
1/ It's not the size, it's the skill - now releasing #Neeva's Query Embedding Model!
Our query embedding model beats @openai’s Curie which is orders of magnitude bigger and 100000x more expensive. 🤯
Keep reading to find out how... 📖
Our query embedding model beats @openai’s Curie which is orders of magnitude bigger and 100000x more expensive. 🤯
Keep reading to find out how... 📖

2/ Query understanding is the life blood of #searchengines. Large search engines spent millions of SWE hours building various signals like synonymy, spelling, term weighting, compounds, etc.
We don’t have that luxury. 🙄
Fortunately for us, #LLMs are here to build upon.
We don’t have that luxury. 🙄
Fortunately for us, #LLMs are here to build upon.
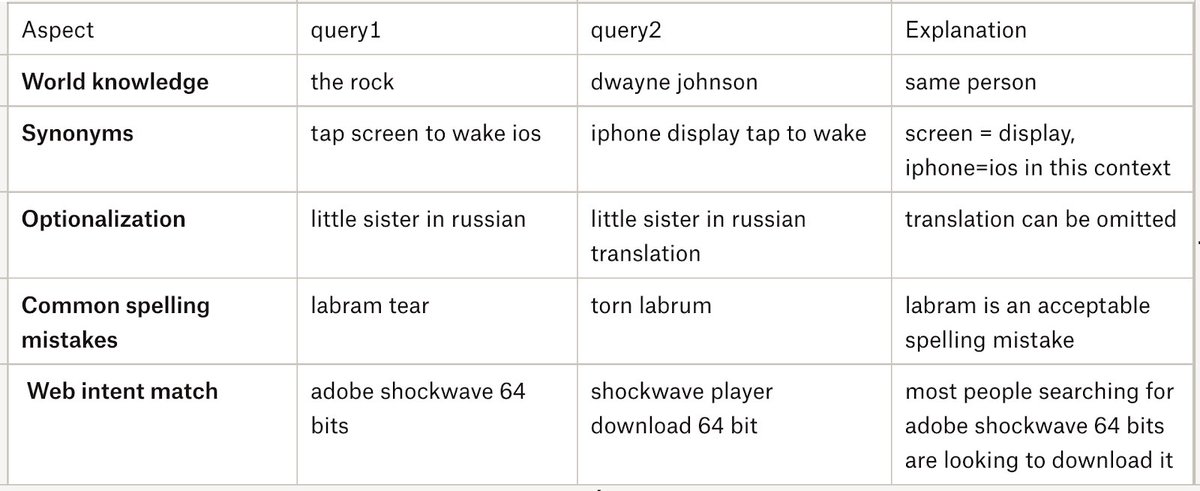
3/ We solve the problem of #query similarity: when 2 user queries looking for the same information on the web.
Why is this useful? Query-click data for web docs = strongest signal for search, QA, etc.; solving query equivalence => smear click signal over lots of user queries
Why is this useful? Query-click data for web docs = strongest signal for search, QA, etc.; solving query equivalence => smear click signal over lots of user queries
4/ Not so obvious? Query equivalence is a suitcase problem. 🛅
Once unpacked, it involves solving many semantic understanding problems.
Most importantly, it involves understanding the myriad ways in which people talk to #searchengines.
Once unpacked, it involves solving many semantic understanding problems.
Most importantly, it involves understanding the myriad ways in which people talk to #searchengines.
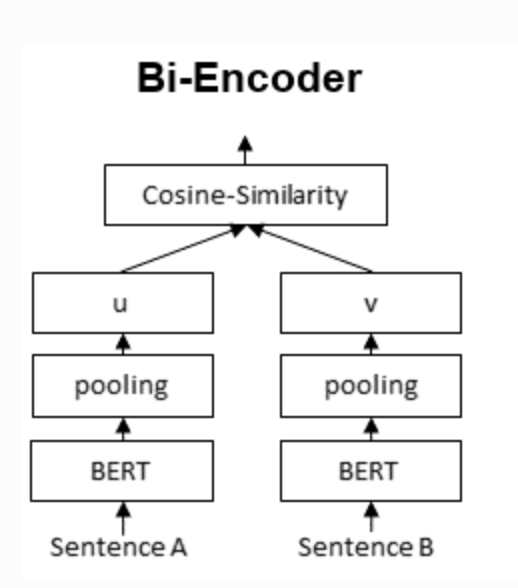
5/ We use a #BERT model to encode queries in a 384 dimension space and use dot products in this space to compute a query equivalence score.
We use sentence BERT (sbert.net) as a starting point.
The main question is how do you train this model? 🤔
We use sentence BERT (sbert.net) as a starting point.
The main question is how do you train this model? 🤔
6/ Answer: We use a trick to generate training data.
We created query pairs that have overlapping results in their top 5 and generated a “soft label” for query pairs similarity = #{overlapping results in top 5}/5 (labels = 0.0, 0.2, 0.4, 0.6, 0.8, 1.0).
We created query pairs that have overlapping results in their top 5 and generated a “soft label” for query pairs similarity = #{overlapping results in top 5}/5 (labels = 0.0, 0.2, 0.4, 0.6, 0.8, 1.0).
7/ Now we have trained a biencoder model, minimizing the l2 distance between soft labels and the cosine similarity of queries.
8/ Mining hard negatives is one of the trickiest and noisiest aspects of similarity/contrastive learning. Our trick lets us get around this by using soft labels based on web result overlap.
⭐ Bonus! Our predicted similarities end up being more calibrated in the [0,1] range.
⭐ Bonus! Our predicted similarities end up being more calibrated in the [0,1] range.
9/ Training this model on our soft label data creates a state of the art model. All by using domain specific knowledge and lots of labeled data.

10/ We are releasing our model (huggingface.co/neeva/query2qu…) and golden set used for eval (huggingface.co/datasets/neeva…) on @huggingface.
Take a look at our latest blog post for more information 👁️ ⤵️ neeva.com/blog/state-of-…
Take a look at our latest blog post for more information 👁️ ⤵️ neeva.com/blog/state-of-…
• • •
Missing some Tweet in this thread? You can try to
force a refresh









