
Attended #TeslaAIDay2022. Engaging yet technical. (streaming link: ) Many memorable moments! 🧵1/ 




- 8 months or so to build humanoids from scratch: Two iterations. Far from Boston Dynamics in locomotion, and far from human bi-dexterous manipulation, but given 8-month window, the results were amazing. Nicely leveraged as much of self-driving pipeline + Dojo compute. 2/



- "generalist" conditional occupancy network: a single "big" network which outputs both voxels and semantics from images. Trained on LARGE dataset from auto labeling. Given where conditional/generative NeRF/OccNets are in academia (arxiv.org/abs/2209.10684), blown away by scale 3/

- lane prediction as image-to-text: used decoder-only Transformer for output "lanes" with a custom language. Best example I've seen of using discrete semantic tokens to describe rich continuous spatial (2D) information. Likely to generalize to 3D and other robot tasks. 4/

- 2 weeks to reconstruct "alterable" San Francisco in simulation: images below are fully generated by Unreal Engine. Everything (road texture, lane semantics, human/cars, weather, etc) is modifiable to generate additional training data. Only took two weeks to input SF. 5/



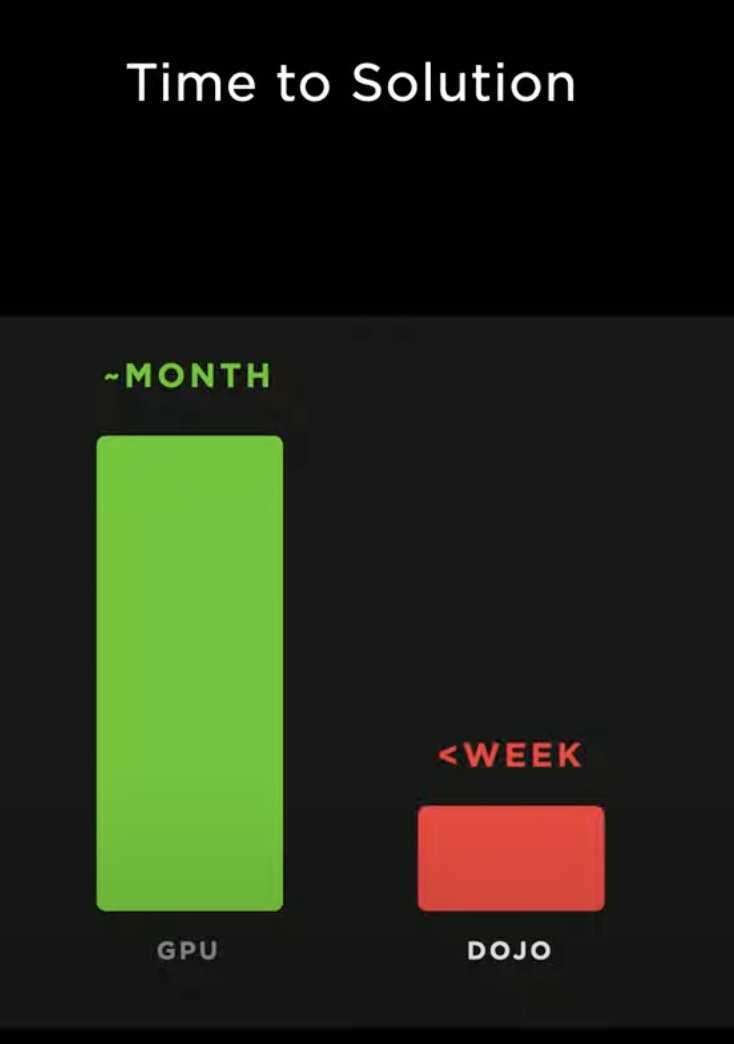
- Dojo (Tesla custom compute hardware): 50% of total Tesla compute is on auto labeling + OccNet. Dojo beats A100 GPUs with various problem-specific optimizations. PyTorch supported. Runs #stablediffusion. Probably the most exciting result of the night. 6/



- Elon said "Software 2.0" 7/
https://twitter.com/karpathy/status/1576044650938236928
• • •
Missing some Tweet in this thread? You can try to
force a refresh










