
Why have diffusion models displaced GANs so quickly? Consider the tale of the (very strange) first DALLE model. In 2021, diffusions were almost unheard of, yet the creators of DALLE had already rejected the GAN approach. Here’s why. 🧵
DALLE is an image model, but it was built like a language model. The model trained on image-caption pairs. Captions were encoded as 256 tokens. Images were broken into a 32x32 grid of patches, which were each encoded as a token. All tokens were merged into a single sequence. 
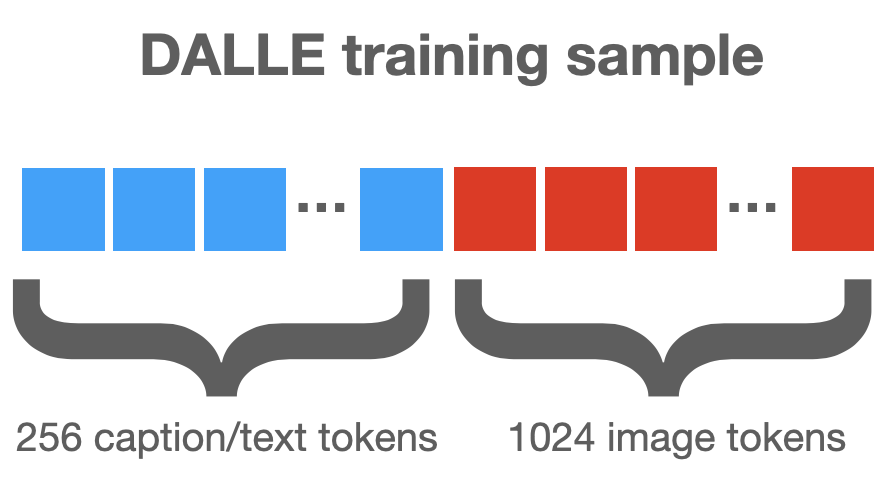
A transformer-based "language" model was trained on these sequences, ignoring the fact that some tokens represent text and some represent patches. The model reads in a partial sequence of tokens, and predicts the next token in the sequence.
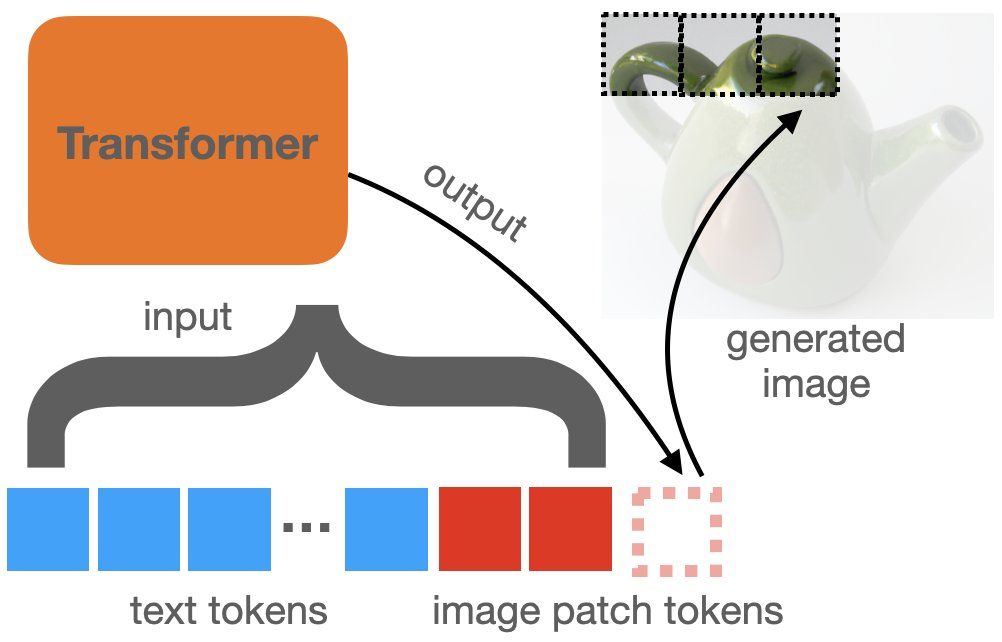
At test time, the model is first given a sequence of text tokens (the caption), and it produces the next token in the sequence (the upper left image patch). Then the existing text+patch tokens are handed back to the model, and it produces the next image patch.
So why didn't DALLE just use a GAN? GAN training requires solving a saddle-point/minimax problem, which is quite unstable. Simple tricks can help stabilize this (shameless self-promotion alert: openreview.net/forum?id=Skj8K…), but the problem remains.
In fact, GANs were proposed by Goodfellow in 2014, but it took three years and countless gallons of grad student tears before stable routines for ImageNet appeared in 2017. Training on the very large and diverse DALLE dataset would have been extremely challenging.
Unlike GANs, the language model approach to DALLE required minimization of a standard convex cross-entropy loss, and we know how to make that stable.
Today, the vision community is turning towards diffusion models. Diffusions are built on simple image denoising nets that minimize a convex regression loss (usually least-squares or L1). No minimax. Easy breezy. It was probably an easy choice to build DALLE2 on this approach.
The success of diffusion models is a great example of the impact that a new mathematical paradigm can have. All the hyper-parameter tuning in the world can't beat a few lines of thoughtful math.
• • •
Missing some Tweet in this thread? You can try to
force a refresh


















