
// Stable Diffusion, Explained //
You've seen the Stable Diffusion AI art all over Twitter.
But how does Stable Diffusion _work_?
A thread explaining diffusion models, latent space representations, and context injection:
1/15
You've seen the Stable Diffusion AI art all over Twitter.
But how does Stable Diffusion _work_?
A thread explaining diffusion models, latent space representations, and context injection:
1/15




First, a one-tweet summary of diffusion models (DMs).
Diffusion is the process of adding small, random noise to an image, repeatedly. (Left-to-right)
Diffusion models reverse this process, turning noise into images, bit-by-bit. (Right-to-left)
Photo credit: @AssemblyAI
2/15
Diffusion is the process of adding small, random noise to an image, repeatedly. (Left-to-right)
Diffusion models reverse this process, turning noise into images, bit-by-bit. (Right-to-left)
Photo credit: @AssemblyAI
2/15

How do DMs turn noise into images?
By training a neural network to do so gradually.
With the sequence of noised images = x_1, x_2, ... x_T,
The neural net learns a function f(x,t) that denoises x "a little bit", producing what x would look like at time step t-1.
3/15
By training a neural network to do so gradually.
With the sequence of noised images = x_1, x_2, ... x_T,
The neural net learns a function f(x,t) that denoises x "a little bit", producing what x would look like at time step t-1.
3/15
To turn pure noise into an HD image, just apply f several times!
The output of a diffusion model really is just
f(f(f(f(....f(N, T), T-1), T-2)..., 2, 1)
where N is pure noise, and T is the number of diffusion steps.
The neural net f is typically implemented as a U-net.
4/15
The output of a diffusion model really is just
f(f(f(f(....f(N, T), T-1), T-2)..., 2, 1)
where N is pure noise, and T is the number of diffusion steps.
The neural net f is typically implemented as a U-net.
4/15

The key idea behind Stable Diffusion:
Training and computing a diffusion model on large 512 x 512 images is _incredibly_ slow and expensive.
Instead, let's do the computation on _embeddings_ of images, rather than on images themselves.
5/15
Training and computing a diffusion model on large 512 x 512 images is _incredibly_ slow and expensive.
Instead, let's do the computation on _embeddings_ of images, rather than on images themselves.
5/15

So, Stable Diffusion works in two steps.
Step 1: Use an encoder to compress an image "x" into a lower-dimensional, latent-space representation "z(x)"
Step 2: run diffusion and denoising on z(x), rather than x.
Diagram below!
6/15
Step 1: Use an encoder to compress an image "x" into a lower-dimensional, latent-space representation "z(x)"
Step 2: run diffusion and denoising on z(x), rather than x.
Diagram below!
6/15

The latent space representation z(x) has much smaller dimension than the image x.
This makes the _latent_ diffusion model much faster and more expressive than an ordinary diffusion model.
See dimensions from the SD paper:
7/15
This makes the _latent_ diffusion model much faster and more expressive than an ordinary diffusion model.
See dimensions from the SD paper:
7/15

But where does the text prompt come in?
I lied! SD does NOT learn a function f(x,t) to denoise x a "little bit" back in time.
It actually learns a function f(x, t, y), with y the "context" to guide the denoising of x.
Below, y is the image label "arctic fox".
8/15
I lied! SD does NOT learn a function f(x,t) to denoise x a "little bit" back in time.
It actually learns a function f(x, t, y), with y the "context" to guide the denoising of x.
Below, y is the image label "arctic fox".
8/15


When using Stable Diffusion to make AI art, the "context" y is the text prompt you enter.
That's how the text prompt works.
(Image credit: @ari_seff's video ).
9/15
That's how the text prompt works.
(Image credit: @ari_seff's video ).
9/15


But how does SD process context?
The "context" y, alongside the time step t, can be injected into the latent space representation z(x) either by:
1) Simple concatenation
2) Cross-attention
Stable diffusion uses both.
10/15
The "context" y, alongside the time step t, can be injected into the latent space representation z(x) either by:
1) Simple concatenation
2) Cross-attention
Stable diffusion uses both.
10/15
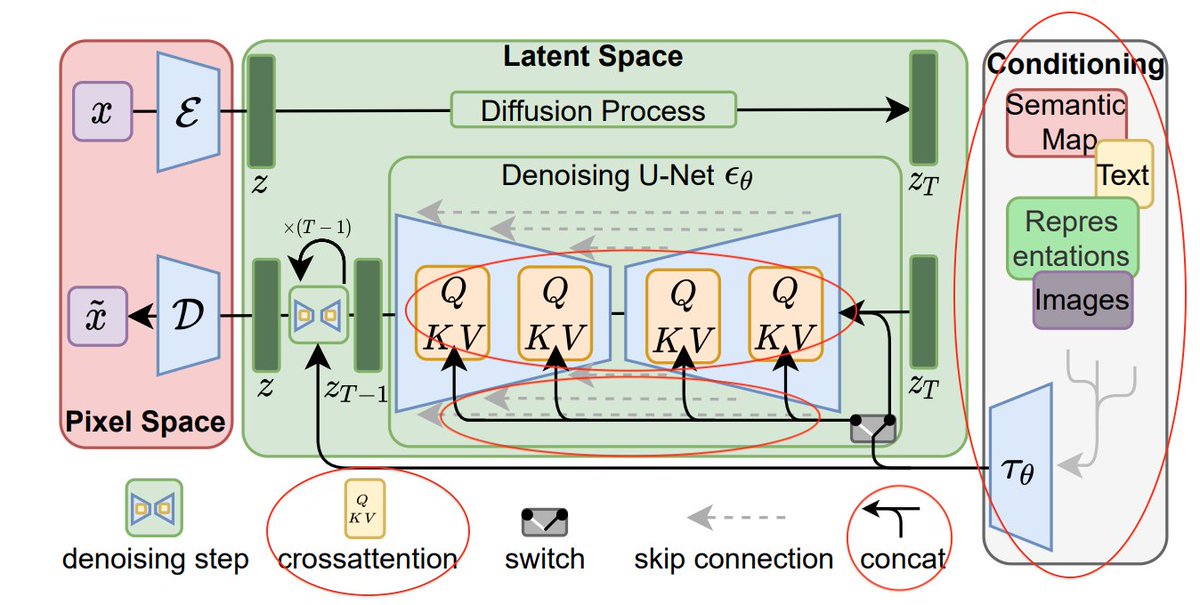
The cool part not talked about on Twitter: the context mechanism is incredibly flexible.
Instead of y = an image label,
Let y = a masked image, or y = a scene segmentation.
SD trained on this different data, can now do image inpainting and semantic image synthesis!
11/15
Instead of y = an image label,
Let y = a masked image, or y = a scene segmentation.
SD trained on this different data, can now do image inpainting and semantic image synthesis!
11/15
(The above inpainting gif isn't from Stable Diffusion, FYI. Just an illustration of inpainting.)
Photos from the SD paper illustrating image inpainting and image synthesis, by changing the "context" representation y:
12/15
Photos from the SD paper illustrating image inpainting and image synthesis, by changing the "context" representation y:
12/15


That's a wrap on Stable Diffusion! If you read the thread carefully, you understand:
1) The full SD architecture below
2) How SD uses latent space representations
3) how the text prompt is used as "context"
4) how changing the "context" repurposes SD to other tasks.
13/15
1) The full SD architecture below
2) How SD uses latent space representations
3) how the text prompt is used as "context"
4) how changing the "context" repurposes SD to other tasks.
13/15

If this thread helped you learn about Stable Diffusion, likes, retweets, and follows are appreciated!
In addition to threads like this, I publish a "Best of AI Twitter" thread every week - last week's below.
14/15
In addition to threads like this, I publish a "Best of AI Twitter" thread every week - last week's below.
https://twitter.com/ai__pub/status/1560334887927701505
14/15
PSS this thread is pretty technical!
Check out these two videos if you want to understand Stable Diffusion at a higher-level/ in less technical format:
16/15
Check out these two videos if you want to understand Stable Diffusion at a higher-level/ in less technical format:
16/15
https://twitter.com/ai__pub/status/1561147847092817920
• • •
Missing some Tweet in this thread? You can try to
force a refresh


