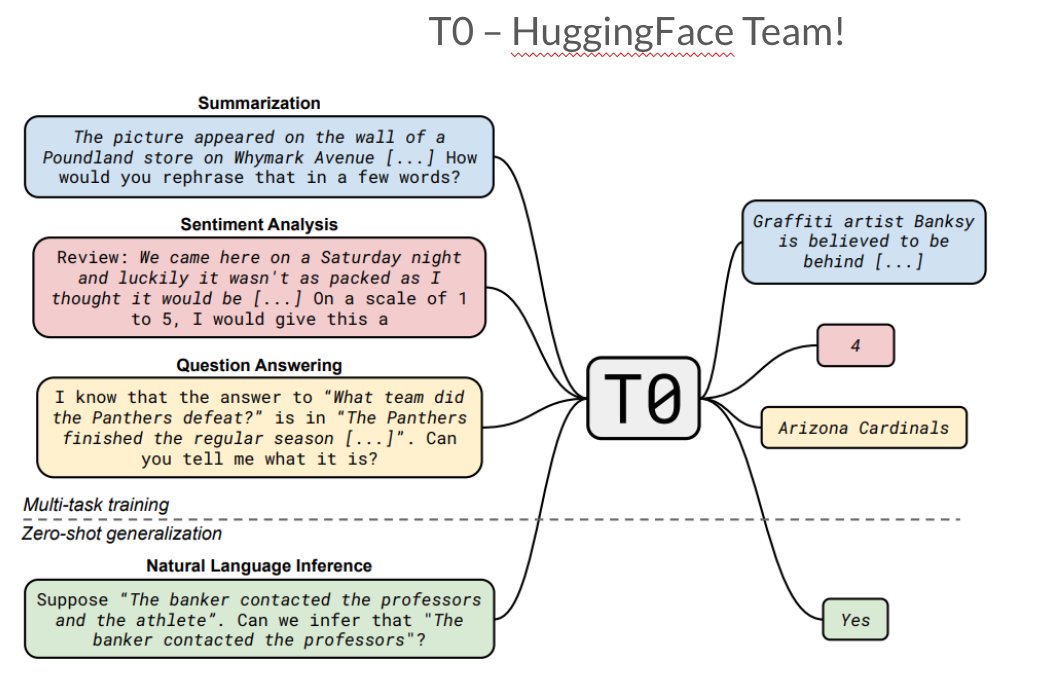
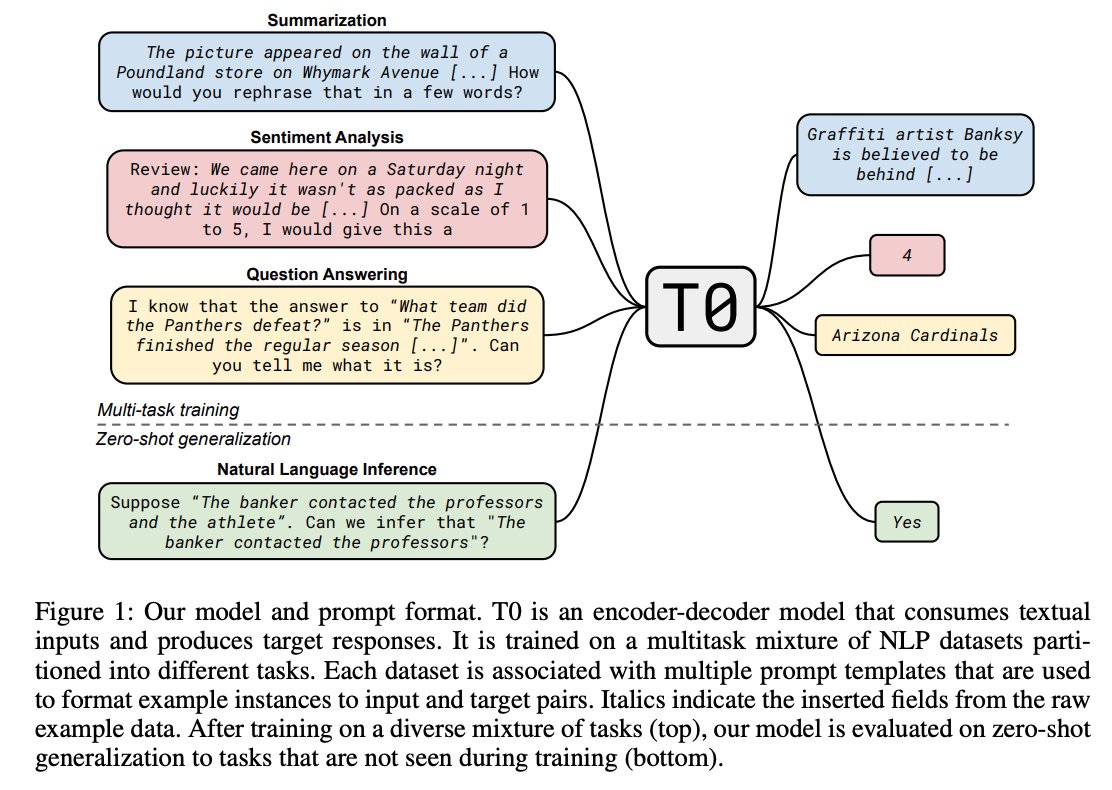
📢 A 🧵 on the Trends in NLP Datasets.
What’s changed since SQuAD was all the rage in 2016? A: A LOT. 🔭
1. Generic ➡️ Niche Tasks
2. Task-specific Training+Eval ➡️ Eval Only
3. Dataset ➡️ Benchmark ➡️ Massive Collections
4. Datasets ➡️ Diagnostics
1/
What’s changed since SQuAD was all the rage in 2016? A: A LOT. 🔭
1. Generic ➡️ Niche Tasks
2. Task-specific Training+Eval ➡️ Eval Only
3. Dataset ➡️ Benchmark ➡️ Massive Collections
4. Datasets ➡️ Diagnostics
1/

What started as a trickle became an explosion of NLP datasets over the last few years.
@sebastian ruder used to track all NLP sets on his website: nlpprogress.com. It’s no longer possible to keep up-to-date.
2/
@sebastian ruder used to track all NLP sets on his website: nlpprogress.com. It’s no longer possible to keep up-to-date.
2/
🌟 Trend 1 🌟 Generic dataset are replaced with more niche datasets.
⏳ Before: datasets released for general tasks.
⌛️ Now: We see tasks targeting hyper-specific abilities.
Exs:
3/
⏳ Before: datasets released for general tasks.
⌛️ Now: We see tasks targeting hyper-specific abilities.
Exs:
3/
For general QA ➡️ SQuAD
➕ Retrieval ➡️ Open SQuAD
➕Other domains ➡️ NewsQA, BioASQ, TriviaQA …
➕Multilingual ➡️ MLQA, XQuAD, TyDiQA, XORQA, MKQA…
➕Adversarial / Numerical / Causal / Social / Physical Reasoning ➡️ Adversarial SQuAD, DROP, ROPES, SocialIQA, PIQA,…
Etc.
4/
➕ Retrieval ➡️ Open SQuAD
➕Other domains ➡️ NewsQA, BioASQ, TriviaQA …
➕Multilingual ➡️ MLQA, XQuAD, TyDiQA, XORQA, MKQA…
➕Adversarial / Numerical / Causal / Social / Physical Reasoning ➡️ Adversarial SQuAD, DROP, ROPES, SocialIQA, PIQA,…
Etc.
4/

See work by @annargrs @nlpmattg @IAugenstein w/ detail on the QA dataset explosion.
📜: dl.acm.org/doi/10.1145/35…
5/
📜: dl.acm.org/doi/10.1145/35…
https://twitter.com/annargrs/status/1576947545276026880?s=20&t=BYEPjMVhaGxPLLEIFolOGQ
5/
🌟 Trend 2 🌟
⏳ Before: It was important to release a Training set w/ an eval task.
Why use it if you need to find/prep your own train set?
⌛️Now:
1. There are Training sets for *almost* everything
2. LLMs are expected to generalize to anything with an instruction
6/
⏳ Before: It was important to release a Training set w/ an eval task.
Why use it if you need to find/prep your own train set?
⌛️Now:
1. There are Training sets for *almost* everything
2. LLMs are expected to generalize to anything with an instruction
6/
🌟 Trend 3 🌟
Many tasks can be packaged into benchmarks, representing larger evaluation concepts.
Exs:
➕GLUE and SuperGLUE ➡️ General English NLU
➕XGLUE and XTREME ➡️ General Multilingual NLU
➕KILT ➡️ Knowledge intensive NLU
7/
Many tasks can be packaged into benchmarks, representing larger evaluation concepts.
Exs:
➕GLUE and SuperGLUE ➡️ General English NLU
➕XGLUE and XTREME ➡️ General Multilingual NLU
➕KILT ➡️ Knowledge intensive NLU
7/



But now LLMs want to evaluate on 100+ tasks. (Because w/ zero- or few-shot they easily can!)
Can one eval suite answer:
(A)Where did we get SOTA?
(B) Are there emergent properties?
(C) What are the remaining weaknesses?
8/
Can one eval suite answer:
(A)Where did we get SOTA?
(B) Are there emergent properties?
(C) What are the remaining weaknesses?
8/
To answer these Qs, benchmarks were cannibalized and collated into 📚massive collections📚, spanning many loosely grouped skills.
Exs:
➕FLAN, T0, ExT5, MetaICL ➡️ 100s tasks each
➕BigBench ➡️ 100+ tasks
➕Natural Instructions ➡️ 1600+ tasks
➕🤗 Datasets ➡️ 1000+ tasks
9/
Exs:
➕FLAN, T0, ExT5, MetaICL ➡️ 100s tasks each
➕BigBench ➡️ 100+ tasks
➕Natural Instructions ➡️ 1600+ tasks
➕🤗 Datasets ➡️ 1000+ tasks
9/


🌟 Trend 4 🌟
Analysis and Diagnostics are gradually being elevated on par with Eval Datasets.
This is important since Evaluations often drive research community incentives.
10/
Analysis and Diagnostics are gradually being elevated on par with Eval Datasets.
This is important since Evaluations often drive research community incentives.
10/
Exs:
➕Heuristic Analysis (HANS) by McCoy, Pavlick, @tallinzen
➕Behavioral Testing Checklist by @marcotcr @tongshuangwu
➕ ANLIzying the Adversarial NLI Dataset by @adinamwilliams, @TristanThrush, @douwekiela
11/
➕Heuristic Analysis (HANS) by McCoy, Pavlick, @tallinzen
➕Behavioral Testing Checklist by @marcotcr @tongshuangwu
➕ ANLIzying the Adversarial NLI Dataset by @adinamwilliams, @TristanThrush, @douwekiela
11/
The panel at @DADCworkshop #NAACL2022 was full of interesting future ideas for dataset development:
➕Expiration dates on training sets
➕Interactive datasets w/ human-in-the-loop
➕Refreshing datasets adversarially w/ man/machine
🌐: dadcworkshop.github.io
12/
➕Expiration dates on training sets
➕Interactive datasets w/ human-in-the-loop
➕Refreshing datasets adversarially w/ man/machine
🌐: dadcworkshop.github.io
12/
Thank you for reading!
And thanks to @_jasonwei, @albertwebson, @emilyrreif for feedback on this 🧵!
NB: I couldn’t cite all the great exs of these trends in a short thread, but please comment if I missed any great ones, you agree, or disagree! :)
/🧵
And thanks to @_jasonwei, @albertwebson, @emilyrreif for feedback on this 🧵!
NB: I couldn’t cite all the great exs of these trends in a short thread, but please comment if I missed any great ones, you agree, or disagree! :)
/🧵
• • •
Missing some Tweet in this thread? You can try to
force a refresh