
Reading through OpenAI Whisper paper github.com/openai/whisper some notes: 

Idea 1: keep the neural net and the optimization super simple: vanilla Transformer (2017 style) LLM. The innovation is around 1) what the dataset and the training objective is and 2) the I/O schema that allows a single model to multi-task as a speech recognition swiss-army knife.
Idea 2: Scrape a large (680,000hr) audio+transcript dataset, spend much attention+care on heuristics for rejecting/cleaning algorithmically. Some of it is wrong but there is a ton of it. Simple supervised learning from there on, skip auxiliary objectives, self-supervision, etc.
Idea 3: Use special tokens at the input to condition the model for all desired tasks in a single model (language id, speech detection, transcription, translation). Create a "meta-language" of special tokens of a fixed schema that orchestrates the tasks/stages.
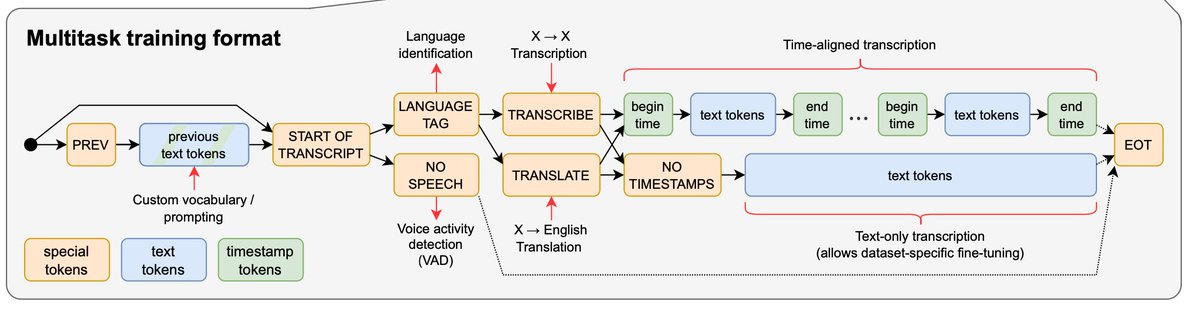
Idea 4: Adopt the GPT train/eval mindset: train on large internet-scraped datasets, then evaluate zero-shot performance on standard evaluation benchmarks (ignoring their training sets entirely!). This approach decreases dataset-specific overfitting and creates more robust models.

Striking story/paragraph from the paper on why this is the correct regime of training:evaluation to focus on. TLDR it is possible to overfit to datasets and their statistics without producing actually robust and generalizable models.

Scaling laws indicate room for additional performance improvements from scaling both 1) the model size and 2) the dataset size, though with some hints of diminishing returns in the case of English specifically, which is most abundant in the training set.

Few more notes:
- multi-task transfer is (-) for small models but (+) for large models! (much optimism for more scaling)
- long-form transcription using hacky decoding heuristics :\
- eval is hard: WER has well-documented problems, requires hacky/extensive text normalization.
- multi-task transfer is (-) for small models but (+) for large models! (much optimism for more scaling)
- long-form transcription using hacky decoding heuristics :\
- eval is hard: WER has well-documented problems, requires hacky/extensive text normalization.
Favorite paragraph of the paper: citing the software packages used throughout the project. Personally excited and hopeful to see this become a lot more common.

TLDR: You can get far with: vanilla Transformer (2017). Scrape a massive (though weakly-labeled) dataset, use simple supervised learning. Multi-task. Eval in zero-shot regime. More perf expected from further model+data scaling. Eval is hard. Some parts (decoding) feel hacky.
• • •
Missing some Tweet in this thread? You can try to
force a refresh





