🔥Top Trending ML Papers of the Month
Here is a thread to catchup on the top 10 trending papers of August on @paperswithcode.
Here is a thread to catchup on the top 10 trending papers of August on @paperswithcode.

1) An Image is Worth One Word - a new approach that allows for more creative freedom with image generation; proposes "textual inversions" to find pseudo-words that compose new sentences that guide personalized creations.
paperswithcode.com/paper/an-image…
paperswithcode.com/paper/an-image…
2) Cold Diffusion - proposes diffusion models built around arbitrary image transformations without Gaussian noise; discusses the potential for generalized diffusion models that invert arbitrary processes.
paperswithcode.com/paper/cold-dif…
paperswithcode.com/paper/cold-dif…

3) Image as a Foreign Language - proposes a multimodal foundation model called BEiT-3 which achieves state-of-the-art performance on many vision and language tasks.
paperswithcode.com/paper/image-as…
paperswithcode.com/paper/image-as…

4) 3D Vision with Transformers - a comprehensive overview of transformers for 3D tasks, which include classification, segmentation, detection, pose estimation, and more.
paperswithcode.com/paper/3d-visio…
paperswithcode.com/paper/3d-visio…
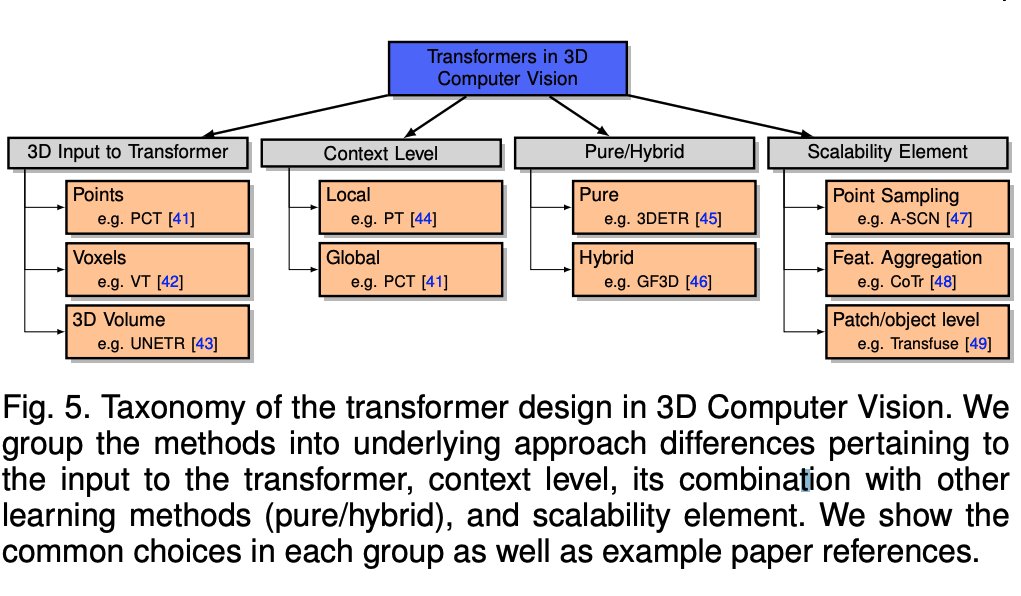
5) LLM.int8() - a new quantization procedure that allows large scale model checkpoints (16/32-bit) to be loaded and converted to Int8. This allows access to large language models (LLMs) that could not be accessed due to limited GPU memory.
paperswithcode.com/paper/llm-int8…
paperswithcode.com/paper/llm-int8…
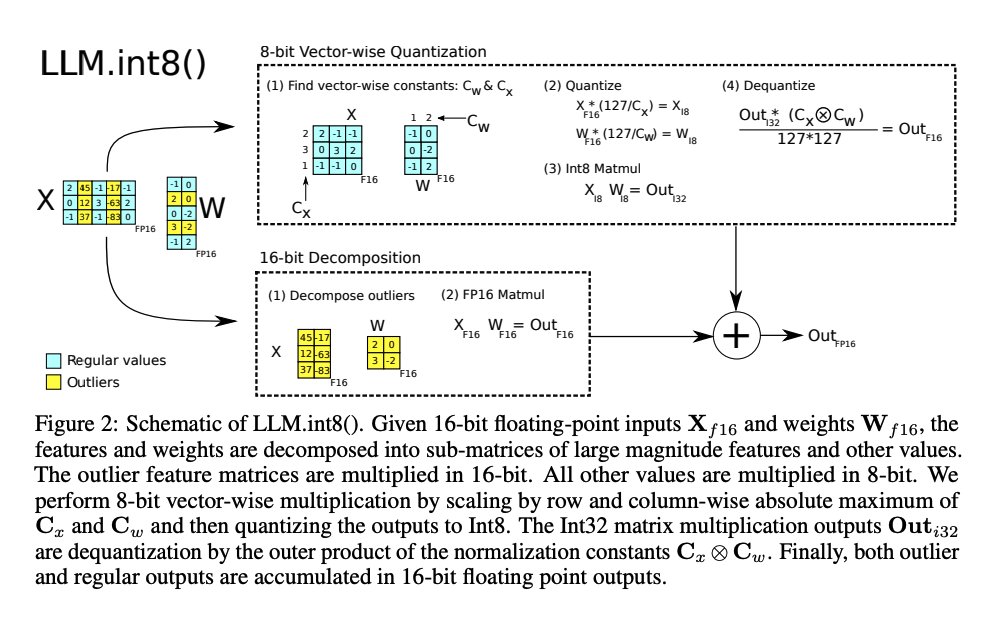
6) Flow-Guided Transformer - proposes a Transformer-base model leveraging motion discrepancy from optical flows; this approach helps to instruct attention retrieval in transformers for video inpainting.
paperswithcode.com/paper/flow-gui…
paperswithcode.com/paper/flow-gui…
7) MinVIS - a minimal video instance segmentation framework, without video-based training, that produces state-of-the-art performance and is comparable to fully-supervised approaches.
paperswithcode.com/paper/minvis-a…
paperswithcode.com/paper/minvis-a…

8) PeRFception - leverages NeRF variant to create large-scale implicit representation datasets for perception tasks.
paperswithcode.com/paper/perfcept…
paperswithcode.com/paper/perfcept…

9) YOLOPv2 - an effective and efficient multi-task learning network for performing faster and better on tasks such as traffic object detection and lane detection.
paperswithcode.com/paper/yolopv2-…
paperswithcode.com/paper/yolopv2-…

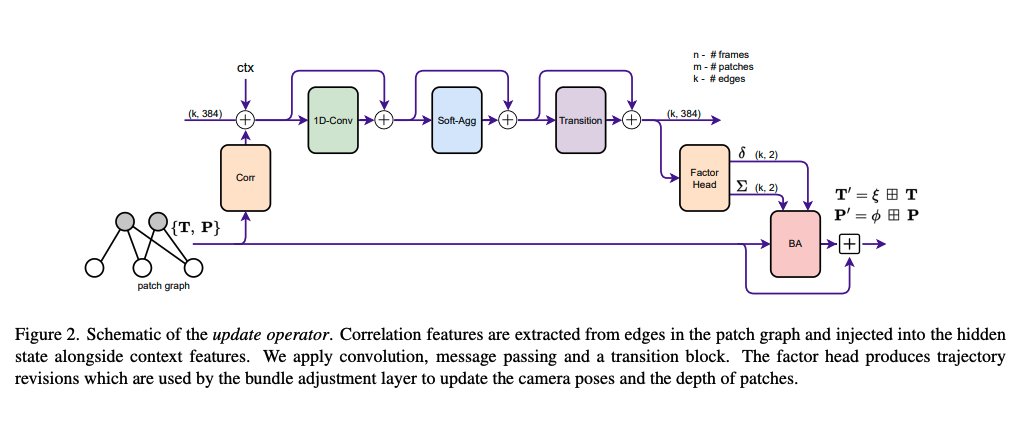
10) Deep Patch Visual Odometry - a new deep learning system for monocular visual odometry that achieves 2x-5x real-time speeds; outperforms previous works on several benchmarks in terms of accuracy and speed.
paperswithcode.com/paper/deep-pat…
paperswithcode.com/paper/deep-pat…
You can catch more trending machine learning papers daily on Papers with Code. Check out the following sections:
Top Trending: paperswithcode.com
Top Social: paperswithcode.com/top-social
Browse SoTA: paperswithcode.com/sota
Top Trending: paperswithcode.com
Top Social: paperswithcode.com/top-social
Browse SoTA: paperswithcode.com/sota
• • •
Missing some Tweet in this thread? You can try to
force a refresh