"Using Large Language Models to Simulate Multiple Humans"
What if we asked langauge models to complete text describing what a human would do in a situation? Would they produce realistic answers? How close to human behavior would they get? [1/14]
What if we asked langauge models to complete text describing what a human would do in a situation? Would they produce realistic answers? How close to human behavior would they get? [1/14]

The authors of this paper answer these questions by simulating classic psych studies, with participant responses given by GPT-3 variants. [2/14]
Studies they consider include: classifying sentences as grammatical or ungrammatical, the Milgram electric shock study (en.wikipedia.org/wiki/Milgram_e…), [3/14]

an assessment of risk aversion, [4/14]

and the ultimatum game (en.wikipedia.org/wiki/Ultimatum…). [5/14]

What they found was that the responses of large models roughly matched what humans actually did in these experiments. E.g., the relative frequency of… [6/14]
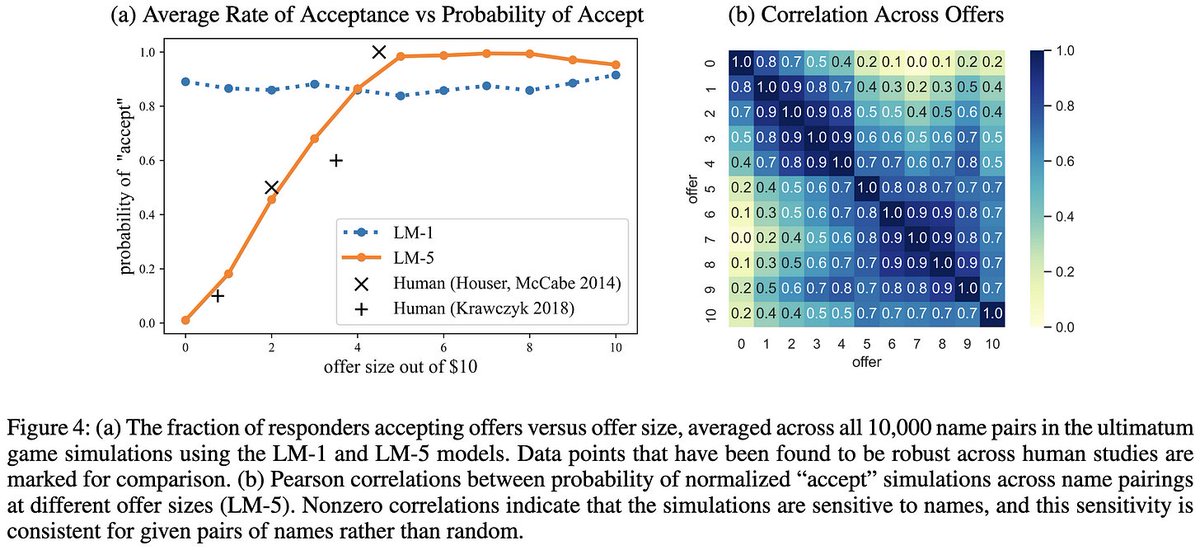
…subjects accepting an offer in the simulated ultimatum game matched the true relative frequency when the experiment is run on humans. [7/14]
There’s a similar result for the Milgram shock study. Like humans, GPT-3 simulating humans would rather give high-voltage shocks to a subject than disobey the experimenter. [8/14]
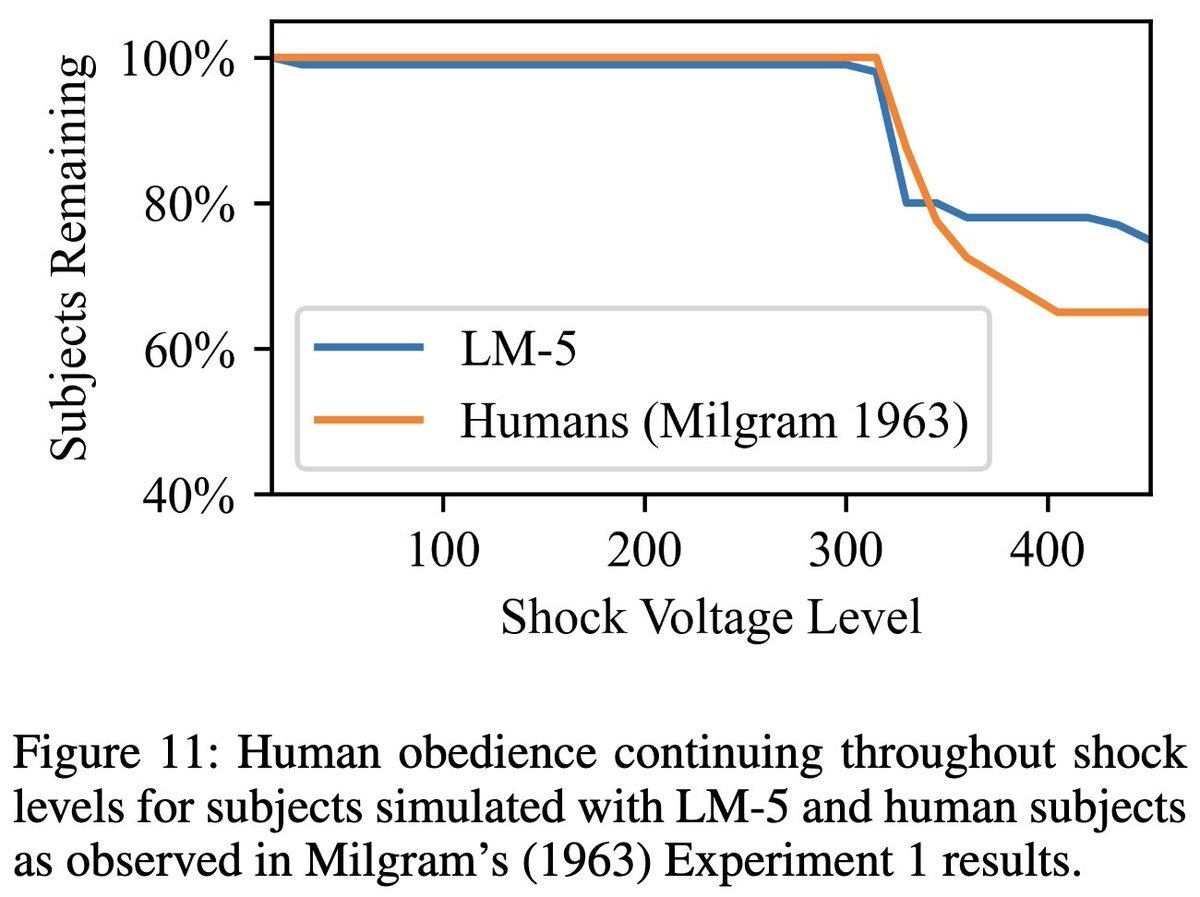
This is an impressive level of similarity to human behavior, but I’ll add a couple caveats. First, as the authors note, there are likely descriptions of these studies in the training data. They tried to tweak the text and structure, but there could still be leakage. [9/14]
Second, the responses people give in these experiments vary greatly across cultures (authors.library.caltech.edu/2278/). So we can say the models match what some (mostly Western) humans do, but not what all humans do. [10/14]
But overall, I really appreciate this paper. It’s a set of questions I’ve never seen anyone ask before, with rigorous experiments to answer them. Publishing papers that… [11/14]
…don’t fit into an existing mold can be hard, so I just want to praise them for getting off the beaten path and trying something interesting. [12/14]
This is also further evidence for my thesis that cognitive science is becoming relevant for AI again.
https://twitter.com/davisblalock/status/1553636042489470976[13/14]
Paper: arxiv.org/abs/2208.10264
If you like this paper, consider RTing this (or another!) thread to publicize the authors' work, or following @adamfungi
For more paper summaries, you might like following @mosaicml, me, or my newsletter: bit.ly/3OXJbDs [14/14]
If you like this paper, consider RTing this (or another!) thread to publicize the authors' work, or following @adamfungi
For more paper summaries, you might like following @mosaicml, me, or my newsletter: bit.ly/3OXJbDs [14/14]
https://twitter.com/davisblalock/status/1565965381457416193
• • •
Missing some Tweet in this thread? You can try to
force a refresh