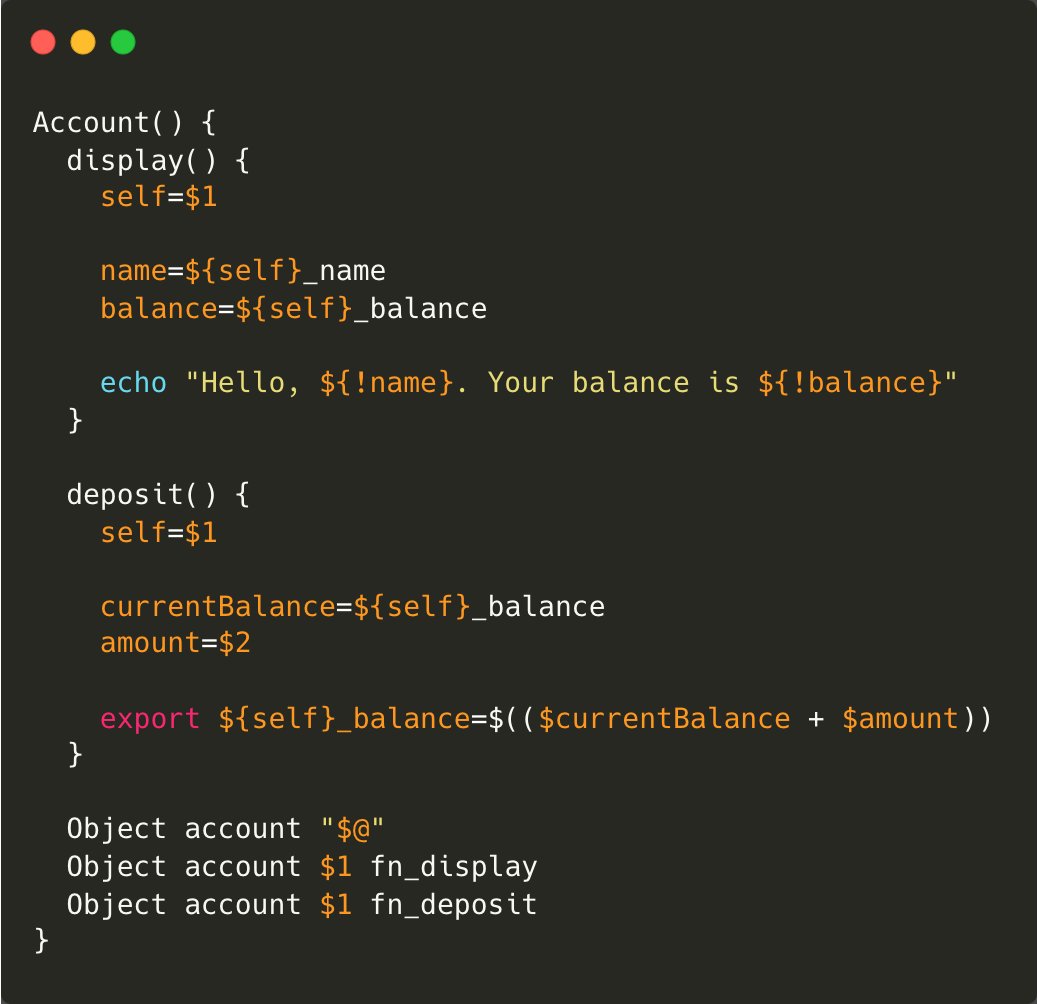
Implementação completa de Object

Agora, é só brincar com OOP em Bash

O código completo bem como uma explicação mais detalhada em inglês está neste Gist:
gist.github.com/leandronsp/5e7…
A ideia desta thread foi mostrar como que com 2 truques em Bash conseguimos simular 2 características primordiais de OOP.
Dá aquele RT maroto, gratidão ♥️
gist.github.com/leandronsp/5e7…
A ideia desta thread foi mostrar como que com 2 truques em Bash conseguimos simular 2 características primordiais de OOP.
Dá aquele RT maroto, gratidão ♥️
• • •
Missing some Tweet in this thread? You can try to
force a refresh












