
Research scientist @GoogleDeepMind. Past: @Databricks, first hire @MosaicML, @MIT PhD. I post about AI papers + sometimes the business side.
 First, observe that the memory required by an optimization algorithm isn’t just the optimizer state: you also have to store a gradient and a high-precision “master weight” for each parameter.
First, observe that the memory required by an optimization algorithm isn’t just the optimizer state: you also have to store a gradient and a high-precision “master weight” for each parameter.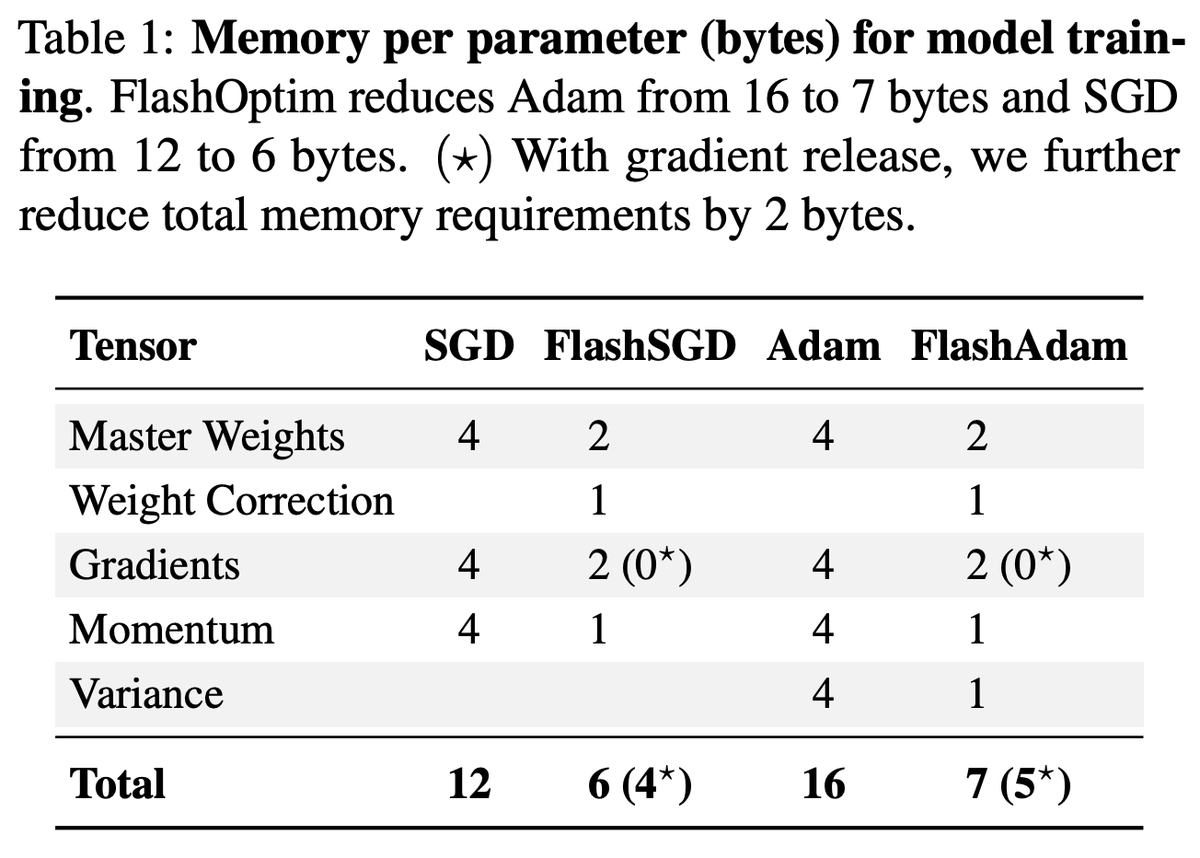
 By “dumpster fire”, I mean not just well-known issues like vanishing gradients or loss spikes, but also subtle stuff like the variance of your token embeddings collapsing in hard-to-model ways as your sequence length grows. [2/11]
By “dumpster fire”, I mean not just well-known issues like vanishing gradients or loss spikes, but also subtle stuff like the variance of your token embeddings collapsing in hard-to-model ways as your sequence length grows. [2/11] 

 First, for a fixed number of bits, floating point addition takes more transistors. [2/11]
First, for a fixed number of bits, floating point addition takes more transistors. [2/11] 
 They make this happen by assembling a huge dataset, designing an appropriate model, and using a particular training setup.
They make this happen by assembling a huge dataset, designing an appropriate model, and using a particular training setup.
 The first result here is that, as you’d hope, this approach works better when you use larger models and datasets. In particular, using a 3 billion sample Instagram {image, hashtag} dataset works better than just ImageNet-1k. [2/9]
The first result here is that, as you’d hope, this approach works better when you use larger models and datasets. In particular, using a 3 billion sample Instagram {image, hashtag} dataset works better than just ImageNet-1k. [2/9] 



 The examples above aren't cherrypicked. Choose any controversy and there's a good chance ChatGPT will only help you support one side.
The examples above aren't cherrypicked. Choose any controversy and there's a good chance ChatGPT will only help you support one side.



 …eliminating samples within a cluster that have too high a cosine similarity to one another. The idea is that eliminating redundancy in the training set should improve training. [2/16]
…eliminating samples within a cluster that have too high a cosine similarity to one another. The idea is that eliminating redundancy in the training set should improve training. [2/16]

 First is just collecting and categorizing a lot of papers on efficient training. We didn’t capture all of them, but there’s a wide selection that should give you a feel for what’s out there. [2/16]
First is just collecting and categorizing a lot of papers on efficient training. We didn’t capture all of them, but there’s a wide selection that should give you a feel for what’s out there. [2/16] 
 First, let's be precise: by "the hardest sequence modeling benchmark," I mean the Long Range Arena (arxiv.org/abs/2011.04006). This consists of tasks like Pathfinder (shown above) that are designed to require modeling of long-range dependencies. [2/14]
First, let's be precise: by "the hardest sequence modeling benchmark," I mean the Long Range Arena (arxiv.org/abs/2011.04006). This consists of tasks like Pathfinder (shown above) that are designed to require modeling of long-range dependencies. [2/14]
 One observation is that different augmentations help in different data regimes. With not much data, aggressive augmentations are better. With more data, conservative augmentations like horizontal flipping… [2/12]
One observation is that different augmentations help in different data regimes. With not much data, aggressive augmentations are better. With more data, conservative augmentations like horizontal flipping… [2/12] 
 First, it’s not that most neurons are dead, but that nearly all neurons fire rarely. It’s only a handful that fire more than half the time. [2/14]
First, it’s not that most neurons are dead, but that nearly all neurons fire rarely. It’s only a handful that fire more than half the time. [2/14] 
 At least for the Connect Four and Pentago agents they trained, the answer is yes. And interestingly, the exponents for the two games are nearly identical. [2/6]
At least for the Connect Four and Pentago agents they trained, the answer is yes. And interestingly, the exponents for the two games are nearly identical. [2/6] 
 To understand this feedback loop, first recall that the edge of stability means that the operator norm of the local Hessian (the "curvature") is 2/η, where η is the learning rate. 2/η is the most curvature one can have without diverging. [2/12]
To understand this feedback loop, first recall that the edge of stability means that the operator norm of the local Hessian (the "curvature") is 2/η, where η is the learning rate. 2/η is the most curvature one can have without diverging. [2/12]
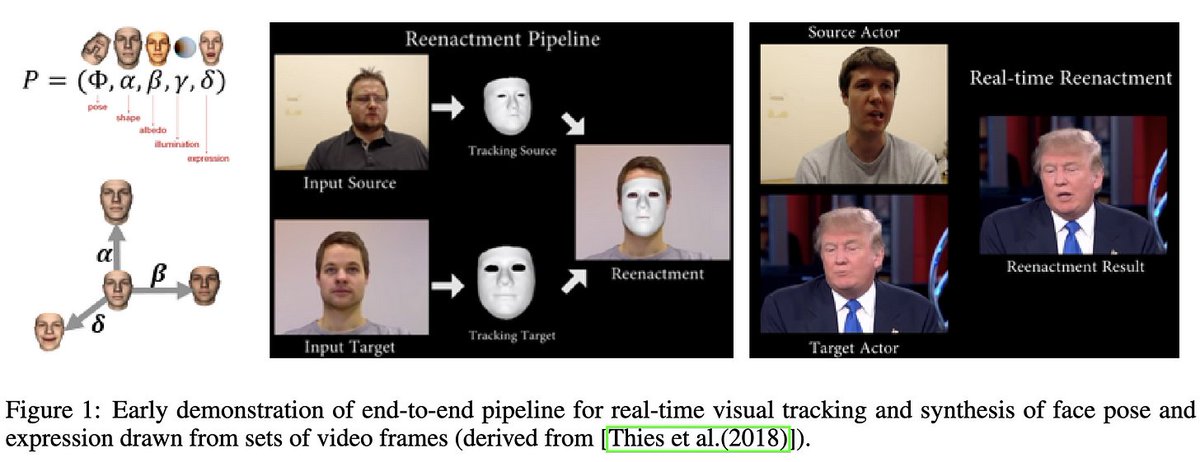 The first is the "interactive deepfake." This is not just static content, but the illusion of talking to a real person. Imagine a scammer calling your grandmom who looks and sounds exactly like you. Or thinking you're meeting someone online but actually it's a bot. [2/11]
The first is the "interactive deepfake." This is not just static content, but the illusion of talking to a real person. Imagine a scammer calling your grandmom who looks and sounds exactly like you. Or thinking you're meeting someone online but actually it's a bot. [2/11] 
 Surprisingly...yes. The idea is simple: if your activation function is λ times as steep, your gradient with respect to the input gets scaled by λ. So if you do… [2/8]
Surprisingly...yes. The idea is simple: if your activation function is λ times as steep, your gradient with respect to the input gets scaled by λ. So if you do… [2/8]
 In particular, should you 1) do supervised or self-supervised pretraining on a general-purpose corpus like ImageNet? And 2) bother adding a second self-supervised learning step on domain-specific data? [2/9]
In particular, should you 1) do supervised or self-supervised pretraining on a general-purpose corpus like ImageNet? And 2) bother adding a second self-supervised learning step on domain-specific data? [2/9]
