FSDL Lecture 7: Foundation Models is now available!
This lecture is 💯 new to the course.
We talk about building on Transformers, GPT-3, CLIP, StableDiffusion, and other foundation models.
Brief thread below.
This lecture is 💯 new to the course.
We talk about building on Transformers, GPT-3, CLIP, StableDiffusion, and other foundation models.
Brief thread below.
https://twitter.com/sergeykarayev/status/1572027734276345858
The brave new world of large models is astonishing.
With scale, these models show emergent capabilities that seem truly magical.
At hundreds of billions of params, many GPUs are needed simply to load the model, and API-based access makes a lot of sense.
With scale, these models show emergent capabilities that seem truly magical.
At hundreds of billions of params, many GPUs are needed simply to load the model, and API-based access makes a lot of sense.

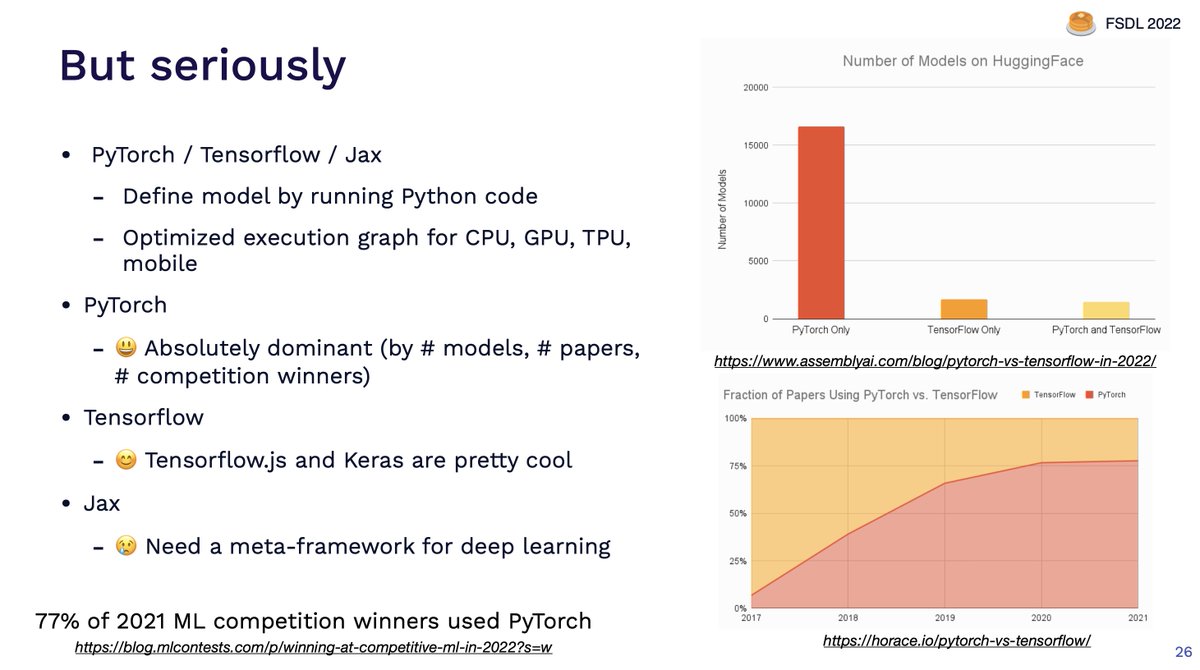
We start old-school, talking about the importance of embeddings and the concept of fine-tuning models.

Then we talk about the Transformer architecture, covering its three simple components:
· Self-attention
· Positional encoding
· Layer normalization
· Self-attention
· Positional encoding
· Layer normalization

We cover the most notable LLMs:
· BERT
· GPT/GPT-2/GPT-3
· T5
· Instruct-GPT
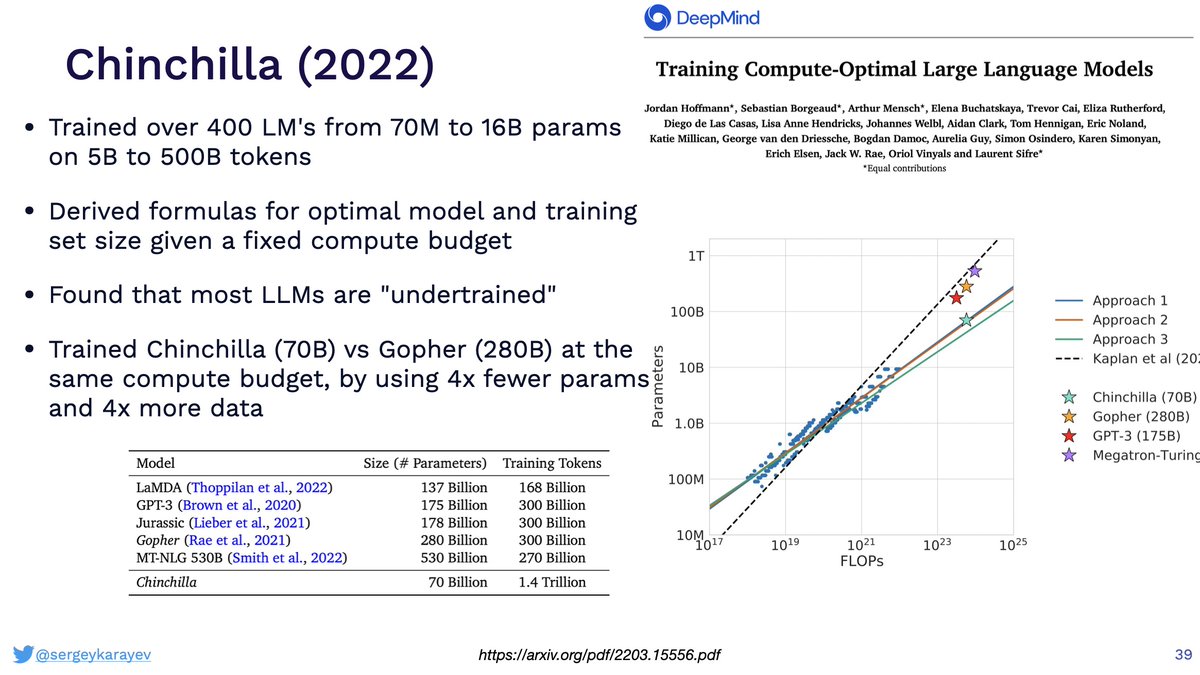
· RETRO
· Chinchilla (and its Scaling Law implications)
· BERT
· GPT/GPT-2/GPT-3
· T5
· Instruct-GPT
· RETRO
· Chinchilla (and its Scaling Law implications)
We discuss LLM vendors such as @OpenAI, @CohereAI, @AI21Labs
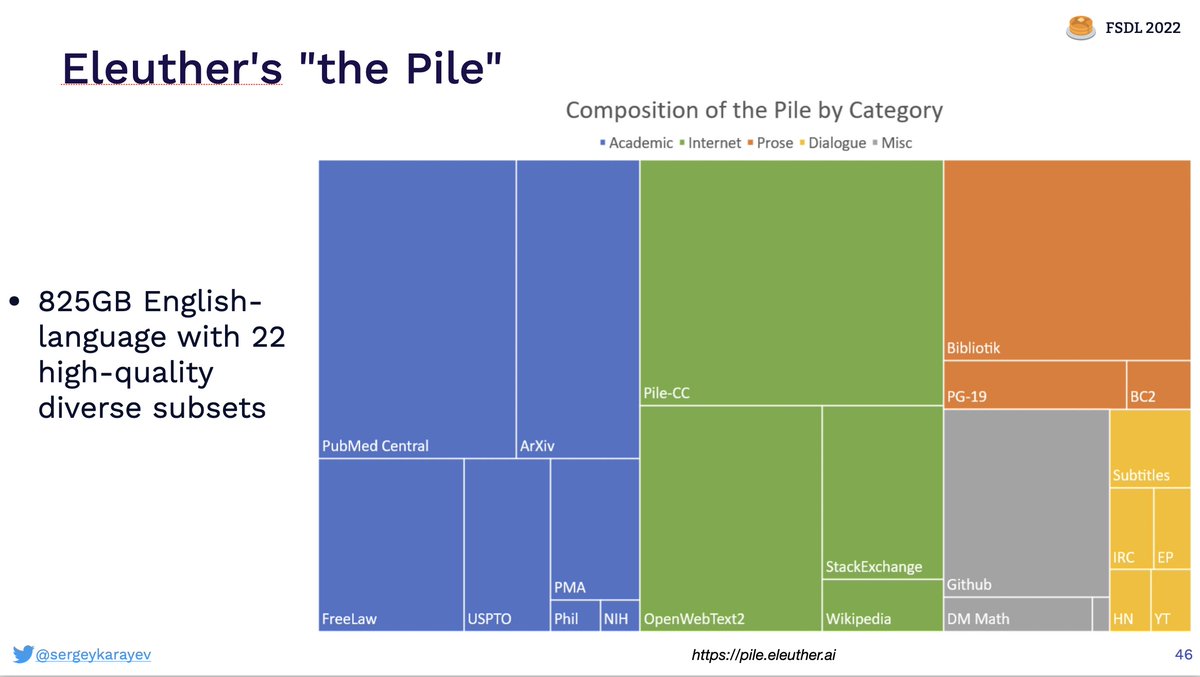
as well as open-source projects such as BLOOM from @BigscienceW, GPT models from EleutherAI, and OPT from @MetaAI
and ways to host inference such as @huggingface.
as well as open-source projects such as BLOOM from @BigscienceW, GPT models from EleutherAI, and OPT from @MetaAI
and ways to host inference such as @huggingface.
Drawing on excellent GPT-3 wrangling by @goodside, @npew, and others, we share some prompt engineering tricks:
· Tokenization effects
· Scratch-pad
· "Let's think step by step"
· Formatting tricks
· Prompt injection attacks
· Tokenization effects
· Scratch-pad
· "Let's think step by step"
· Formatting tricks
· Prompt injection attacks

Code generation is an incredible application of LLMs.
We share results from @DeepMind AlphaCode, @OpenAI Codex and math problem solving work, and thoroughly stan @github copilot.
We also show that good old GPT-3 is perfectly capable of writing code 😎
We share results from @DeepMind AlphaCode, @OpenAI Codex and math problem solving work, and thoroughly stan @github copilot.
We also show that good old GPT-3 is perfectly capable of writing code 😎
https://twitter.com/sergeykarayev/status/1570848080941154304
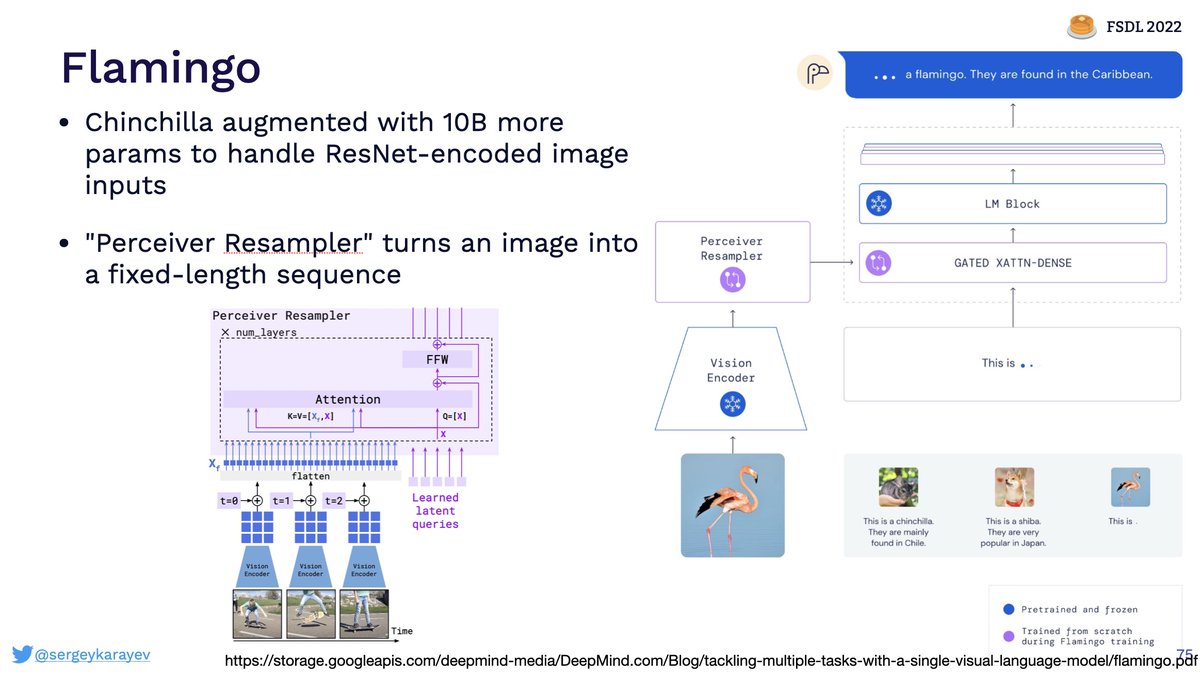
The future is with cross-modal applications of LLMs, and we cover results such as Flamingo from @DeepMind and Socratic Models from @GoogleAI.
Lastly, we talk about the joint embedding of text and images unleashed by CLIP from @OpenAI.
While CLIP alone does not allow going from image to text and vice versa, follow-up work does.
While CLIP alone does not allow going from image to text and vice versa, follow-up work does.

And that's what we cover next: the unCLIP (#dalle2) model, as well as #stablediffusion.
We cover diffusion models, the role of the "prior," and U-Nets for image generation.
We cover diffusion models, the role of the "prior," and U-Nets for image generation.

Open-source datasets and models have kicked off a true explosion of activity in image/video generation. We're excited to see what related projects come out from our synchronous FSDL cohort!

The world of AI has never been more exciting than right now. It feels like we've crested a hill and can see a beautiful new landscape all around. There's a ton to build, and we're excited to help you do it!
Follow us here and follow along at fullstackdeeplearning.com/course/2022
Follow us here and follow along at fullstackdeeplearning.com/course/2022

• • •
Missing some Tweet in this thread? You can try to
force a refresh