Gather round, Twitter folks, it's time for our beloved
**Alice's adventures in a differentiable wonderland**, our magical tour of autodiff and backpropagation. 🔥
Slides below 1/n 👇
**Alice's adventures in a differentiable wonderland**, our magical tour of autodiff and backpropagation. 🔥
Slides below 1/n 👇

It all started from her belief that "very few things indeed were really impossible". Could AI truly be below the corner? Could differentiability be the only ingredient that was needed?
2/n
2/n

Wondering were to start, Alice discovered a paper by pioneer @ylecun promising "a path towards autonomous intelligent agents".
Intelligence would arise, it was argued, by several interacting modules, were everything was assumed to be *differentiable*.
3/n
Intelligence would arise, it was argued, by several interacting modules, were everything was assumed to be *differentiable*.
3/n
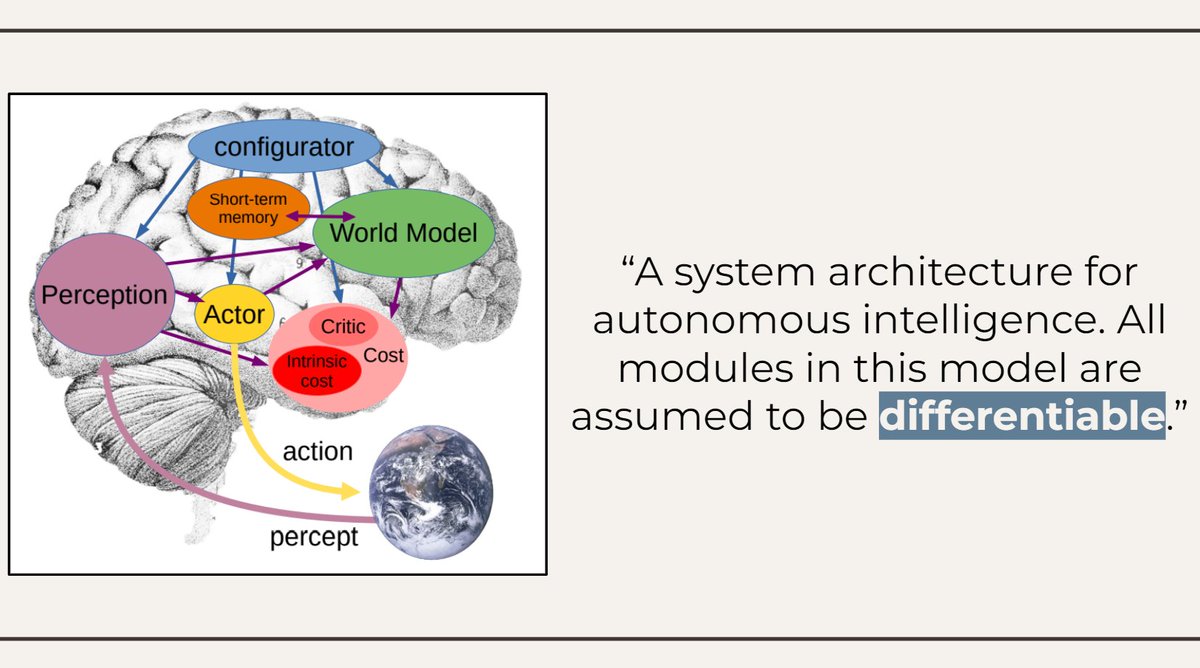
Alice reasoned that differentiability was, indeed, the only thing that could make sense of the explosion of deep learning architectures, from Transformers to neural computers and implicit layers.
4/n
4/n

It was time, then, to learn a bit about differentiability and gradient descent. This made sense, as the Cat told her that "if you don't care where you are going, it does not matter which way you go".
5/n
5/n

Alice fell through the looking glass in a strange world made of gradient, Jacobians, VJPs, and other mythical creatures. It was not so hard as it appeared at the beginning, though.
6/n
6/n

She learned about function composition, automatic differentiation, and the difference between forward-mode (left-to-right) and reverse-mode (right-to-left) differentiation.
7/n
7/n

"But wait!", the Dodo told her. "The best way to explain is to do it."
So Alice set out to build her own autodiff system.
8/n
So Alice set out to build her own autodiff system.
8/n

She first started by learning more about the anatomy of a deep learning framework: primitives, JVPs, dispatchers and schedulers.
9/n
9/n

Time to start building! Luckily, she had help from a number of scientists who guided her along the way: @mblondel_ml @SingularMattrix (autodidact) @karpathy (micrograd) @realGeorgeHotz (tinygrad).
10/n
10/n

The core of an autodiff system turned out to be easier than expected, and she ended up re-implementing a simple PyTorch-like API.
Not fully working, but enough to get a glimpse of its functioning. At that moment, she felt like she was getting the hang of this wonderland.
11/n
Not fully working, but enough to get a glimpse of its functioning. At that moment, she felt like she was getting the hang of this wonderland.
11/n

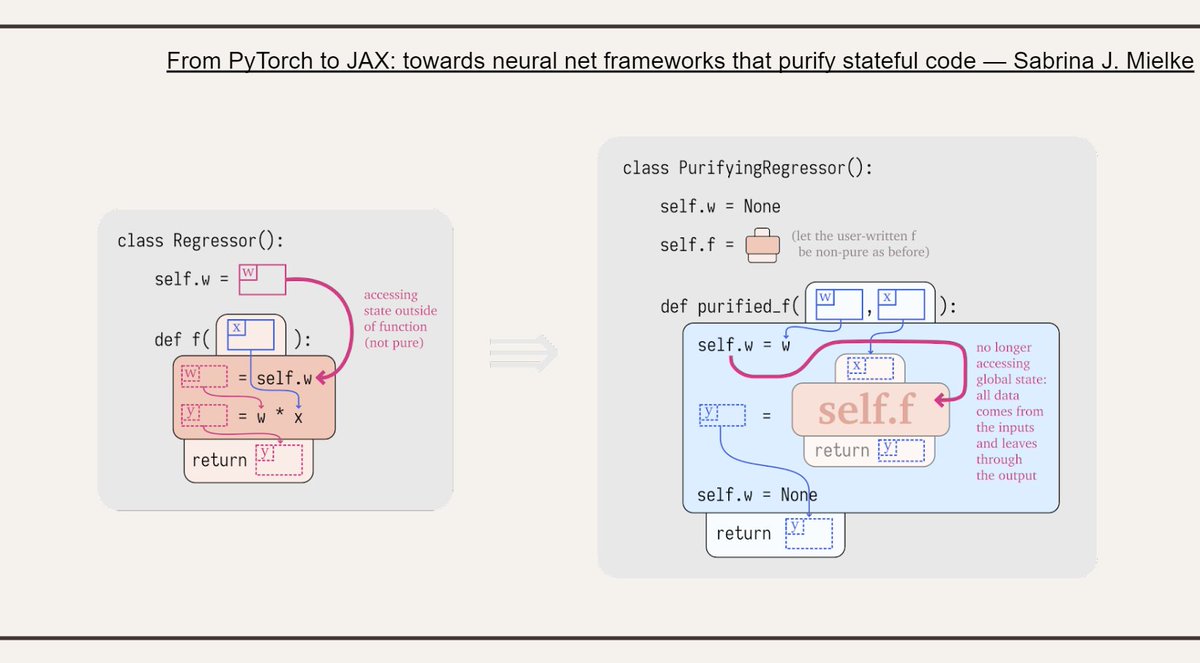
Alice also learned about object-oriented vs. functional frameworks, and thanks to @sjmielke and her tutorials, she learned how to purify one code to move from one side to the other.
12/n
12/n
"Curioser and curioser!" cried Alice, as she moved to more advanced topics while simultaneously loosing her grasp on English.
13/n
13/n

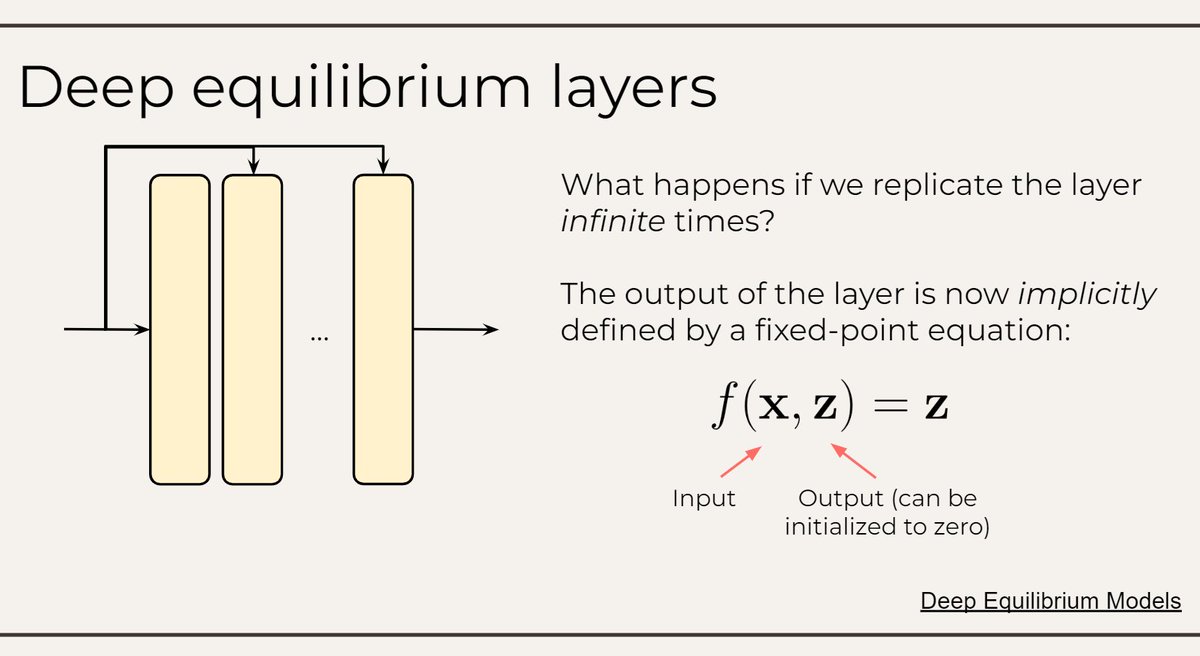
You can also differentiate through an implicitly defined layer! She wondered in puzzlement while exploring the tutorial of @zicokolter, @DavidDuvenaud, @SingularMattrix and understanding that this was, indeed, a stranger land than anything she expected.
14/n
14/n
Exhausted, she finally got home. Did she learned anything useful? Was she indeed closer to AI? “Tut, tut, child!” said the Duchess. “Everything’s got a moral, if only you can find it.”
Maybe even these slides.
Slides are here: docs.google.com/presentation/d…
Maybe even these slides.
Slides are here: docs.google.com/presentation/d…

@alfcnz I am sure you will appreciate the absurd amount of time I devoted to these slides. 😎
@mmbronstein @PetarV_93 Now I wanted to make Alice's adventures in a geometric wonderland, but I exhausted my creativity. 🥲
• • •
Missing some Tweet in this thread? You can try to
force a refresh